在深度学习和高性能计算领域,GPU 的编程模型始终在抽象易用与极致性能之间艰难平衡。
一方面,CUDA 和 HIP 提供了接近硬件的底层控制力,但开发效率低下,且需要深厚的体系结构知识;另一方面,像 OpenAI Triton 这样的 Python DSL(领域特定语言)大幅降低了开发门槛,通过自动推导线程映射和数据布局,让开发者能快速编写出高效的 GPU 内核。
然而,自动化的代价往往是丧失对微架构细节的掌控——当你需要手动优化共享内存的 Bank 冲突、精确安排 MFMA(矩阵乘加)指令的流水线时,Triton 的抽象层反而会成为障碍。
这正是 FlyDSL(Flexible Layout Python DSL)诞生的背景。它由 AMD ROCm 团队开发,旨在填补这一空白:在 Python 层面提供一种带有显式布局和分块(explicit layouts and tiling)的 MLIR 编译器栈,让开发者既能享受 Python 的便利,又能像使用 NVIDIA 的 C++ CuTe 模板库一样,精确控制线程分布、数据排布和内存移动。
本文将深入解读 FlyDSL 的设计哲学、核心技术,以及它如何解决 GPU 编程中“最后一公里”的优化难题。我们将结合伪代码和性能数据,剖析这个开源项目的创新之处。
零、对标 NVIDIA CuTe?
FlyDSL 以 NVIDIA 的 CuTe 为核心对标与灵感来源,同时为弥补 OpenAI Triton 在硬件细粒度控制上的不足而设计,也印证了“FlyDSL = Python 语法的 CuTe + MLIR 编译后端”这一精准定位。
FlyDSL 与 CuTe 的对标主要体现在三个方面:
- 一是解决的问题一致,均围绕布局代数(Layout Algebra)展开。 编写高性能 GPU Kernel(尤其是 GEMM)时,难点在于全局内存、共享内存与寄存器之间的数据调度,手写索引逻辑复杂易错。
- CuTe 通过 C++ 模板元编程定义 Layout,将内存坐标映射转化为代数运算;
- FlyDSL 则通过
flir.make_shape、flir.make_stride、flir.make_layout 等原语,把这套思想迁移到 Python 与 MLIR 层面。
- 二是操作原语高度对应。 FlyDSL 的
flir.make_tiled_copy_tv、get_slice、partition_S 等接口,基本是 CuTe 中对应 C++ 原语在 Python 环境下的实现。
- 三是 FlyDSL 在 CuTe 基础上实现了差异与超越。
- CuTe 是 C++ 头文件库,能力强大但学习成本高,且与 NVIDIA 生态深度绑定;
- 而 FlyDSL 将 Layout 系统封装为 MLIR 方言,同时提供易用的 Python 前端,既能保持接近 PyTorch/Triton 的开发体验,又能实现 CuTe 级别的细粒度内存优化,并最终编译适配 AMD ROCm/MFMA 指令。
因此,FlyDSL 也被准确地描述为:介于 Triton 过度抽象与 CUDA/C++ 底层控制之间的“第三条道路”。
一、项目定位:站在巨人的肩膀上
FlyDSL 并非从零造轮子,它的设计灵感汲取自多个优秀的开源项目:
- OpenAI Triton:提供了 Python DSL 编译到 GPU 的前端范式,FlyDSL 借鉴了其“Python 前端 + 编译器后端”的架构,但将布局控制权交还给开发者。
- NVIDIA CUTLASS / CuTe:CuTe 的布局代数为显式张量布局提供了数学基础,FlyDSL 将其思想引入 MLIR,构建了类型安全的布局系统。
- ROCm Composable Kernel (CK):AMD GPU 上基于 Tile 的 kernel 设计模式被直接采纳,例如 Ping-pong LDS 缓冲、XOR16 Swizzle 等。
FlyDSL 的核心是 FLIR(Flexible Layout Intermediate Representation)——一个基于 MLIR 的编译器栈,其核心方言 flir 提供了第一类布局 IR,并附带完整的降级流水线到 GPU/ROCDL。 简而言之,FlyDSL 让你在 Python 中写的布局表达式,能通过 FLIR 精确映射到底层硬件指令。
总的来说,FlyDSL = Python 语法的 CuTe + MLIR 编译后端,目标是实现比 Triton 更极致的性能调优。
二、解决的痛点:为什么需要显式布局?
让我们先看一个简单的向量加法(VecAdd)例子。在 Triton 中,你只需要写:
@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
Triton 自动为你分配线程(tl.arange)和内存访问模式。这非常方便,但当你需要更精细的控制时,比如:
- 每个线程一次加载 8 个元素(向量化加载)
- 在 LDS 中采用 XOR Swizzle 布局以避免 bank 冲突
- 精确控制 wavefront 内线程的协作方式
Triton 就无法直接表达了,你不得不回退到 CUDA/C++,或者依赖编译器启发式策略,而启发式往往无法针对特定硬件达到最优。
FlyDSL 允许你在 Python 中显式定义这些布局:
# 定义线程布局:256个线程,按列主序排列
thr_layout = flir.make_ordered_layout((256,), order=(0,))
# 定义值布局:每个线程处理8个元素
val_layout = flir.make_ordered_layout((8,), order=(0,))
# 创建拷贝原子(向量宽度4)
copy_atom = flir.make_copy_atom(T.f32(), vector_size=4)
tiled_copy = flir.make_tiled_copy_tv(copy_atom, thr_layout, val_layout,
thr_shape=(256,), val_shape=(8,))
通过这种显式描述,你告诉编译器:每个线程负责 8 个元素,并且要使用向量宽度为 4 的加载指令。编译器会生成相应的 SIMD 指令,而不会自动拆分或合并。
三、核心困难:布局代数的编译时推导
要实现这样的显式控制,最大的挑战是:如何在编译时处理复杂的嵌套布局,并将它们高效地转换为线性内存索引?
例如,一个分块布局可能由 (block_rows, block_cols) 和每个块内的 (tile_rows, tile_cols) 组成,最终的索引公式是 block_row * block_stride + tile_row * tile_stride。这些表达式可能混合了编译时常量和运行时变量(如动态维度)。
FLIR 的解决方案是引入一套类型-模式编码(Type-Mode Encoding):
- 在类型层面,布局的嵌套结构、静态维度和动态占位符都被编码在 MLIR 类型中,如
!flir.shape<(9,(4,?))>。
- 动态维度的值作为操作的操作数(operands)传入,按深度优先顺序排列。
- 编译器在降级过程中,尽可能进行常量折叠,对动态值生成运行时算术指令,并插入除零检查等安全保护。
四、创新点一:FLIR 布局代数系统
FLIR 方言的核心是四个基本类型:
!flir.shape:张量的逻辑尺寸,例如 (M, N)!flir.stride:内存步长,例如 (N, 1) 表示行主序!flir.layout:形状和步长的配对,定义了从逻辑坐标到线性索引的映射!flir.coord:多维坐标值
以及一组操作符,用于组合和变换布局:
flir.composition(A, B):布局组合,先应用 B 再应用 A(A ∘ B)flir.logical_product(block, tiler):将块布局和分块布局拼接,生成分层布局flir.logical_divide(layout, tiler):用分块器划分布局,产生嵌套结构
这些操作符的类型推导在编译时完成,能够处理静态和动态混合的情况。
代码实例与伪代码
我们来看布局组合操作的实现。在 MLIR 的 ODS(Operation Definition Specification)中,flir.composition 的定义位于 flir/include/flir/FlirOps.td:
def Flir_CompositionOp : Flir_Op<"composition"> {
let arguments = (ins Flir_LayoutType:$lhs, Flir_LayoutType:$rhs);
let results = (outs Flir_LayoutType);
let builders = [
OpBuilder<(ins "Value":$layoutA, "Value":$layoutB), [{
auto lhsTy = llvm::cast<mlir::flir::LayoutType>(layoutA.getType());
auto rhsTy = llvm::cast<mlir::flir::LayoutType>(layoutB.getType());
auto inferred = ::mlir::flir::inferCompositionType(
$_builder.getContext(), lhsTy, rhsTy);
// 如果推导失败,则退化为仅包含秩信息的类型
return $_builder.create<Flir_CompositionOp>(loc, inferred ? inferred :
Flir_LayoutType::get(lhsTy.getContext(), lhsTy.getRank()),
layoutA, layoutB);
}]>
];
}
这里的关键函数 inferCompositionType 实现在 flir/lib/Dialect/Flir/FlirLayoutAlgebra.cpp 中,它的逻辑可以用如下伪代码表示:
// 伪代码:inferCompositionType 的简化逻辑
LayoutType inferCompositionType(MLIRContext *ctx,
LayoutType A, LayoutType B) {
// 获取A和B的形状和步长模式(表示为模式树)
PatternNode a_shape = A.getShapePattern();
PatternNode a_stride = A.getStridePattern();
PatternNode b_shape = B.getShapePattern();
PatternNode b_stride = B.getStridePattern();
// 如果B是元组,递归组合每个子元素
if (b_shape.isTuple()) {
std::vector<PatternNode> result_shapes, result_strides;
for (size_t i = 0; i < b_shape.numChildren(); ++i) {
LayoutType subB = /* 构造子布局类型 */;
auto subResult = inferCompositionType(ctx, A, subB);
result_shapes.push_back(subResult.getShapePattern());
result_strides.push_back(subResult.getStridePattern());
}
return LayoutType::get(ctx,
PatternNode::tuple(result_shapes),
PatternNode::tuple(result_strides));
}
// 如果B是叶子,则对A的所有模式进行“折叠”
else {
// 算法:遍历A的模式,计算新的形状和步长
// 详情见原论文或代码注释
// 这里省略具体数学推导
PatternNode new_shape, new_stride;
/* ... 复杂计算 ... */
return LayoutType::get(ctx, new_shape, new_stride);
}
}
这个递归算法保证了即使面对复杂的嵌套布局,也能在编译时推导出结果的类型,从而为后续的代码生成奠定基础。
五、创新点二:Python 前端的无缝集成
FlyDSL 的 Python 包 flydsl 提供了与 MLIR 的无缝集成。它没有依赖外部的 mlir Python wheel,而是在构建时将自己的 MLIR 方言和 Python 绑定编译进包内。用户只需 import flydsl 即可使用。
核心基类 flir.MlirModule 是所有 kernel 的容器。通过 @flir.kernel 和 @flir.jit 装饰器,开发者可以轻松定义 GPU 内核和启动函数。
示例:向量加法
下面是一个使用 FlyDSL 实现向量加法的完整示例,节选自 tests/kernels/test_vec_add.py,这里做了一些简化:
# ============================================================
# 向量加法内核定义(使用 FlyDSL)
# ============================================================
class VecAddKernel(flir.MlirModule):
GPU_MODULE_NAME = "vec_kernels"
GPU_MODULE_TARGETS = [f'#rocdl.target<chip = "{gpu_arch}">']
@flir.kernel
def vec_add(self, A: MemRef, B: MemRef, C: MemRef, n: index):
# ---------- 1. 布局定义 ----------
# 线程布局:一维连续线程(THREADS_PER_BLOCK)
thr_layout = make_ordered_layout((THREADS_PER_BLOCK,), order=(0,))
# 数值布局:每个线程处理的元素序列(TILE_SIZE)
val_layout = make_ordered_layout((TILE_SIZE,), order=(0,))
# 拷贝原子:向量化宽度为 VEC_WIDTH 的加载/存储
copy_atom = make_copy_atom(f32, vector_size=VEC_WIDTH)
# 组合为 tiled copy 描述符
tiled_copy = make_tiled_copy_tv(
copy_atom, thr_layout, val_layout,
thr_shape=(THREADS_PER_BLOCK,), val_shape=(TILE_SIZE,)
)
# ---------- 2. 张量分区 ----------
# 将全局一维张量划分为块(每个块大小为 THREADS_PER_BLOCK * TILE_SIZE)
tensor_A = make_tensor(A, shape=(n,), strides=(1,))
gA = zipped_divide(tensor_A, (TILE_ELEMS,)) # TILE_ELEMS = THREADS_PER_BLOCK * TILE_SIZE
# 获取当前块 (bid_x)
blkA = gA[block_id_x]
# 获取当前线程在块内的切片(基于线程线性 ID)
thrA = tiled_copy.get_slice(tid_linear).partition_S(blkA)
# 同理处理 B、C(略)
# ---------- 3. 数据移动 ----------
# 分配寄存器片段(fragment)用于缓存数据
frgA = make_fragment_like(thrA, f32)
# 生成谓词(predicate)处理边界情况(剩余元素)
pred = generate_predicate(...) # 具体逻辑省略
# 向量化加载:从全局内存到寄存器片段
copy(tiled_copy, thrA, frgA, pred=pred)
# 向量化计算(每个线程处理 TILE_SIZE / VEC_WIDTH 次)
for iter in range(ITERS_PER_THREAD):
base = iter * VEC_WIDTH
for lane in range(VEC_WIDTH):
idx = base + lane
frgC[idx] = frgA[idx] + frgB[idx]
# 向量化存储:从寄存器片段到全局内存
copy(tiled_copy, frgC, thrC, pred=pred)
@flir.jit
def __call__(self, A, B, C, n):
# ---------- 4. 启动封装 ----------
# 计算网格尺寸(块数)
tile_elems = THREADS_PER_BLOCK * TILE_SIZE
grid_x = (n + tile_elems - 1) // tile_elems
# 调用 GPU 启动操作
flir.gpu_ext.LaunchFuncOp(
[self.GPU_MODULE_NAME, "vec_add"],
grid_size=(grid_x, 1, 1),
block_size=(THREADS_PER_BLOCK, 1, 1),
kernel_operands=[A, B, C, n]
)
这个例子清晰地展示了 FlyDSL 的三个层次(下面前三点):
- 布局定义:使用
make_ordered_layout 和 make_tiled_copy_tv 描述线程和数据的组织。
- 张量分区:用
zipped_divide 将全局张量划分为块,再通过 get_slice 和 partition_S 获取每个线程负责的切片。
- 数据移动:
copy 操作根据 tiled copy 的描述生成向量化的加载/存储指令。
- 启动封装:
__call__ 方法计算网格尺寸,并通过 LaunchFuncOp 发起内核。
六、创新点三:分层编译管道与硬件映射
FlyDSL 的编译流水线将 Python 前端生成的 MLIR 逐步降级为 GPU 可执行代码。
下图展示了从 IR 生成到二进制输出的整个流程:
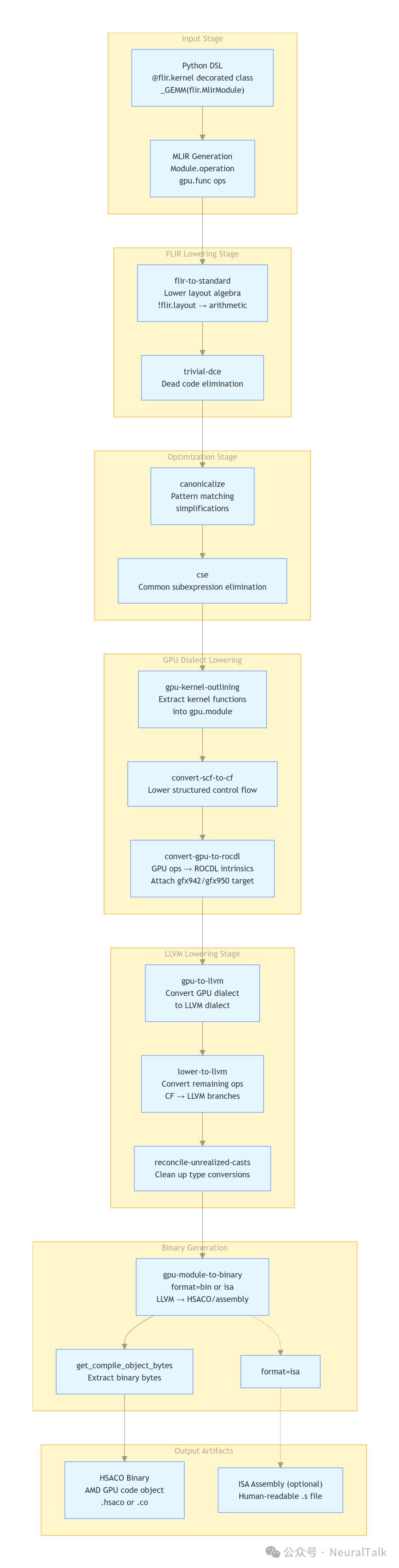
图 1 | FlyDSL 编译流水线架构。这张流程图展示了从Python DSL输入到生成AMD GPU可执行文件的完整编译流程,涵盖输入、FLIR下降、优化、GPU/LLVM下推、二进制生成等阶段,最终输出HSACO二进制与可选ISA汇编文件。
该编译流水线的关键阶段包括:
- FLIR 降级(
flir-to-standard):将布局代数操作转换为 arith 和 memref 操作。例如,flir.crd2idx 被展开为乘加链。
- GPU 内核提取(
gpu-kernel-outlining):将内核函数封装到 gpu.module 中。
- GPU 到 ROCDL 转换(
convert-gpu-to-rocdl):将通用 GPU 操作如 gpu.thread_id,映射到 AMD 特定的 rocdl 操作。
- 目标绑定(
rocdl-attach-target):设置具体的 GPU 架构,如 gfx942。
- LLVM 降级和二进制生成:最终生成 HSACO 或 ISA 文件。
这种分层设计使得 FlyDSL 可以轻松支持新的硬件特性,只需在相应层次添加新的降级模式即可。例如,对于 MI350(gfx950)新增的 mfma_scale_f32_16x16x128_f8f6f4 指令,只需在 rocdl 方言中添加对应的操作,并在降级管道中正确映射。
七、性能数据与实验分析
FlyDSL 项目在 AMD MI300 系列(gfx942)和 MI350 系列(gfx950)上进行了广泛的功能与性能测试。
7.1 各模块功能的测试状态
| 类别 |
描述 |
| MLIR 核心 |
类型解析、操作验证、基本变换 |
| FLIR 操作 |
布局代数、坐标降级 |
| GPU 后端 |
GPU 内核编译、共享内存、向量化 |
| 硬件 |
MFMA 指令在 MI300 系列上的执行 |
7.2 部分性能测试
在具体的基准测试中,FlyDSL 与 AMD 官方的 aiter(基于 Composable Kernel,CK 库)进行了对比。
- 在大形状下(如 Prefill 场景的 1024×8192×8192),FlyDSL 的性能达到了 aiter 的 98% 左右(~0.98x CK)。
- 而在小形状的 Decode 场景下(如 32×8192×8192),FlyDSL 凭借更极致的定制化布局,性能超越了 aiter,达到了约 1.03 倍速。
在 test_preshuffle_gemm.py::test_mfma_w4_flir_preshuffle 函数中,代码注释展示了 Preshuffle GEMM 性能情况,测试针对不同数据类型(FP8/FP4)和矩阵维度(M/N/K)、分块参数(tile_m/n/k)的 GEMM 运算性能,对比自研实现与 CK 内核的性能表现。
@pytest.mark.parametrize("a_dtype", ["fp8", "fp4"])
@pytest.mark.parametrize("b_dtype", ["fp4"])
@pytest.mark.parametrize(
"M, N, K, tile_m, tile_n, tile_k",
[
# MXFP4 constraints (same as CK: KPerBlock=256 fp4, NPerBlock>=128):
# tile_k >= 256 (pack_K=2), tile_n >= 128 (pack_N=2 with 4 waves)
# K must be a multiple of tile_k
# Tile configs aligned with CK kernels (see aiter gemm_a4w4_blockscale_common.py)
(32, 8192, 8192, 32, 128, 256), # decode, ~1.03x CK
pytest.param(128, 8192, 8192, 64, 128, 256, marks=pytest.mark.large_shape), # prefill, ~0.78x CK
pytest.param(1024, 8192, 8192, 64, 256, 256, marks=pytest.mark.large_shape), # prefill, ~0.98x CK
pytest.param(5133, 8192, 8192, 64, 256, 256, marks=pytest.mark.large_shape), # non-aligned M, ~0.79x CK
]
)
def test_mfma_w4_flir_preshuffle(
数据类型层面,FP4 作为主要测试精度,FP8 为对照维度;数据规模上,N、K 固定为8192,M 从 32 扩展至 5133(含非对齐场景)。性能表现上:
- decode场景(M=32)性能最优,达CK内核的1.03倍;
- prefill场景中,M=128时性能仅为CK的0.78倍,M=1024时回升至0.98倍
- 非对齐M=5133的prefill场景性能降至CK的0.79倍。
可见:
- FP4/FP8精度下,decode小维度(M=32)性能优于CK内核,prefill场景整体弱于CK;
- prefill场景中,M维度增大(128→1024)性能有所回升,但非对齐维度(5133)会显著拉低性能;
- 矩阵维度对齐性与规模是影响GEMM运算性能的核心因素。
虽然在大 Batch 下还有微调空间,但在对延迟极度敏感的 Decode 阶段,FlyDSL 的显式布局展现出了优势。
这一性能提升的原因可以归结为:
- 精确的线程/值布局:FlyDSL 允许开发者根据硬件特性(例如 MI350/gfx950 特有的
mfma_scale_f32_16x16x128_f8f6f4 指令)调整线程块内每个线程的工作负载,特别是针对超长 K 维度的特殊分块约束,做出了超越自动化编译器的精准切分。
- LDS XOR Swizzle:通过显式指定 swizzle 模式,避免了多个线程访问同一 bank,使 LDS 带宽接近理论峰值。
- 指令级调度提示:通过
rocdl.sched_* 操作,开发者可以引导编译器安排 MFMA 指令与内存加载的重叠,隐藏内存延迟。
总结与展望
FlyDSL 为 GPU 编程提供了一条新的路径:它不像 CUDA 那样完全暴露底层细节,也不像 Triton 那样完全抽象,而是将布局控制权作为第一公民,让开发者在 Python 中精确表达性能关键型内核所需的并行模式。
它的创新之处在于:
- 将 CuTe 的布局代数系统化并融入 MLIR 类型系统,使得布局操作可以在编译时推导和优化。
- 提供 Python 前端,但保留 C++级别的控制力,通过装饰器和 lambda 类型注解实现延迟类型解析。
- 构建完整的编译器管道,从高级 DSL 直达 ROCm 二进制,并通过缓存机制加速开发迭代。
虽然 FlyDSL 目前仍是实验性项目,尚未正式集成到 ROCm 发行版中,但它已经展示了在 AMD GPU 上实现极致性能的潜力。
未来,随着更多硬件特性(如 MI350 的 MXFP4 支持)的加入,FlyDSL 有望成为 AMD 生态中高性能内核开发的重要工具。对于希望深入挖掘硬件性能潜力的开发者和研究者,这是一个值得持续关注的 C++ 与编译器技术结合的创新方向。像云栈社区这样的技术论坛,也正是此类深度技术探索和交流的理想平台。
 发表于 2026-2-23 01:54:51
|
查看: 338|
回复: 0
发表于 2026-2-23 01:54:51
|
查看: 338|
回复: 0
