嵌入式软件开发中,性能优化是一个永恒的话题。当你辛苦优化了一段代码,却难以直观判断其速度是否真正提升;当你的控制周期设定为1kHz,却无法精确得知算法执行耗时,究竟是稳定的200微秒还是已经濒临超时的900微秒?
在PC环境中,我们拥有Chrome DevTools、各类Profiler等成熟的性能分析工具,可以一键获得详尽数据。然而,在资源受限、通常无操作系统的微控制器(MCU)上,情况则大不相同,有时连简单的printf输出都可能干扰系统的精确时序。
本文将系统地介绍七种嵌入式代码性能测量与分析方法,从最基础直接的GPIO翻转,逐步深入到内核级的指令追踪,助你构建清晰的性能分析能力体系。
第一重:GPIO + 示波器/逻辑分析仪
最直观的物理测量法
原理:在需要测量的代码段起始和结束位置,分别控制一个GPIO引脚输出高电平和低电平,然后使用示波器或逻辑分析仪捕获该引脚的波形,通过测量脉冲宽度即可得到代码执行时间。
#define MEASURE_PIN_HIGH() HAL_GPIO_WritePin(GPIOA, GPIO_PIN_0, GPIO_PIN_SET)
#define MEASURE_PIN_LOW() HAL_GPIO_WritePin(GPIOA, GPIO_PIN_0, GPIO_PIN_RESET)
// 使用示例
MEASURE_PIN_HIGH();
YourAlgorithm(); // 待测代码
MEASURE_PIN_LOW();
适用场景:
- 验证多路信号间的时序对齐关系。
- 观察中断响应延迟。
- 需要从物理层面直观查看实际波形时。
优点:结果真实可靠,误差极小(仅包含GPIO翻转操作本身的几个时钟周期),所见即所得。
缺点:依赖外部硬件(示波器或逻辑分析仪),需要占用额外的GPIO引脚,难以实现自动化数据采集与统计。
进阶:使用逻辑分析仪可以同时捕获多路信号,并自动计算时间差,效率更高。
第二重:CPU周期计数器 (DWT)
纳秒级精度的片上测量
原理:利用ARM Cortex-M内核自带的调试观察点与追踪(DWT)单元中的DWT_CYCCNT计数器。该计数器与CPU主频同步,每个时钟周期自增一次,从而实现极高精度的计时。
// 初始化DWT计数器
void DWT_Init(void) {
CoreDebug->DEMCR |= CoreDebug_DEMCR_TRCENA_Msk; // 使能DWT
DWT->CYCCNT = 0; // 清零计数器
DWT->CTRL |= DWT_CTRL_CYCCNTENA_Msk; // 启动计数
}
// 获取当前周期计数值
#define DWT_GetCycles() (DWT->CYCCNT)
// 使用示例
uint32_t start = DWT_GetCycles();
YourAlgorithm();
uint32_t end = DWT_GetCycles();
float time_us = (end - start) / (SystemCoreClock / 1000000.0f); // 转换为微秒
精度:高达1个CPU时钟周期。例如在168MHz的STM32F4上,理论精度可达约6纳秒。
适用场景:
- 测量短小精悍的算法或函数。
- 测量中断服务程序(ISR)的执行时间。
- 需要进行精确到时钟周期的性能对比。
注意事项:
- DWT属于调试资源,部分芯片可能需要额外的解锁操作。
- 该计数器为32位,在高主频下会周期性溢出(如168MHz下约25秒溢出一次),测量长时间任务时需注意处理。
第三重:片上通用定时器
兼顾精度与量程的工程选择
痛点:DWT计数器易溢出,且计时与CPU频率绑定,在测量长时间任务或需要稳定时间基准时不够方便。
方案:配置一个片上通用定时器为自由运行模式(Free Run),通过预分频器设置,使其计数频率为1MHz(即1个tick对应1微秒),从而实现大范围、微秒级精度的测量。
// 以TIM2为例,配置为1us分辨率的自由运行计数器
void Timer_Init(void) {
__HAL_RCC_TIM2_CLK_ENABLE();
TIM2->PSC = (SystemCoreClock / 1000000) - 1; // 设置计数频率为1MHz
TIM2->ARR = 0xFFFFFFFF; // 自动重载值为最大值
TIM2->CR1 |= TIM_CR1_CEN; // 使能计数器
}
#define GetTimeUs() (TIM2->CNT)
// 使用
uint32_t t1 = GetTimeUs();
LongTask();
uint32_t t2 = GetTimeUs();
printf("耗时: %lu us\n", t2 - t1);
优势:
- 时间基准独立于CPU频率,更稳定。
- 1微秒精度足以满足绝大多数应用场景的需求。
- 32位计数器在1MHz下可连续测量约71分钟,量程大。
第四重:RTOS运行时统计
系统级的CPU负载洞察
痛点:单个函数执行快慢只是局部问题,更需要关注的是在复杂的RTOS多任务系统中,究竟是哪个任务长期霸占CPU资源。
方案:利用RTOS(如FreeRTOS)提供的运行时统计功能vTaskGetRunTimeStats()。
// 在FreeRTOSConfig.h中启用配置
#define configGENERATE_RUN_TIME_STATS 1
#define configUSE_STATS_FORMATTING_FUNCTIONS 1
#define portCONFIGURE_TIMER_FOR_RUN_TIME_STATS() ConfigureTimerForRunTimeStats()
#define portGET_RUN_TIME_COUNTER_VALUE() GetRuntimeCounterValue()
// 使用示例
char statsBuffer[512];
vTaskGetRunTimeStats(statsBuffer);
printf("%s", statsBuffer);
输出示例:
任务名称 运行时间(ticks) 占用率
------------------------------------------
ctrlTask 3500000 35%
commTask 2000000 20%
IDLE 4500000 45%
原理:RTOS内核在每次任务切换时记录高精度时间戳,通过累加计算每个任务获得CPU执行权的总时间,进而计算出占用百分比。
适用场景:
- 系统级的性能分析与瓶颈定位。
- 找出CPU占用率过高的“元凶”任务。
- 验证任务优先级划分与调度设计的合理性。
第五重:Segger SystemView
可视化的系统行为追踪
传统方法的局限:GPIO方法只能观察孤立的“点”,RTOS统计提供的是宏观的“面”。若想了解“在这1毫秒内,我的任务被中断打断了几次?每次中断处理了多久?”这类动态交互细节,传统工具就显得力不从心。
方案:使用Segger SystemView这类可视化实时追踪工具。
原理:基于J-Link调试器的RTT(Real-Time Transfer)技术,在目标芯片内存中开辟一小块环形缓冲区,以极低开销实时记录诸如中断进入/退出、任务切换、用户自定义事件等。
核心功能:
- 可视化时间线(甘特图):清晰展示所有任务、中断的执行时序与相互抢占关系。
- 死锁与资源竞争定位:直观显示哪个低优先级任务持有了高优先级任务等待的锁(信号量、互斥量)。
- 中断分析:统计每个中断源的触发频率、执行时间、最坏情况延迟等。
// SystemView集成示例(以FreeRTOS为例)
#include "SEGGER_SYSVIEW.h"
void main(void) {
SEGGER_SYSVIEW_Conf(); // 配置
SEGGER_SYSVIEW_Start(); // 开始记录
// ... 初始化并启动RTOS
vTaskStartScheduler();
}
优势:
- 近乎零侵入:通过调试接口传输数据,不占用宝贵的串口等外设资源。
- 实时流式记录:可持续监控系统运行,而非一次性快照。
- 免费版功能强大:对于大多数嵌入式开发需求已完全足够。
第六重:PC采样(PC Sampling)
零代码侵入的热点发现
痛点:面对一个数十万行代码的遗留项目,不清楚性能热点具体分布在何处,又不想在成千上万个函数中手动插入测量代码。
原理:利用支持Trace功能的高级调试器(如J-Link PRO),以固定时间间隔(例如每1毫秒)中断CPU一次,并“偷看”当前程序计数器(PC)寄存器指向哪个函数或地址。
结果:集成开发环境(IDE)会收集大量采样点,并生成统计报告或火焰图。例如报告显示:“在10000次采样中,有超过30%的采样点落在memcpy函数内”,从而快速定位到潜在的性能瓶颈函数。
操作流程(以Keil MDK为例):
- 使用J-Link/ULINKpro等调试器连接目标板。
- 进入Debug模式,打开
Debug -> Performance Analyzer窗口。
- 全速运行程序,分析器自动收集数据并生成函数耗时占比图。
优势:
- 完全无需修改代码:真正的非侵入式分析。
- 快速摸底:非常适合在项目初期或面对陌生代码库时,快速定位大致的性能热点区域。
局限:
- 统计性误差:基于采样,可能遗漏执行时间极短的函数。
- 硬件依赖:需要调试器和芯片支持SWO或并行Trace输出接口。
第七重:性能监控单元(PMU)分析
探究“测不准”的微观本质
深层问题:为什么使用相同的DWT计数器测量同一个Calc()函数,第一次运行耗时10微秒,第二次却仅需2微秒?
底层揭秘:在现代高性能MCU(如Cortex-M7/M33, Cortex-A系列)中,缓存(Cache)、分支预测、流水线等微架构特性会极大影响代码执行时间。同一段代码,因缓存命中与否,性能可能相差数倍。

终极工具:PMU
// Cortex-M7 PMU 配置示例
void PMU_Init(void) {
// 使能PMU
ARM_PMU_Enable();
// 配置计数器0:统计指令缓存未命中次数
ARM_PMU_Set_EVTYPER(0, ARM_PMU_ICACHE_MISS);
// 配置计数器1:统计数据缓存未命中次数
ARM_PMU_Set_EVTYPER(1, ARM_PMU_DCACHE_MISS);
// 使能这两个计数器
ARM_PMU_CNTR_Enable(0x03);
}
// 读取结果
uint32_t icache_miss = ARM_PMU_Get_EVCNTR(0);
uint32_t dcache_miss = ARM_PMU_Get_EVCNTR(1);
PMU能揭示的关键指标:
- CPI (Cycles Per Instruction):理想值为1,实际可能为3-5,值越高说明流水线停顿越严重。
- 缓存未命中次数:精准定位因内存访问模式不佳导致的性能瓶颈。
- 分支预测失败次数:评估条件判断逻辑对性能的影响,指导优化分支结构。
掌握PMU,意味着你不仅能知道代码“慢”,更能深入理解其“为什么慢”。
番外:警惕编译器的“优化”
一个常见的陷阱:
volatile uint32_t start = DWT->CYCCNT;
for(int i = 0; i < 1000; i++); // 意图耗时的空循环
volatile uint32_t end = DWT->CYCCNT;
printf("耗时: %lu cycles\n", end - start); // 输出结果可能是 0 !
原因:编译器在-O2或更高级别优化下,判断出该空循环无任何副作用,直接将其从生成的机器码中删除。
对策:
// 方法1:循环变量使用volatile修饰
for(volatile int i = 0; i < 1000; i++);
// 方法2:在循环体内插入编译器屏障或空指令
for(int i = 0; i < 1000; i++) {
__NOP(); // 或 __ISB()
}
// 方法3:禁用特定函数的优化
__attribute__((optimize("O0")))
void FunctionToMeasure(void) {
// ...
}
核心要点:在进行任何形式的性能测量时,务必确认你的测量代码本身没有被编译器“过度优化”。
总结:构建你的性能分析工具箱
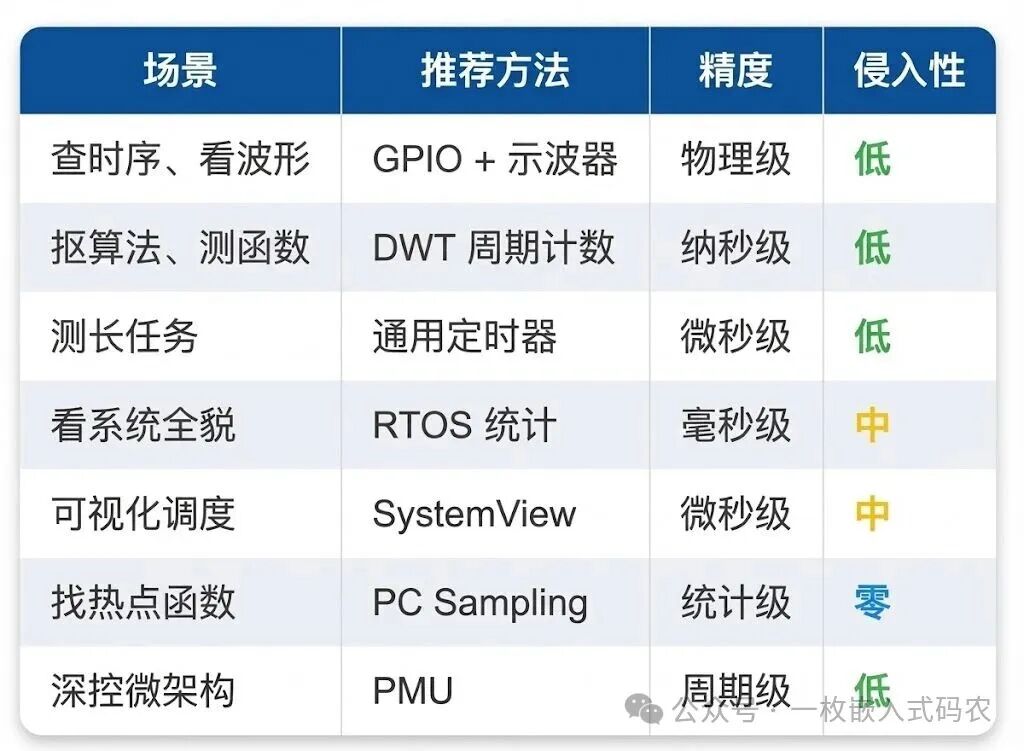
实践建议:
- 入门与基础:熟练掌握GPIO测量法和DWT周期计数器,这足以解决80%的日常性能测量需求。
- 系统与交互分析:在基于RTOS的项目中,务必结合RTOS运行时统计和SystemView等工具,理解任务间的交互与调度行为。
- 深入与本质:面对复杂性能问题时,善用PC采样进行热点定位,并尝试使用PMU等底层硬件分析工具探究其微观原因。
优秀的嵌入式工程师不应只依赖单一工具。将这七种方法视为你工具箱中的“瑞士军刀”,根据不同场景灵活选用。当你能娴熟运用这些“武器”时,代码的性能表现将不再是黑盒,任何性能瓶颈都将无所遁形。
 发表于 2025-12-24 19:52:58
|
查看: 201|
回复: 0
发表于 2025-12-24 19:52:58
|
查看: 201|
回复: 0
