
在分布式系统架构中,确保数据高可用性是核心原则,常类比为“不把鸡蛋放在一个篮子里”。对于广泛使用的内存数据库Redis,单节点部署存在单点故障风险,因此多节点部署的主从模式成为提升可靠性的标准实践。在Redis 2.8版本之前,主节点故障需管理员手动干预;而2.8版本引入哨兵(Sentinel)模式后,实现了自动故障转移,将服务中断从“手动”恢复升级为“自动”处理,显著提升了系统可用性。
主从与哨兵部署策略
主从模式和哨兵模式既可复用部署,也可完全独立。在生产环境中,建议将哨兵节点独立部署,通常使用3个或5个奇数数量的Sentinel节点(以避免脑裂问题),并与主从节点保持网络互通但物理隔离。这种设计实现了监控者与被监控者的解耦,确保故障检测的客观性和系统稳定性。
Redis哨兵集群的共识机制
哨兵模式的核心目标是实现“自动故障转移”,这依赖于两个关键共识过程:首先是确定主节点是否真实故障(故障检测共识),其次是由谁执行故障转移(领导者选举共识)。
故障检测共识
单个哨兵节点的主观判断(主观下线)不足以确认主节点故障,因为可能是网络抖动或哨兵自身问题。为此,该哨兵会向其他哨兵发送 SENTINEL is-master-down-by-addr 命令,询问他们对主节点状态的看法。通过收集回复并统计同意下线的票数,若达到配置的 quorum 值(法定人数),则主节点被标记为客观下线(ODOWN)。这本质上是一个分布式系统中的二元共识问题,确保了故障判定的可靠性。
领导者选举共识
当主节点被确认为客观下线后,需选举一个领头哨兵(Leader Sentinel)来执行故障转移,避免多个哨兵同时行动导致混乱。这一过程借鉴了Raft算法的领导者选举思想,但针对Redis场景进行了简化。下表对比了Raft算法与Redis哨兵选举的关键特性:
| 特性 |
Raft算法 |
Redis哨兵选举 |
| 节点角色 |
Leader、Follower、Candidate三种固定角色 |
所有哨兵平时对等,仅在选举时临时成为Candidate |
| 选举触发 |
Follower选举超时自动触发 |
发现主节点客观下线后触发 |
| 任期机制 |
严格的任期(Term)递增 |
使用选举纪元(epoch)概念,实现更简单 |
| 日志复制 |
核心功能,用于状态机复制 |
不涉及日志复制,只用于选举决策 |
| 投票规则 |
严格的一任期一票,先到先得 |
类似,但增加了epoch检查 |
| 应用场景 |
通用分布式一致性(如etcd、Consul) |
专用于Redis故障转移的领导者选举 |
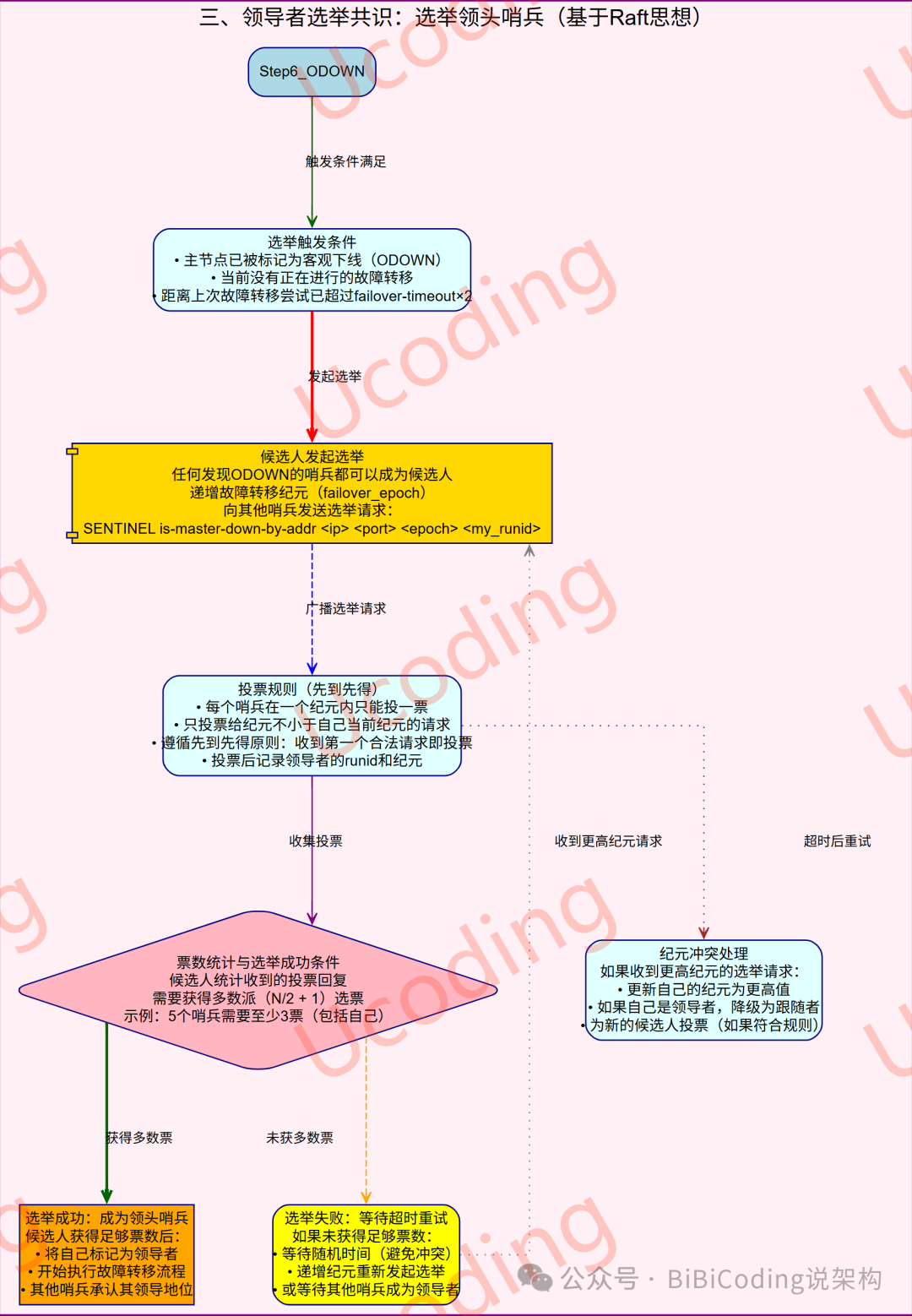

通过上述共识机制,Redis哨兵模式能够高效、自动地处理主节点故障,保障系统高可用性。在实际部署中,合理配置哨兵节点和参数,可进一步优化故障转移的效率和稳定性。 |  发表于 2025-12-24 21:32:33
|
查看: 290|
回复: 0
发表于 2025-12-24 21:32:33
|
查看: 290|
回复: 0
