对于普通人而言,音视频算得上是最“接地气”的技术——不需要具备专业背景,就能直观地感受到技术能力高低带来的体验差异。比如,观看体育直播时,模糊的画面、明显的延迟或卡顿,都会直接影响观看体验。
在移动互联网时代,用户对音视频的核心诉求是“看得清、看得爽”。火山引擎视频云正是凭借这一时期的积累脱颖而出,它将抖音在亿级日活场景下长期打磨的能力封装成解决方案,向业界输出“抖音同款”的音视频能力,重点攻克了画质、时延、稳定性和大规模分发等难题。
进入AI时代,人们对音视频能力的要求跃升至新的高度:视频不仅要能“看”,还要能“听”、能“理解”,甚至能与人“对话”。例如,在教育场景中,用户期待AI老师能实时对话并因材施教;在娱乐场景,则希望AI陪伴助手更具个性化与情感。什么样的视频云才能支撑这样的未来想象?在近期火山引擎原动力大会上,其视频云给出了答案:从提供“抖音同款”的经典能力,进化为打造“豆包同款”的生成式智能。
面对新时代的需求,“豆包同款”视频云在技术侧构建了三层支撑:底层是AIGC传输系统,中层是核心引擎AI MediaKit与智能媒体处理平台MIPP,顶层则是音视频互动智能体。在服务侧,火山引擎的视频与边缘服务正加速海外拓展,助力中国企业出海。
1. 从“抖音同款”到“豆包同款”,音视频技术的三重进化
底层技术支撑:AIGC传输系统让多模态交互成为可能
AI时代要求音视频系统能理解并互动,这意味着需要处理更多维度的信息,如视频、音频、图像、文字等多模态数据。为此,支撑豆包等大规模AI应用的AIGC传输系统应运而生。
该系统不仅支持实时、长连接的多模态数据传输,还能覆盖多样化的实时交互场景:从实时音视频、实时语音流,到Push-to-Talk半实时语音交互及控制信令传输,均可基于同一套基础设施稳定运行。为了保障复杂网络环境下的流畅体验,系统还内置了弱网对抗机制。
AIGC传输系统实现了面向人机实时交互的多模态数据传输能力升级,能支撑高并发和突发业务场景下的稳定、实时、可扩展的数据传输。在此之上,还需要一个能对底层原子能力进行统一编排调用的全链路核心引擎。基于AIGC传输系统与分布式多媒体智能处理平台MIPP的支撑,火山引擎视频云核心引擎AI MediaKit实现了全面升级。
传统媒体工具套件聚焦于媒体数据处理与服务,主要用于开发音视频播放或录制功能。而在AIGC时代,媒体价值链路被重塑:内容生命周期拓展为生成、分析、理解、消费;用户交互方式也变为通过自然语言、语音、图像等多模态进行。
因此,火山引擎将经典能力升级为AI MediaKit。作为面向AI云原生时代的效率工具,AI MediaKit将抖音、豆包等业务中打磨成熟的媒体处理技术,解构成更细粒度的原子能力。这些在云原生与音视频领域长期积累的能力,是火山引擎的核心竞争力。
在视频理解、AI推荐搜索、内容二次创作等场景中,AI MediaKit能够将大模型的多模态理解能力和AIGC生成能力引入音视频处理流程,让系统不仅能“看见”和“听见”,还能理解内容语义,从而放大媒体价值。
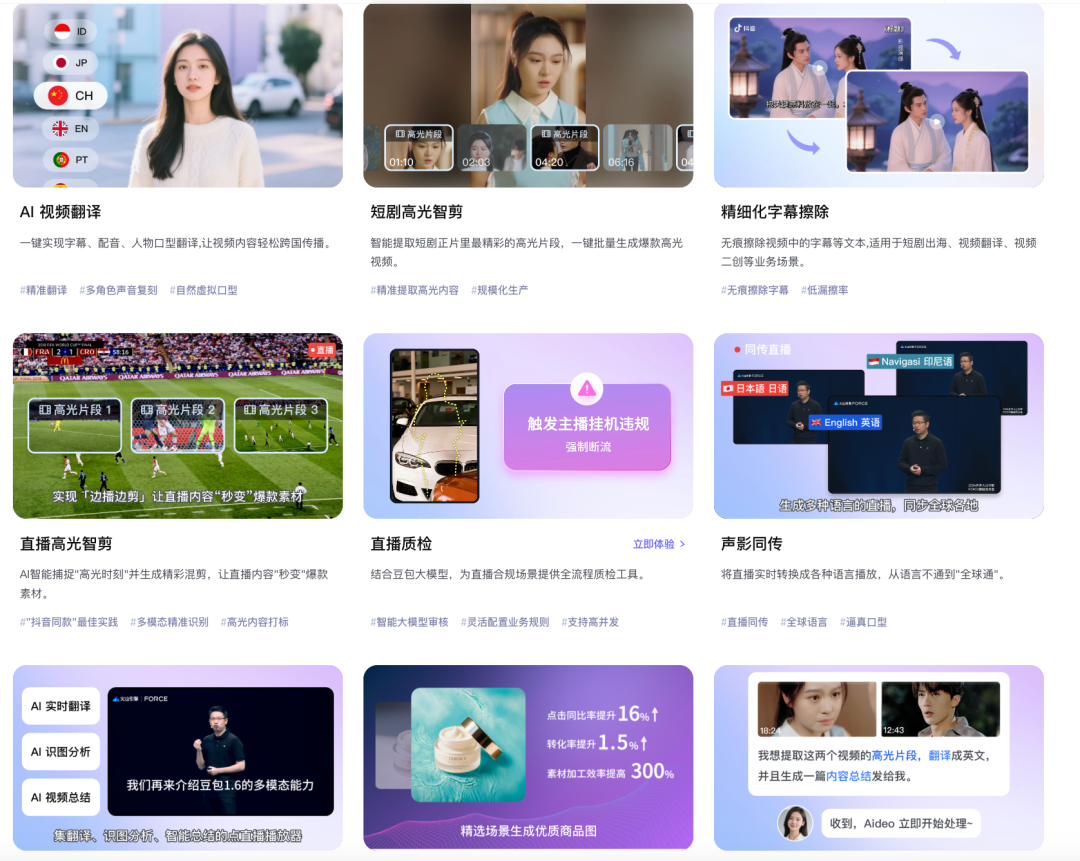
AI MediaKit的另一核心价值在于提升内容生产效率和体验。它面向大模型调用与编排更加友好,通过提供预设的、可配置的AI工作流,从数据预处理、后处理及并发任务处理等角度进行优化,将多媒体处理能力与大模型原子能力高效编排。
以视频翻译为例,“声影智译”方案基于豆包大模型,结合视频云的理解与预处理能力,以及语句切分、语速控制、说话人定位等多媒体工程能力,为大模型提供更优质的“原材料”,最终实现包括文本、声音乃至面容在内的多模态视频翻译,效果达到业务生产水平。
AI MediaKit通过深度融合生成式AI与多模态理解能力,拓展了多媒体处理的深度与广度。此次升级推动了多媒体能力从单一工具向价值放大器转变,帮助企业更高性价比地构建生产级AI应用与音视频智能体。
顶层应用:音视频互动智能体推动交互体验升级
构建一个能在生产环境中稳定运行的智能体需要整合复杂系统能力。为降低企业门槛,火山引擎提供了一套完整解决方案,将工具属性的音视频对话AI,升级为交流顺畅、具备记忆与问题解决能力的音视频互动智能体。
此次升级的关键在于两点:其一,AI在感官体验上更接近真人;其二,AI智能体拥有特定场景的知识和技能。 为增强“真人感”,火山引擎通过模型精调,使智能体回复更口语化,覆盖开心、激动、安慰等20多种情绪状态,以及夹子音、气泡音等多种表达方式,并能根据上下文动态调整语速、音调。

本次升级的一大亮点是声纹识别能力。该能力可识别不同说话人的音色。在一对一交流中,智能体可以锁定主讲人声音,屏蔽其他人声,实现声纹层面的降噪。目前支持无感注册,仅需约10秒音色采样即可完成识别。
此外,声纹识别还能实现个性化应答。例如,AI玩具识别到与小孩交流时,会用更可爱的声音回应;识别到与成人交流时,则切换为更自然的语气。
对于陪伴类应用,长期记忆功能至关重要。智能体通过持续记录历史交互,将碎片化对话串联成连续故事,从而更深入理解用户偏好,甚至能主动提供信息与建议,使沟通更个性化。
在典型应用场景中,音视频互动智能体价值显著:
- 教育场景:AI老师通过声音复刻及情绪优化,高度模拟真人老师,实现“人机协同”深度耦合。
- 游戏场景:AI游戏陪玩不仅能提供情绪价值,还能实时感知游戏进程,提供专业攻略指导。
- 创作场景:智能体通过多轮对话理解用户创作意图,降低高质量Prompt的生成门槛,提升创作可控性与效率。
在智能硬件方面,火山引擎联合乐鑫推出“喵伴”硬件开发套件。该套件开箱即用,开发者可快速搭建产品原型,5分钟跑通业务链路,并借助标准化接口兼容多硬件设备,大幅降低适配成本。
展望未来,音视频互动智能体的交互体验将持续演进。一个清晰趋势是多智能体协作,为视频会议、AI教学、社交游戏等场景带来更复杂、多角色的互动体验。
2. 国产AI应用,掀起出海浪潮
国产AI应用出海已成必然趋势。报告显示,中国AI应用的全球市场份额正在持续增长。然而,出海之路充满挑战:方案适配、网络体验、资源利用、商业模式等均是关键变量。
为应对企业出海需求与现实挑战,火山引擎视频与边缘服务提供了一套体系化出海解决方案。例如,针对出海应用体验差、成本高等痛点,火山引擎智能全球加速(IGA)提供了AI应用加速方案,能优化全球范围内的大模型请求、训练数据传输及生成等场景,实现更快、更稳、更安全的访问,助力开发者降低试错成本,加速商业模式验证。
为提升互动实时性,火山引擎还推出了面向出海场景的Conversational AI解决方案,支持超百种语言的交互,并融合音视频、图像等多模态交互能力,通过模型、语音、视频及数字人通话场景,帮助企业实现业务创新。
目前,该方案已助力多个中国AI应用走向全球。以短剧、漫剧出海为例,麦芽短剧依托火山引擎声影智译,实现了高效的AI视频翻译,保障内容无障碍全球化传播,并通过精细化字幕擦除技术,最大程度还原视频画面。
从内容生产、分发到变现,火山引擎视频云通过全方位进化,构建了完整的出海价值链条。这轮从“抖音同款”经典能力到“豆包同款”生成式智能的进化,本质上是火山引擎为下一代人机交互方式所做的系统性准备。
 发表于 2025-12-25 02:09:18
|
查看: 245|
回复: 0
发表于 2025-12-25 02:09:18
|
查看: 245|
回复: 0
