让智能体(Agent)自主操作图形用户界面(GUI),是实现通用人工智能(AGI)的关键一步。然而,现有方案普遍面临两大难题:依赖文本表示与模块化框架的方案,往往存在平台兼容性差、泛化能力弱且需要大量人工规则指导的问题;而端到端的 GUI 智能体模型,又受制于 GUI 感知难度大、高质量训练数据匮乏的瓶颈,难以适应动态多变的真实环境。
为应对这些核心挑战,来自字节跳动 Seed 与清华大学的研究团队提出了一种原生 GUI 智能体模型 —— UI-TARS。该模型仅以屏幕截图作为输入,即可执行类人的鼠标与键盘交互操作。与当前需要专家设计提示词、依赖高度封装商业模型的智能体框架不同,UI-TARS 是一个端到端模型,其性能全面超越了这些复杂的框架。
在关键基准测试中,UI-TARS 表现卓越:
- 在 OSWorld 基准上,UI-TARS-72B-DPO 在50步限制下得分为 24.6,在15步限制下得分为 22.7,均优于 Claude Computer Use 的 22.0 和 14.9。
- 在 AndroidWorld 基准上,UI-TARS-7B-DPO 得分高达 46.6,显著超越了 GPT-4o(34.5)。
这项技术已快速走向产品化。2025年底,豆包手机正是依托 UI-TARS 模型的强大交互能力,实现了仅通过视觉识别自主完成跨应用、多步骤复杂任务的功能,将手机从“被动响应指令”升级为“主动解决问题”的智能伙伴。
作为核心技术支撑,其配套的桌面开源项目 UI-TARS-desktop 在 GitHub 上迅速走红,目前已收获 27.7k Stars,成为AI Agent领域备受瞩目的热门开源项目。
01 UI-TARS 技术原理
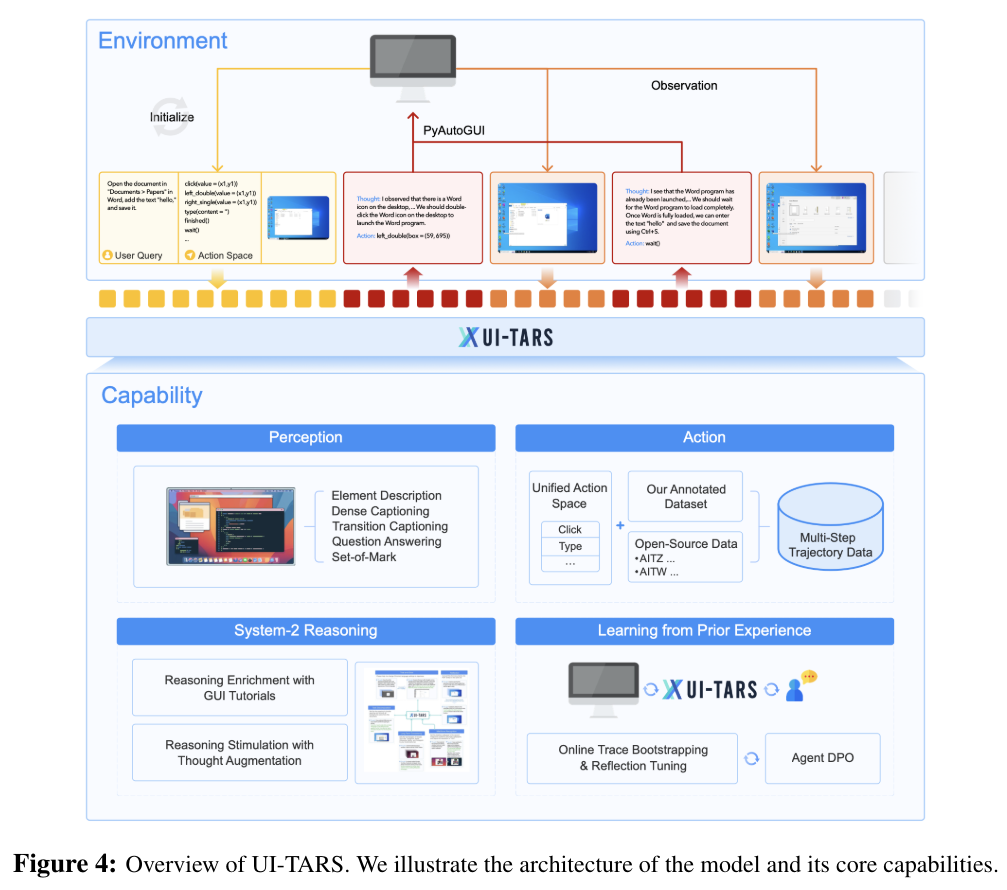
UI-TARS 是一种原生 GUI 智能体模型(native GUI agent model),其设计旨在摆脱传统智能体框架所依赖的繁琐人工规则和级联式模块。如上图所示,UI-TARS 模型能够直接感知屏幕截图进行推理,并自主生成有效动作。此外,它还能从过往经验中学习,利用环境反馈不断迭代优化其性能。
(1)针对 GUI 截图的感知能力增强
GUI 环境具有信息密度高、布局复杂、风格多样等特点,对智能体的感知能力要求极高。为此,研究团队构建了一个大规模数据集:通过专用解析工具从网站、应用程序和操作系统中采集屏幕截图,并提取元素类型、边界框和文本内容等元数据。
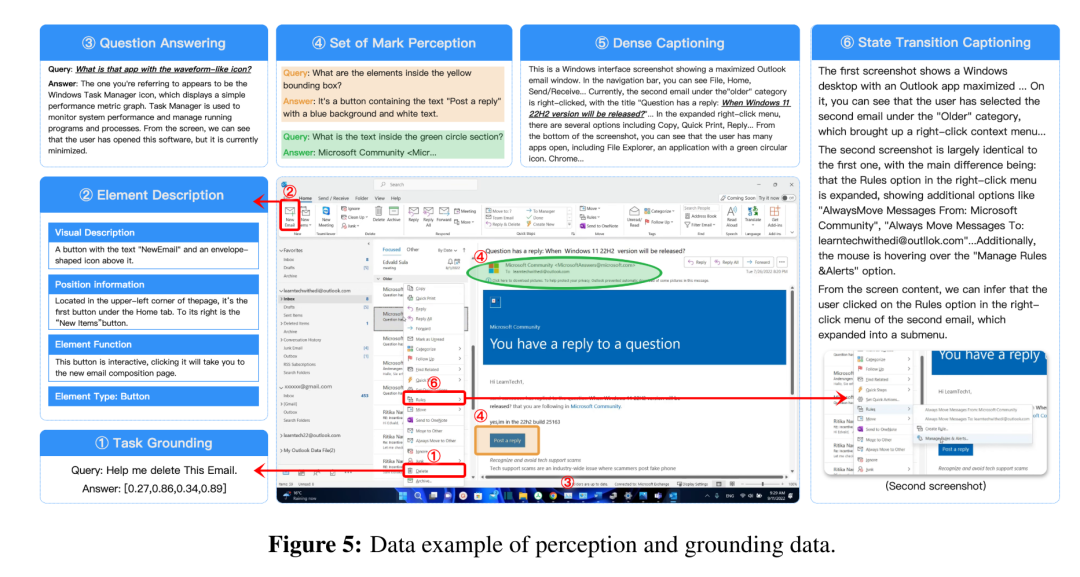
如上图所示,研究团队主要整理了五项任务的数据:
- 元素描述:为 GUI 组件生成细粒度、结构化的语义描述。
- 密集标注:通过描述整个 GUI 布局(包括元素间的空间关系、层级结构及交互方式),实现界面的整体理解。
- 状态转换标注:捕捉屏幕中细微的视觉变化。
- 问答:旨在增强智能体的视觉推理能力。
- 标记集合提示:利用视觉标记将GUI元素与特定的空间及功能上下文关联起来。
这些精心设计的任务,使得 UI-TARS 能够精准识别和理解 GUI 元素,为其后续的推理与行动提供了坚实的基础。
(2)统一动作建模与定位
研究团队设计了一个统一动作空间,以标准化跨平台的语义等价动作。
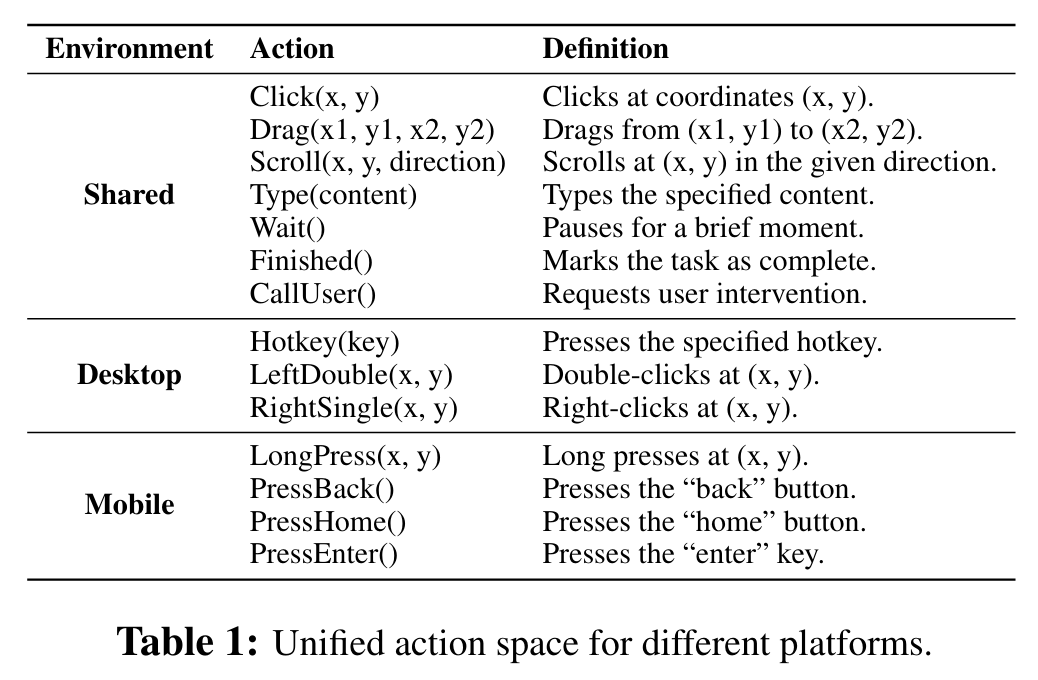
为提升智能体执行多步骤任务的能力,研究团队构建了一个大规模动作轨迹数据集,整合了标注的操作轨迹与标准化的开源数据。
此外,为增强定位能力(准确找到特定 GUI 元素并与之交互的能力),研究团队专门构建了一个将元素描述与其空间坐标配对的大规模数据集。
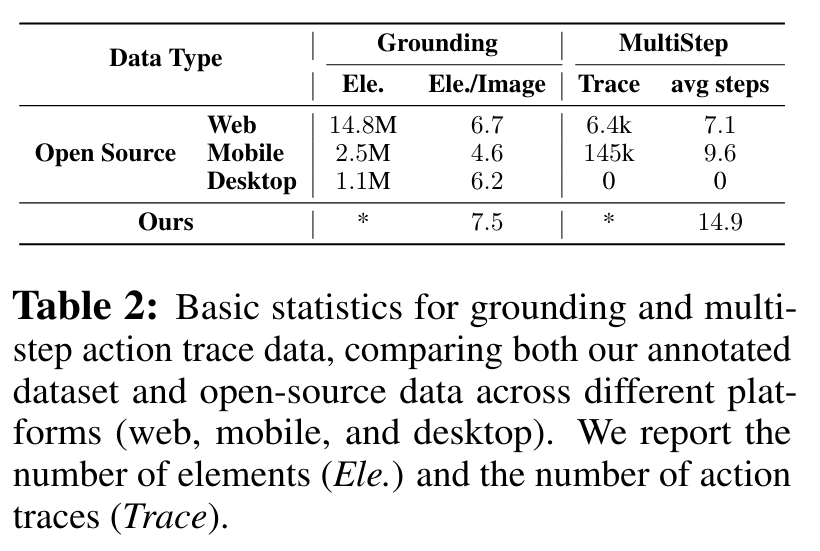
该数据使 UI-TARS 能够实现精准可靠的交互。
(3)融入 System-2 推理
智能体要在动态环境中实现稳健性能,需要具备先进的推理能力。为此,研究者爬取了 600 万条 GUI 操作教程并经过严格筛选与精炼,构建了支持逻辑决策的 GUI 知识基础。
为激发 UI-TARS 的推理能力,研究团队对收集的动作轨迹数据进行了思维增强:通过两阶段标注方法,在原有的观察-动作序列中插入显式“思维”步骤,构建出 “观察–思维–动作” 的结构化轨迹。在生成思维时,通过提示视觉语言模型遵循 System-2 推理模式,包括任务分解、长期一致性、里程碑识别、试错以及反思,使模型在执行每个动作前生成可解释的推理过程,从而在感知与动作之间建立决策桥梁。

(4)基于经验的迭代优化
为应对 GUI 交互高质量轨迹数据稀缺的瓶颈,UI-TARS 采用了一种迭代改进框架,能够动态收集并精炼新的交互轨迹。利用数百台虚拟机,UI-TARS 基于构造的指令探索多样化的现实任务,并自动生成大量交互轨迹。通过多阶段过滤保证轨迹质量,包括基于规则的启发式方法、VLM 评分和人工审核。这些精炼后的轨迹随后反馈至模型,使智能体在连续的训练周期中实现持续迭代的性能提升。
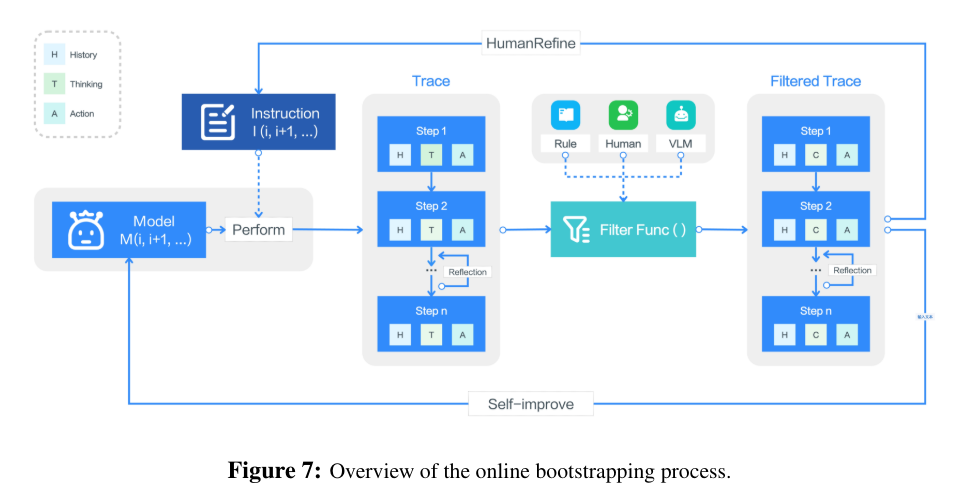
该在线引导过程的另一关键组成部分是反思调优:智能体通过分析自身次优或失败的操作,学习识别错误并主动恢复。为此,研究团队标注了两类数据:
- 错误修正:标注员指出智能体生成轨迹中的错误,并标注纠正动作。
- 事后反思:标注人员模拟错误发生后的恢复步骤,展示智能体应如何重新对齐任务进度。
这两类数据构成了配对样本,用于直接偏好优化训练模型。该策略确保智能体不仅能学会避免错误,还能在错误发生时动态调整行为。
(5)训练流程
为确保与 Aguvis 和 OS-Atlas 等研究进行公平比较,研究团队采用了相同的 VLM 主干 Qwen-2-VL,并实施一个三阶段训练流程。该流程使用约 50B tokens 的数据,逐步提升模型在多样化 GUI 任务上的性能。
- 持续预训练阶段:使用收集的完整数据集(不包括反思调优数据),以恒定学习率进行持续预训练。这一基础阶段使模型掌握自动化 GUI 交互所需的全部核心知识。
- 退火微调阶段:从感知、定位、动作轨迹及反思调优数据中筛选出高质量子集,用于退火训练。此阶段训练完成的模型标记为 UI-TARS-SFT。
- DPO 优化阶段:利用在线引导过程中标注的反思配对数据进行 DPO 训练。在此阶段,模型通过强化最优动作、抑制次优行为来优化其决策能力。最终得到的模型记为 UI-TARS-DPO。
02 评估结果
(1)感知能力评估
研究团队使用三个关键基准测试评估 UI-TARS 模型的感知能力。
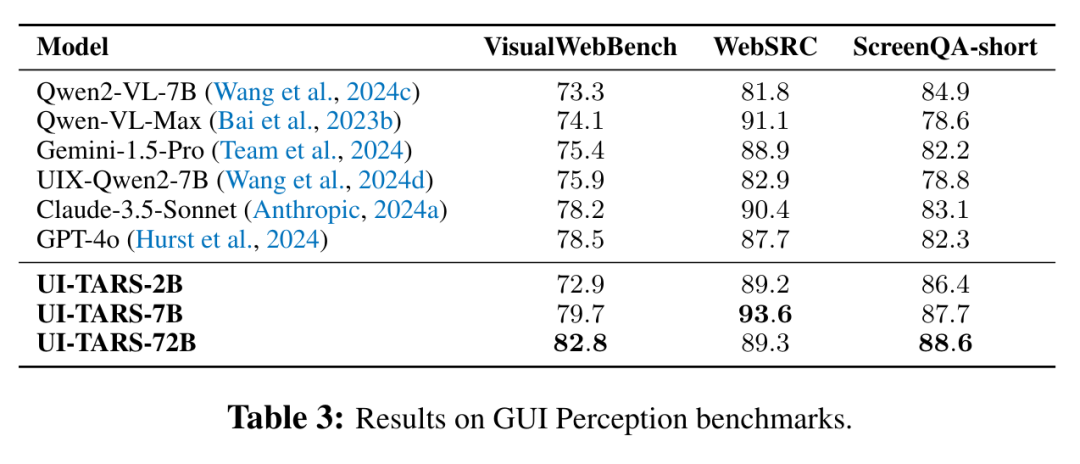
- VisualWebBench 用于衡量模型对网页元素的理解与定位能力。UI-TARS-72B 在此基准上得分达 82.8,显著优于 GPT-4o 和 Claude 3.5 等闭源模型。
- 在网页结构理解 WebSRC 和移动端屏幕内容理解 ScreenQA-short 基准测试中,UI-TARS 同样展现出明显优势。UI-TARS-7B 在 WebSRC 上取得 93.6 的领先分数;UI-TARS-72B 在 ScreenQA-short 上以 88.6 分表现最佳。
上述结果表明,UI-TARS 在网页与移动端环境中有强大的感知与理解能力。
(2)定位能力评估
研究团队通过三个基准来评估 UI-TARS 的定位能力。
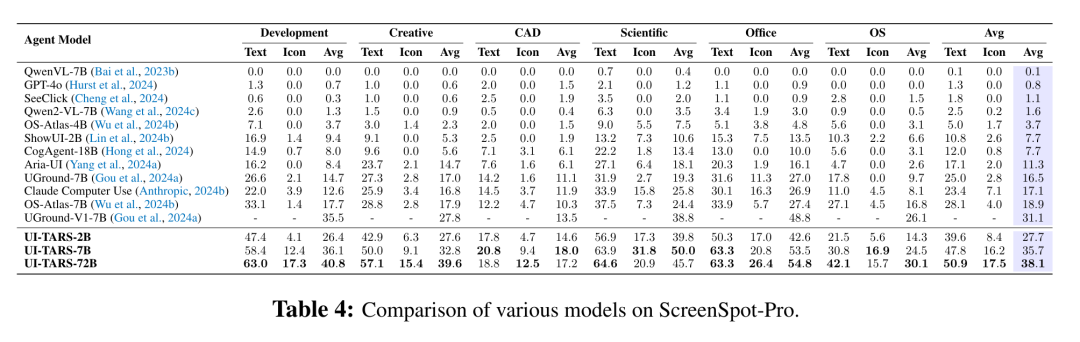
- ScreenSpot Pro 基准面向高分辨率专业场景设计,对模型在高度专业化环境下的定位性能进行严格评估。如表所示,UI-TARS-72B 在 ScreenSpot Pro 上取得 38.1 分,显著优于其他基线模型。
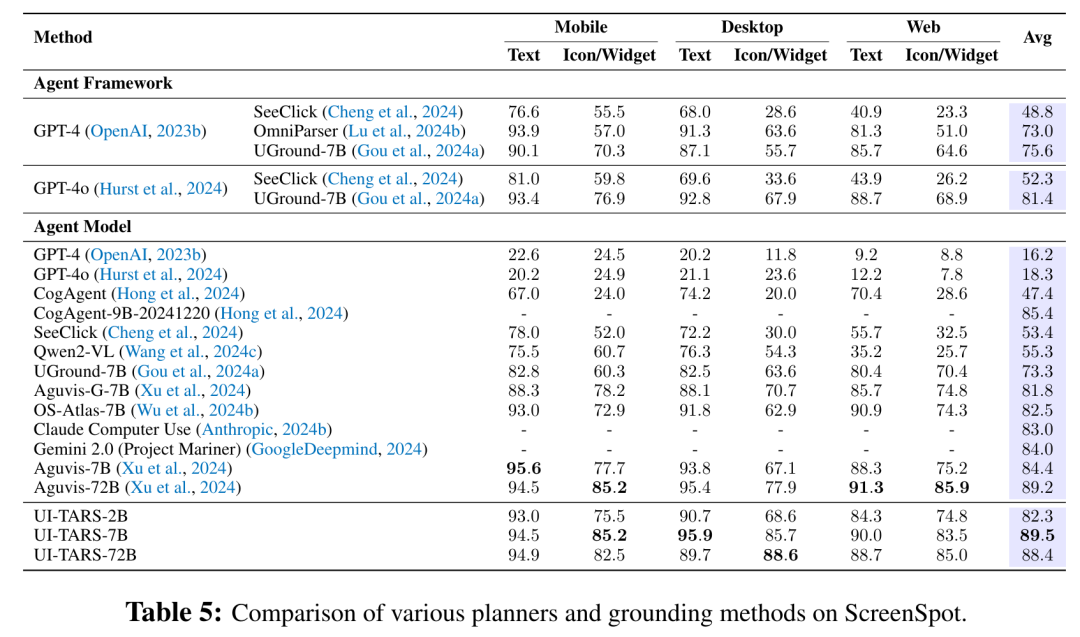
- 在 ScreenSpot 基准上,UI-TARS-7B 以 89.5 分位居榜首。
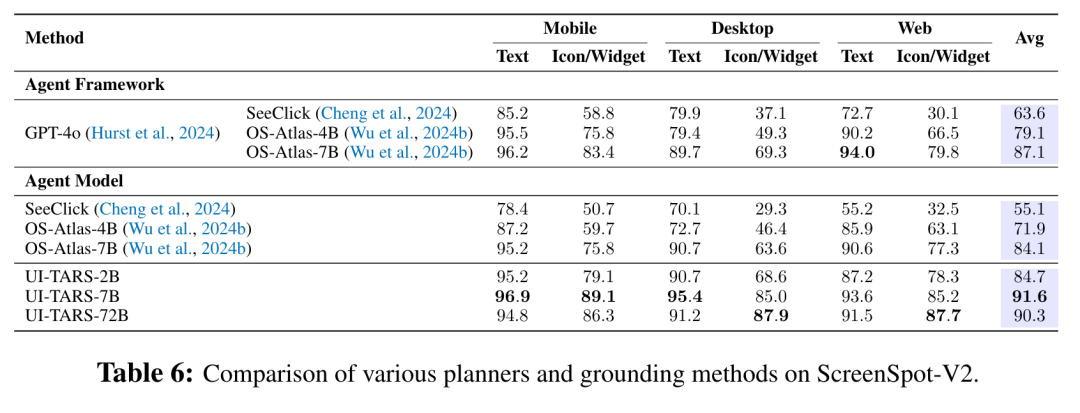
- 在 ScreenSpot v2 基准上,UI-TARS-7B(91.6)与 UI-TARS-72B(90.3)均超越现有最强基线,进一步验证了该方法的鲁棒性。
(3)离线智能体能力评估
为了评估 UI-TARS 在静态、预定义环境中的 GUI 智能体能力,研究团队在多个基准上进行了测试。
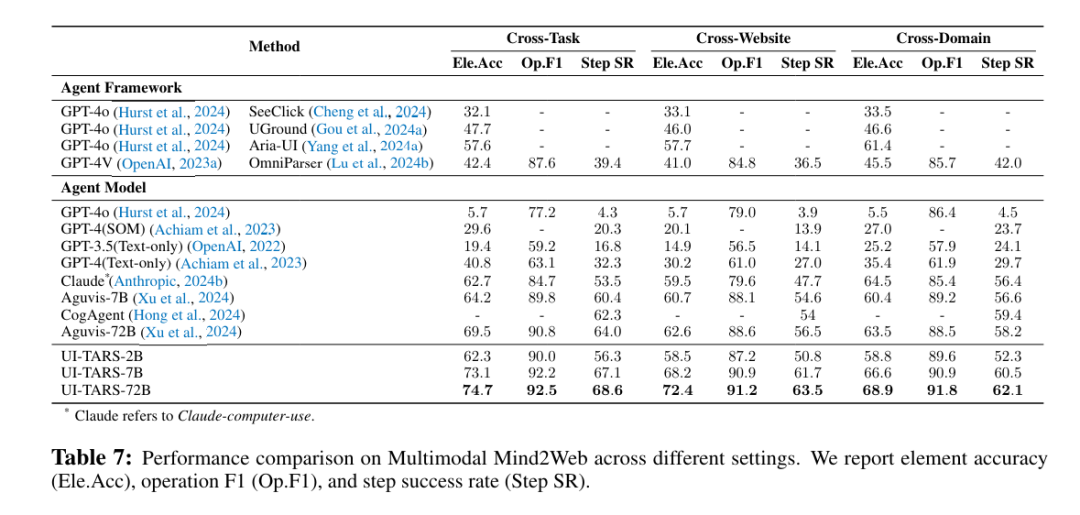
如表所示,在 Multimodal Mind2Web 中,UI-TARS-72B 在关键指标上取得 SOTA 性能。值得注意的是,UI-TARS-7B 虽参数量较少,但仍优于 Aguvis-72B 和 Claude 等强基线模型。
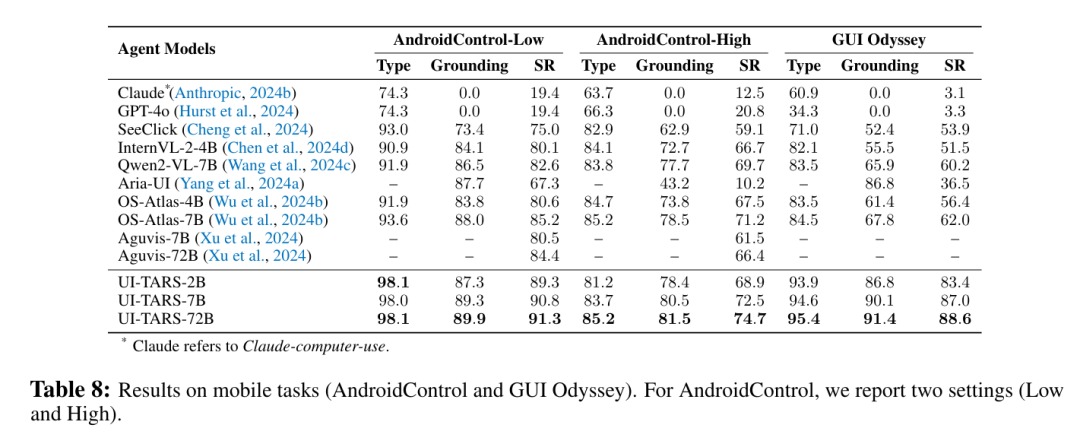
在 Android Control 和 GUI Odyssey 中,UI-TARS-7B 与 UI-TARS-72B 均超越了此前的 SOTA 方法,充分体现了其在多步离线任务中的卓越性能。
(4)在线智能体能力评估
在线评估在动态环境中进行,以真实还原现实交互场景。
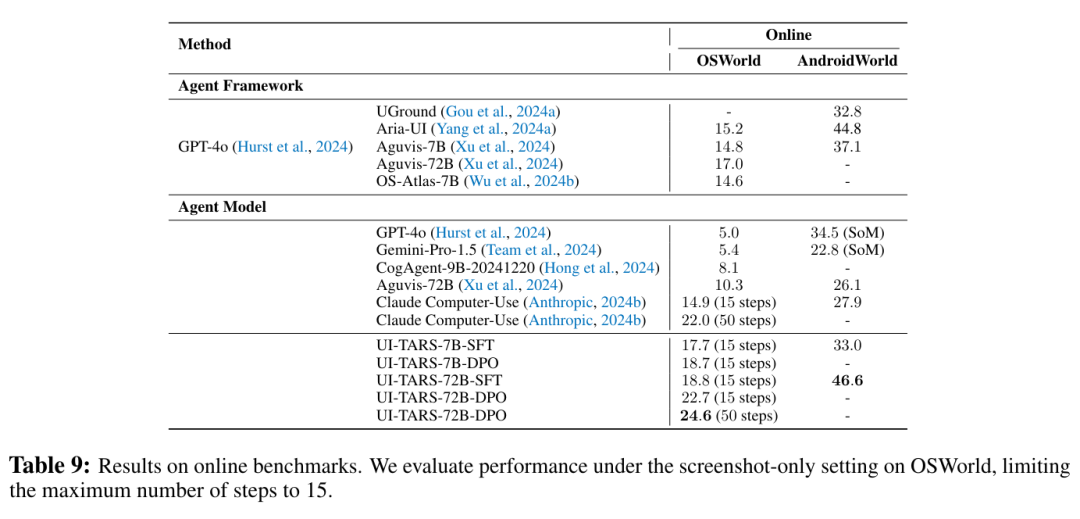
- 在 OSWorld 上,当动作步数限制为 15 步时,UI-TARS-72B-DPO(22.7)显著优于 Claude(14.9)。UI-TARS-72B-DPO 在仅 15 步的预算下即可媲美 Claude 在 50 步预算下的表现,展现出卓越的执行效率。在 50 步预算下,UI-TARS-72B-DPO 以 24.6 分刷新了 OSWorld 的 SOTA 记录。
- 在 AndroidWorld 上,UI-TARS-7B-DPO 取得 46.6 分,不仅优于此前最佳的智能体框架,也大幅领先于其他智能体模型。
- 对比 SFT 与 DPO 模型,DPO 显著提升了 OSWorld 基准上的性能,表明在训练中引入“负样本”有助于优化决策质量。
- 对比不同规模模型,在线任务中 72B 模型的表现远优于 7B 模型,且性能差距明显大于离线任务。这说明扩大模型规模显著增强了 System-2 推理能力。同时这一差异也表明,仅依赖离线基准的评估可能无法准确反映模型在实时动态环境中的真实能力。
总结
UI-TARS 通过端到端的方式,结合强大的感知、统一的动作空间、System-2 推理以及基于经验的迭代优化,在 GUI 自动化交互任务上树立了新的标杆。其在多项离线与在线基准测试中的卓越表现,不仅验证了原生智能体模型的巨大潜力,也为未来人工智能与真实世界交互的研究提供了重要的技术路径。其开源桌面版本的发布,更是为开发者和研究者提供了宝贵的实践工具。想了解更多前沿技术解析与开源项目动态,欢迎持续关注云栈社区。
 发表于 2026-2-12 18:08:12
|
查看: 557|
回复: 0
发表于 2026-2-12 18:08:12
|
查看: 557|
回复: 0
