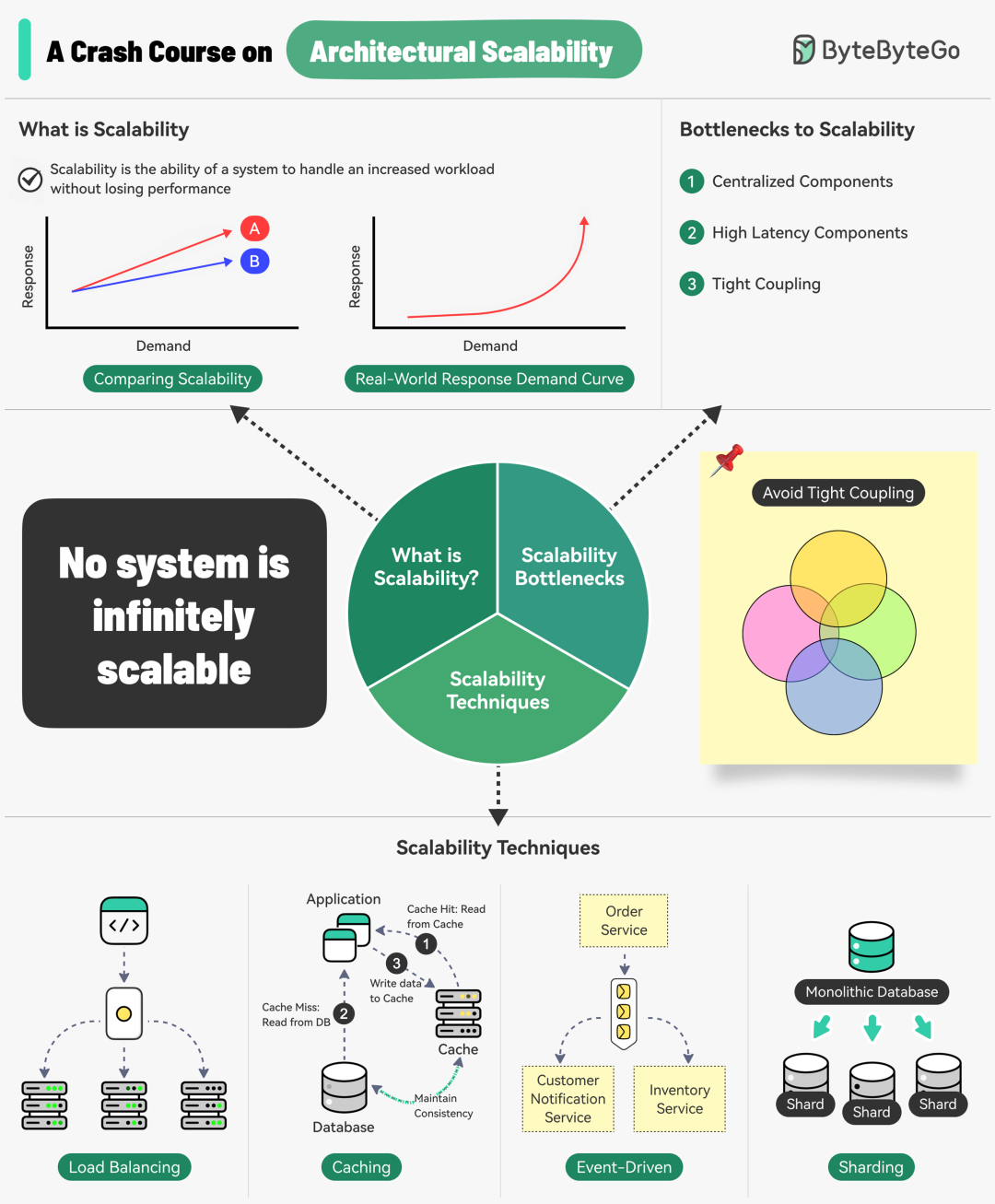
在构建现代软件系统时,可扩展性(Scalability)无疑是架构设计的核心目标之一。它衡量的是系统在面对不断增长的工作负载时,能否持续保持性能不下降。这不仅是技术挑战,更是保障业务长期发展的关键。本文将带你快速理解可扩展性的核心概念,并梳理出实用的设计原则与技术实践。
什么是可扩展性?
我们通常可以从两个维度来理解可扩展性:
从性能角度看:它指的是系统处理增加负载时,不损失性能的能力。
从成本角度看:它强调通过可重复且经济有效的策略来应对工作负载的增长。
实际上,第二个角度更为关键。试想,如果一个系统的扩展成本随着规模呈指数级增长,那么它最终将变得无法负担。因此,优秀的扩展性追求的是线性甚至亚线性的成本增长。
三大常见的扩展性瓶颈
在设计之初就识别并规避这些瓶颈,能让你少走很多弯路。
1. 集中式组件(Centralized Components)
任何单一节点都可能成为系统的性能瓶颈和致命故障点。
典型例子:
- 单一数据库服务器
- 单个消息队列实例
- 集中式配置中心
解决思路:采用分布式架构,从根本上消除单点故障。将集中式的组件进行拆分和复制,是实现扩展的第一步。
2. 高延迟组件(High Latency Components)
某些执行耗时操作的组件会成为系统链条中的“短板”,拖慢整体响应。
典型例子:
- 同步调用外部 API
- 未经优化的复杂数据库查询
- 处理大数据量的文件操作
解决思路:引入异步处理、利用缓存减少重复计算、优化核心算法或查询语句,目标是减少或隔离高延迟操作的影响。
3. 紧耦合(Tight Coupling)
当组件间依赖关系过强时,它们便难以被独立地部署、升级和扩展。一处变更,处处受限。
典型例子:
- 服务间直接进行同步调用,没有缓冲层
- 多个服务直接共享和操作同一数据库表
- 硬编码的服务依赖关系
解决思路:推动系统解耦,例如通过消息队列进行异步通信、定义清晰的 API 接口契约、采用依赖注入等模式,降低组件间的直接依赖。
可扩展架构的核心设计原则
掌握这些原则,能帮助你在设计时做出更正确的选择。
无状态(Statelessness)
无状态的服务是水平扩展的理想选择。任何请求都可以被路由到集群中的任意一个实例进行处理,无需关心会话粘滞问题。
实践建议:
- 将会话数据存储在外部的 Redis 等缓存中,而非应用服务器的本地内存。
- 用户上传的文件直接存入对象存储(如 S3、OSS),不在应用服务器本地留存。
- 将配置信息外部化(如放入配置中心或环境变量),避免硬编码。
松耦合(Loose Coupling)
组件之间通过明确定义的接口或契约进行交互,彼此隐藏内部实现细节。这样,单个组件的内部修改或扩展不会波及其他组件。
实践建议:
- 服务间采用消息队列(如 Kafka、RabbitMQ)进行通信,实现生产与消费的解耦。
- 对公开的 API 进行版本化管理,保证向后兼容。
- 使用依赖注入等模式,避免在代码中直接实例化依赖对象。
异步处理(Asynchronous Processing)
将耗时的、非核心的操作从主请求链路中剥离,转为后台异步执行,可以极大提升系统的吞吐量和用户体验。
实践建议:
- 用户注册成功后,发送欢迎邮件的任务可以放入队列异步执行。
- 图片上传后,缩略图生成、水印添加等处理放入后台任务队列。
- 复杂的报表或数据导出请求,提交后立即返回,处理完成后通过消息或通知告知用户。
提升扩展性的四大实用技术
理论需要实践落地,以下是几种经过验证的扩展性技术。
1. 负载均衡(Load Balancing)
将涌入的请求流量智能地分发到后端多个服务器实例上,避免单一节点过载,是实现水平扩展的基础。
常用方案:
- 使用 Nginx、HAProxy 等软件进行七层(应用层)负载均衡。
- 直接利用云服务商提供的托管负载均衡器,如 AWS ALB、阿里云 SLB。
- 简单的 DNS 轮询,适用于对会话保持要求不高的场景。
2. 缓存(Caching)
将高频访问的数据暂存在速度更快的存储介质(通常是内存)中,能显著降低数据库压力和重复计算开销。
常见的缓存层级:
- 客户端/浏览器缓存:利用 CDN、HTTP 缓存头、本地存储加速静态资源和接口数据访问。
- 应用层缓存:使用 Redis、Memcached 等内存数据库缓存业务数据。
- 数据库缓存:如 MySQL 的 Query Cache、InnoDB Buffer Pool,属于数据库内部的优化机制。
3. 事件驱动处理(Event-Driven Processing)
基于消息队列构建事件驱动的架构,能彻底解耦服务,允许生产者和消费者按照各自节奏独立扩展。
常用消息队列:
- Kafka:擅长高吞吐量的日志处理、流数据处理场景。
- RabbitMQ:功能丰富的企业级消息队列,支持多种消息协议。
- AWS SQS / 云消息队列:免运维的托管服务,简化了队列的管理工作。
4. 分片(Sharding)
当单一数据库节点成为瓶颈时,将大数据集水平拆分并分布到多个物理节点上,是解决数据层面扩展性的终极手段之一。
常见的分片策略:
- 范围分片:按某个键的范围划分,如用户ID从1到10000存入分片A。
- 哈希分片:对分片键进行哈希运算后取模,能保证数据相对均匀分布。
- 时间分片:按时间维度划分,常用于日志、监控数据,如按月分表。
扩展策略:垂直扩展 vs. 水平扩展
垂直扩展:也被称为 Scale Up,即提升单个服务器的能力(如增加CPU核心、内存、使用更快的SSD)。
- 优点:实施简单,通常无需修改应用架构。
- 缺点:存在物理上限,且高性能硬件成本高昂,性价比曲线会迅速恶化。
水平扩展:也被称为 Scale Out,即通过增加更多的服务器实例来分摊负载。
- 优点:理论上可以实现近乎无限的扩展能力,且通常使用廉价硬件,成本增长更线性。
- 缺点:需要应用架构本身支持分布式,设计复杂度更高。
现代云原生系统普遍倾向于水平扩展策略,并借助自动化运维平台(如 Kubernetes 的 HPA)实现弹性伸缩,以从容应对流量的波峰波谷。
架构设计自查清单
在设计或评审一个系统的架构时,你可以用下面这些问题来检验其扩展潜力:
- 系统中是否存在单点组件?能否被消除或集群化?
- 关键服务是否做到了无状态?能否轻易地进行水平扩展?
- 组件间的耦合度如何?能否做到独立部署和独立扩展?
- 系统中是否存在慢操作?它们是否已被异步化处理?
- 是否合理地使用了缓存?缓存策略(过期、更新)是否得当?
- 数据层是否存在瓶颈?未来是否需要考虑分库分表?
- 消息队列的容量和吞吐量是否能应对预期的峰值流量?
总结
可扩展性绝非系统上线后才考虑的“补丁”,而是需要从架构设计之初就深入思考并贯穿始终的核心目标。
关键要点回顾:
- 警惕并避免集中式组件和紧耦合设计。
- 坚定不移地推动服务无状态化。
- 善用缓存和异步处理来优化性能瓶颈。
- 优先选择水平扩展作为长期发展的技术路线。
记住,理想的扩展性追求的是线性关系——当你的用户量增长10倍时,系统成本和资源消耗最好也只增长10倍左右,而非100倍。不断打磨你的架构设计,正是为了无限逼近这个目标。如果你对系统设计、分布式架构有更多兴趣,欢迎在云栈社区与其他开发者一起交流探讨。
 发表于 2026-2-24 05:31:53
|
查看: 263|
回复: 0
发表于 2026-2-24 05:31:53
|
查看: 263|
回复: 0
