在高性能计算(HPC)领域,存在大量采用 MPI 与 OpenMP 混合并行的遗留代码。其典型模式是使用 MPI 在节点间分解任务,并在每个 MPI 进程(节点)内利用 OpenMP 进行共享内存多线程计算,以充分利用 CPU 的多核资源。
- MPI:负责节点间(inter-node)通信,内存相互隔离。
- OpenMP:负责节点内的共享内存多线程并行,内存共享。
在这种架构中,每个 MPI 进程(Rank)通常绑定到一个 CPU 核心,而该核心通过 OpenMP 派生出多个线程(Threads)来执行计算任务,共同支撑整个应用程序的运行。
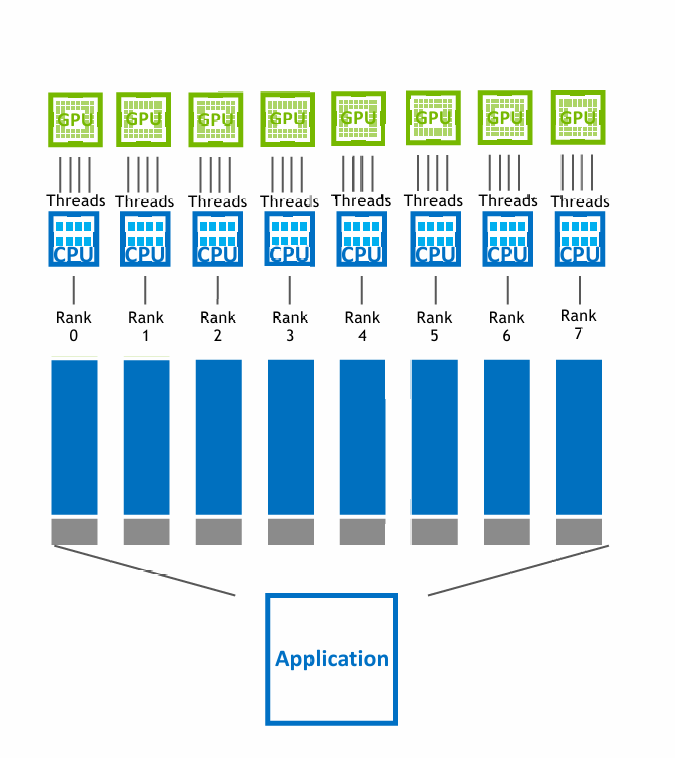
将混合并行代码移植至CUDA
在将这些 MPI+OpenMP 代码迁移到 GPU 平台时,一种直接的策略是将每个 OpenMP 线程的计算任务映射到一个独立的 CUDA 流中,由该流向 GPU 发射核函数。自 CUDA 11.4 起,这变得更加方便。下图展示了单GPU版本的实现思路:

这种移植方法具有以下特点:
- 适用场景:只有当每个线程所承载的计算任务量足够大,能够抵消频繁启动CUDA核函数带来的开销时,这种改写才具有价值。
- 开发成本:相较于彻底重写代码(移除OpenMP,用纯CUDA逻辑重构),此方法能显著加快移植速度。
- 性能上限:其执行效率通常低于精心设计的单线程多流方案(用流占满GPU)或单个大规模核函数方案。
多GPU扩展方案
将上述方案扩展到多GPU环境时,核心思想类似,但需额外注意设备与流的绑定关系,确保每个CUDA流在其正确的GPU设备上执行,否则会导致运行时错误。

考虑一个具体场景:共有16个OpenMP线程、64个CUDA流、8个GPU以及总计N=1024个计算任务。
- 每个GPU分配 8 个流(64流 ÷ 8 GPU)。
- 每个流平均处理 16 个核函数任务(1024任务 ÷ 64流)。
- 核心原则是确保每个GPU至少被分配一个流。
- 当计算任务本身具有并行性时,增加流数量可能通过并发执行更多核函数来更好地占满GPU的计算单元(如SM),从而提升效率,这属于一种云原生/IaaS场景下的并行计算与资源调度优化思路。
- 然而,一般情况下,使用单个流全力占满整个GPU的效率往往更高,因为创建和管理多个流本身也会引入额外开销。
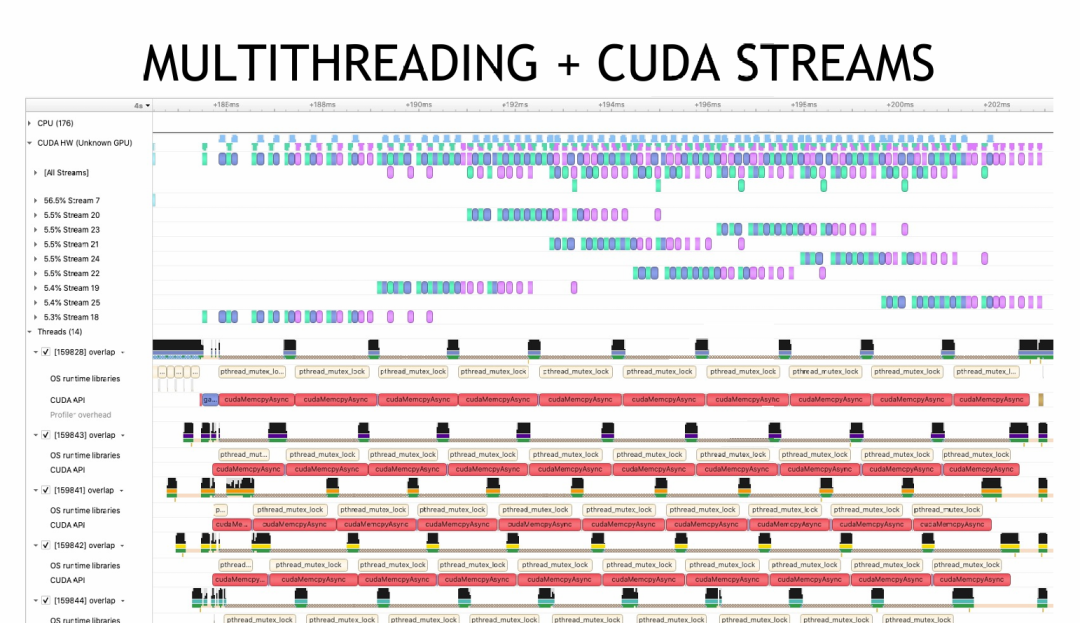
使用Nsys进行性能分析
性能剖析工具如 Nsys 可以帮助我们直观地理解不同策略下的计算重叠情况。
- 单线程多流:分析图显示核函数计算之间存在重叠区域,证明了多流并发的有效性。
- 多线程多流:Nsys时间线可以清晰展示主机(Host)上多个线程的活动,以及它们各自发射的GPU任务之间的计算重叠。
以下是一组对比实验的计算时间统计:
- 单线程 + 默认流:0.01879 秒。
- 单线程 + 8个CUDA流:0.00781 秒。(性能显著提升)
- 8个OpenMP线程 + 8个CUDA流(无性能分析):0.00835 秒。
- 8个OpenMP线程 + 8个CUDA流(开启性能分析):0.01798 秒。(说明性能分析工具本身会带来额外开销)
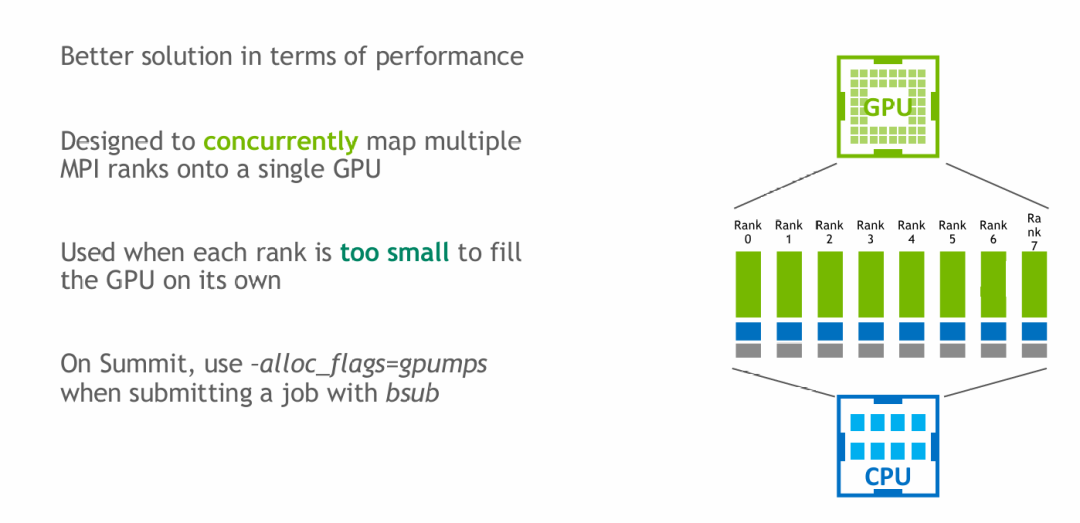
多进程服务(MPS)方案
对于纯粹使用 MPI(无OpenMP)的代码,另一种优化策略是启用 NVIDIA 的多进程服务(MPS)。MPS 允许多个MPI进程同时共享访问同一个GPU资源。如果不开启MPS,多个进程对同一GPU的访问将是串行的。
- 未开启MPS:进程A完全使用完GPU后,进程B才能开始使用,导致GPU资源利用率低下,尤其当每个进程的计算量较小时。
- 开启MPS后:GPU驱动会通过MPS服务,将来自不同进程的计算任务拆解并交织在一起,并发地调度到GPU上执行。这种调度发生在驱动层,甚至允许不同进程的任务在同一流多处理器(SM)上混合执行,从而提升GPU的整体利用率,这在人工智能模型训练等需要密集GPU计算的场景中尤为重要。
MPS 与 CUDA 多流方案对比
| 维度 |
CUDA流 |
MPS (多进程服务) |
| 设计层级 |
应用层 / CUDA 运行时层 |
驱动层 / 系统层 |
| 管理对象 |
单个进程内的多个任务序列 |
多个独立的进程 |
| 调度主体 |
GPU 硬件调度器 |
NVIDIA 驱动(MPS 服务器) |
| 资源视图 |
单个进程独占 GPU 虚拟资源 |
多个进程共享 GPU 物理资源 |
| 运行上下文 |
所有流共享同一 CUDA 上下文 |
每个进程拥有独立的 CUDA 上下文 |
| 内存管理 |
所有流共享进程的虚拟地址空间 |
进程间内存隔离 |
| 错误隔离 |
一个流中的错误可能导致整个进程崩溃 |
单个进程崩溃通常不影响其他进程 |
|  发表于 2025-12-25 04:10:21
|
查看: 152|
回复: 0
发表于 2025-12-25 04:10:21
|
查看: 152|
回复: 0
