在Python中,数值与字符串是两种最基础且最常用的数据类型。得益于语言本身的设计,这两种类型上手非常简单,但也隐藏着不少值得深入探究的细节和最佳实践。
Python的整型(int)消除了底层硬件的复杂性。你无需关心“有符号”、“无符号”或“32位”、“64位”等概念,可以放心处理任意大小的整数,完全不必担心溢出问题。
# 无符号 64 位整型的最大值
>>> 2 ** 64 - 1
18446744073709551615
# 直接乘上 1000 也没问题,永不溢出
>>> 18446744073709551615 * 1000
18446744073709551615000
这里的**是Python的幂运算符。
Python的字符串(str)原生支持Unicode标准,处理多语言文本(包括中文)非常方便。
>>> s = ‘Hello,中文’
>>> type(s)
<class ‘str’>
>>> print(s)
Hello,中文
除了文本字符串,Python中还存在一种与之密切相关的字节串类型(bytes)。
1. 基础知识精讲
1.1. 数值类型基础
Python内置了三种数值类型:
- 整型 (
int)
- 浮点型 (
float)
- 复数类型 (
complex)
# 定义整型
>>> score = 100
# 定义浮点型
>>> temp = 37.2
# 定义复数类型
>>> com = 1 + 2j
最常用的是int和float,它们之间可以使用内置函数进行转换:
# int(): float -> int
>>> int(temp)
37
# float(): int -> float
>>> float(score)
100.0
在定义数值字面量时,如果数字较长,可以使用下划线_作为视觉分隔符以增强可读性。
>>> i = 1_000_000
>>> i + 10
1000010
>>> pi = 3.141_592_653_589_793
>>> print(pi)
3.141592653589793
分隔位置无硬性要求,通常按千分位(每3位)进行分隔。
浮点数精度陷阱
计算机使用二进制表示所有数字。将十进制小数转换为二进制时,常会遇到无限循环的情况。以0.1为例,其二进制表示为0.0001100110011...,是一个无限循环小数。
由于计算机存储空间有限,Python的float类型(64位双精度浮点数)只能存储53位有效数字,超出部分会进行舍入,从而产生微小的表示误差。这直接导致了经典的精度问题:
# 输出: 0.30000000000000004
>>> print(0.1 + 0.2)
0.30000000000000004
0.00000000000000004就是由这种截断和舍入误差造成的。
如果业务场景要求精确的十进制运算,可以使用标准库中的decimal模块。它能提供任意精度的十进制数学运算。
>>> from decimal import Decimal
# 注意:必须使用字符串来初始化,以避免提前引入浮点误差
>>> Decimal('0.1') + Decimal('0.2')
Decimal('0.3')
务必使用字符串数字初始化Decimal对象。如果直接传入浮点数,在构造对象之前精度就已经损失了。
# 错误示例:浮点数精度已丢失
>>> Decimal(0.1)
Decimal('0.1000000000000000055511151231257827021181583404541015625')
1.2. 布尔值也是数字
布尔类型(bool)是整型(int)的子类。在绝大多数上下文中,True和False可以直接当作1和0使用。这个特性常用于简化条件计数。
>>> numbers = [1, 2, 4, 5, 7]
# 计算列表中偶数的个数
>>> count = sum(i % 2 == 0 for i in numbers)
>>> print(count)
2
1.3. 字符串的常用操作
作为序列操作
字符串是一种序列类型,支持遍历、索引和切片等操作。
>>> s = ‘Hello world!’
>>> for c in s:
... print(c)
...
H
e
l
l
o
...
>>> s[1:3]
‘el’
反转字符串可以使用切片或reversed()函数。
# 切片,步长为-1表示反向
>>> s[::-1]
‘!dlrow olleH’
# 使用 reversed 函数
>>> ”.join(reversed(s))
‘!dlrow olleH’
字符串格式化
Python支持多种字符串格式化方式,演进过程如下:
- C风格:使用
%操作符。
str.format方法(Python 2.6+)。- f-string(Python 3.6+)。
>>> username, score = ‘piglei’, 100
# 1. C 风格
>>> print(‘Welcome %s, your score is %d’ % (username, score))
Welcome piglei, your score is 100
# 2. str.format
>>> print(‘Welcome {}, your score is {:d}’.format(username, score))
Welcome piglei, your score is 100
# 3. f-string (最推荐)
>>> print(f‘Welcome {username}, your score is {score:d}’)
Welcome piglei, your score is 100
str.format支持通过位置参数重复使用变量,在某些场景下比f-string更灵活。
>>> print(‘{0}: name={0} score={1}’.format(username, score))
piglei: name=piglei score=100
日常开发中,建议以f-string为主,str.format为辅,基本可以满足所有格式化需求。如果你想系统提升在Python方面的技能,深入理解这些基础特性至关重要。
字符串拼接
拼接多个字符串主要有两种方法:
join()方法:将字符串片段放入列表,最后用””.join()合并。+=操作符:直接累加。
过去普遍认为,由于字符串是不可变对象,使用+=会频繁创建新对象,效率低下。然而,自Python 2.2起,解释器对+=操作进行了持续优化。在现代Python版本中,+=拼接的性能已经与join()方法不相上下。因此,在可读性优先的情况下,可以放心使用+=。
1.4. 不常用但好用的字符串方法
| 方法名称 |
作用 |
示例 |
s.isdigit() |
判断字符串s是否只包含数字 |
>>>‘123foo’.isdigit()
False |
str.partition(sep) |
按分隔符sep将字符串分为三部分:(前段, 分隔符, 后段)。若未找到分隔符,则后段为空字符串。相比split有时更优雅。 |
>>> s.partition(‘:’)
(‘key‘, ‘:’, ‘value’) |
str.split(sep) |
按分隔符sep拆分字符串,返回列表。 |
>>> ‘a,b,c’.split(‘,’)
[‘a’, ‘b’, ‘c’] |
str.translate(table) |
根据转换表一次性替换多个字符,比多次调用replace()更高效。 |
>>> s = ‘Hello, world.’
>>> table = s.maketrans(‘.,’, ‘,。’)
>>> s.translate(table)
‘Hello, world。’ |
1.5. 字符串与字节串
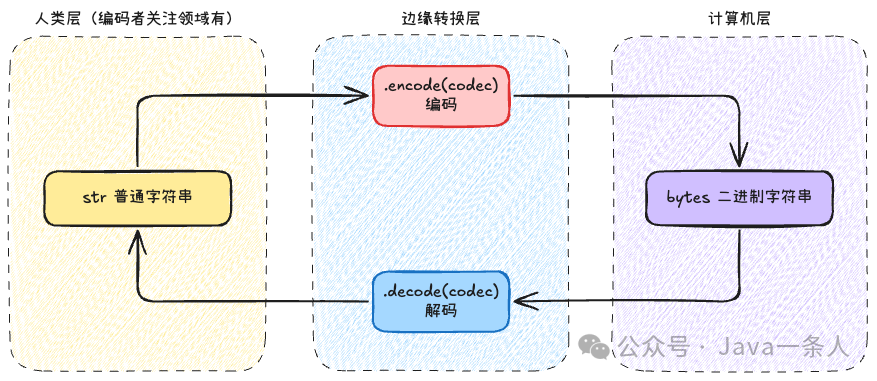
广义的“字符串”可分为两类:
- 字符串 (
str):给人看的文本,采用Unicode编码。可通过.encode()方法编码为字节串。
- 字节串 (
bytes):给计算机看的二进制数据,包含特定的字符编码(如UTF-8)。可通过.decode()方法解码为字符串。
# 字符串 (str)
>>> str_obj = ‘Hello, 世界’
>>> type(str_obj)
<class ‘str’>
# 编码为字节串 (bytes)
>>> bin_str = str_obj.encode(‘UTF-8’) # 不指定则默认为 UTF-8
>>> type(bin_str)
<class ‘bytes’>
>>> bin_str
b‘Hello, \xe4\xb8\x96\xe7\x95\x8c’
# 解码回字符串
>>> bin_str.decode()
‘Hello, 世界’
最佳实践是:在程序内部尽量只操作str类型。 仅在以下两种边界场景处理bytes:
- 从文件、网络等外部数据源读取原始字节数据,需立即解码为
str。
- 将处理好的
str数据写入文件、网络等外部存储前,需编码为bytes。
例如,写入文件时,编码过程通常是隐式发生的:
# open函数通过encoding参数指定编码,默认即为UTF-8
with open(‘output.txt’, ‘w’, encoding=‘UTF-8’) as fp:
fp.write(‘一些文本’) # 内部会自动编码
2. 实践案例与编程建议
2.1. 用枚举和常量替代魔法数字
在代码中直接使用未经解释的数字(魔法数字)会严重降低可读性。例如,以下代码中的13和3令人困惑:
def add_daily_points(user):
if user.type == 13: # 这是什么用户?
return
if user.type == 3: # 这又是什么?
user.points += 120
return
user.points += 100
更好的做法是使用enum模块定义枚举,并用常量命名有意义的值:
from enum import Enum
class UserType(int, Enum):
VIP = 3
BANNED = 13
DAILY_POINTS_REWARDS = 100
VIP_EXTRA_POINTS = 20
def add_daily_points(user):
if user.type == UserType.BANNED:
return
if user.type == UserType.VIP:
user.points += DAILY_POINTS_REWARDS + VIP_EXTRA_POINTS
return
user.points += DAILY_POINTS_REWARDS
这样不仅意图清晰,也减少了因数字写错导致的bug。
2.2. 避免手动拼接结构化字符串
对于SQL、XML、JSON等具有严格结构的字符串,手动拼接是错误且危险的做法。它难以维护、容易出错,且存在安全风险(如SQL注入)。
原始的字符串拼接方式:
def fetch_users(conn, min_level=None, gender=None):
statement = “SELECT id, name FROM users WHERE 1=1”
params = []
if min_level is not None:
statement += “ AND level >= ?”
params.append(min_level)
# … 更多条件拼接
return list(conn.execute(statement, params))
应使用专用的库来构建。例如,对于SQL,可以使用SQLAlchemy这样的ORM或查询构建器:
from sqlalchemy import select
def fetch_users_v2(conn, min_level=None):
query = select([users.c.id, users.c.name])
if min_level != None:
query = query.where(users.c.level >= min_level)
return list(conn.execute(query))
对于非结构化的文本模板(如邮件、报告),也应优先考虑使用模板引擎(如Jinja2),而非手动拼接。
2.3. 利用“常量折叠”保持可读性
不必在代码中预先计算常量表达式。Python的编译器会在编译阶段进行“常量折叠”(Constant Folding),将如11 * 24 * 3600这样的表达式直接计算结果950400存入字节码。因此,两者在运行时性能完全一致,但前者可读性更高。
# 推荐:意图明确
if delta_seconds > 11 * 24 * 3600:
return
# 不推荐:意义不明
if delta_seconds > 950400:
return
可以使用dis模块查看字节码验证这一点。
2.4. 处理多行字符串的可读性
当字符串字面量很长时,为了符合代码行宽限制,可以将其用括号括起并分多行书写,Python会自动将其合并。
s = (“这是一个非常长的字符串,它被分成了”
“两行来书写,但实际是一个字符串。”)
在已有缩进的代码块中定义多行字符串(如三重引号字符串)时,缩进会成为字符串的一部分。可以使用textwrap.dedent()来移除每行左侧共同的空白缩进。
from textwrap import dedent
def main():
if user.is_active:
message = dedent(“””
Welcome, today’s movie list:
- Jaw (1975)
- The Shining (1980)
“””)
print(message)
2.5. 善用以 r 开头的逆序方法
大部分字符串方法从左向右处理。Python也提供了一系列以r开头的“逆序”方法,从右向左处理,如rsplit()、rpartition()、rfind()等。在特定场景下(例如从路径中提取最后一部分),使用逆序方法能使代码更简洁直观,这有时也是一种优雅的算法思维应用。
# 使用 rsplit 方便地获取文件扩展名
>>> filepath = ‘/home/user/data/file.txt’
>>> filepath.rsplit(‘.’, 1)[-1]
‘txt’
 发表于 2025-12-25 11:12:15
|
查看: 204|
回复: 0
发表于 2025-12-25 11:12:15
|
查看: 204|
回复: 0
