在设计Flash的读写管理时,我们主要需要考虑几个关键点:
- Flash的最小擦除单位
- Flash的最小写入单位
- 擦写次数管理,即磨损均衡
如果数据写入频率很低,甚至基本无需更新,可以采用最直接的方法:每次都在同一位置写入数据。尽管这会导致每次更新都需要整块擦除,处理起来有些繁琐,但实现方案相对简单。
然而,如果面临的是较为频繁且类型多样的数据写入,由于Flash的物理特性和有限的擦写寿命,频繁地对同一区域进行擦写将导致该区域快速损坏,进而影响应用功能。针对这种情况,我们可以考虑采用追加记录的方式来均衡整个Flash的磨损。核心思想是:每次写入数据时,不再是覆盖更新,而是直接在后续空闲区域进行追加。
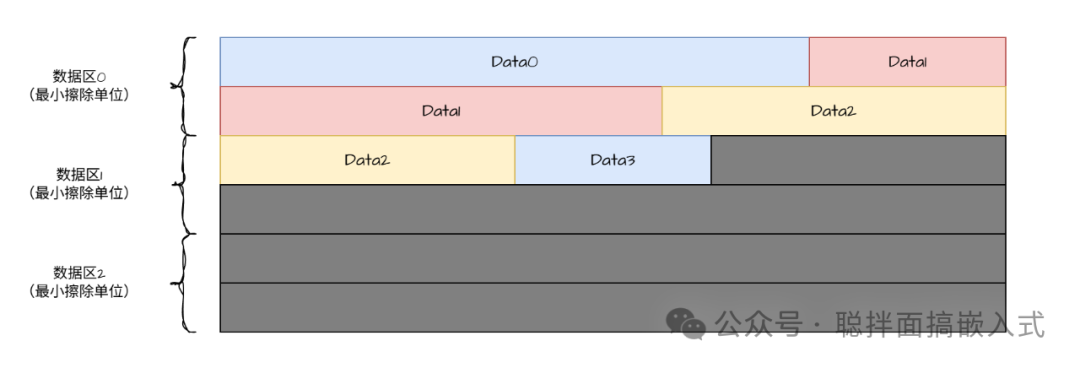
如上图所示,我们使用了三个数据区来模拟数据更新过程。新数据会紧随旧数据之后无缝写入。这种做法的好处在于,当Flash的一个区块被整体擦除后,无需反复擦除同一位置,只需向后顺序写入即可,从而最大限度地利用了Flash的存储资源,并实现了磨损均衡。
当然,这种写入方式会丢失数据的“存放地图”。因此,我们需要对数据进行打包,并附加统一的标签(Header)来标识数据。如下图所示,一条完整的数据记录包含了ID、序列号(SN)、数据长度、CRC校验值以及实际数据负载。我们将ID等信息称为数据的“头标签”,正是依靠这些头标签,我们才能在连续的存储空间中定位到特定数据。
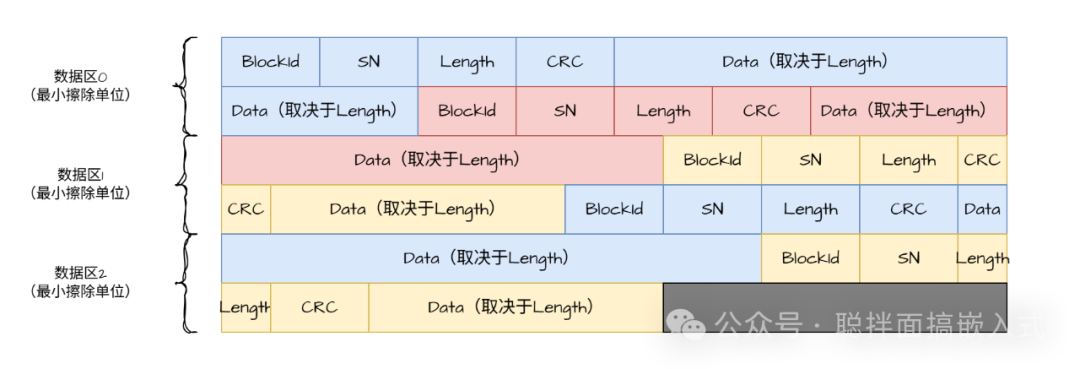
多类型数据管理
上图中用不同颜色区分的数据块代表了不同类型的数据。图中特意将数据表现为不同长度,以说明其通用性。我们要找到目标数据的方法非常直观:
- 从存储区的起始位置读取第一个数据的头标签,判断其ID是否为目标数据。如果是,则可直接读取其后数据。
- 如果不是,则根据头标签中记录的
数据长度信息,计算出下一个数据记录的起始位置。
- 跳转到该位置,读取下一个数据的头标签,并重复上述判断过程。
处理数据区写满的情况
在实际应用中,为数据分配的存储区域不可能是无限大的。采用追加方式存储,总会遇到存储区被写满的时刻。
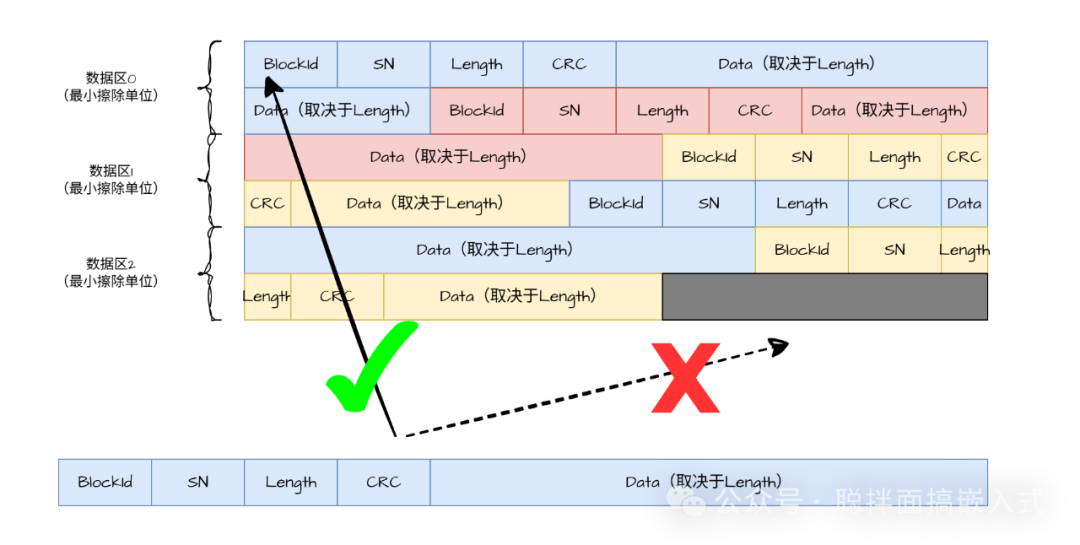
如上图所示,当试图继续追加数据时,剩余空间已不足以存放一条完整的新数据记录。显然,此时我们需要循环利用最开始的数据区域。这种循环利用机制能够保证数据可以“无限”地存储下去。
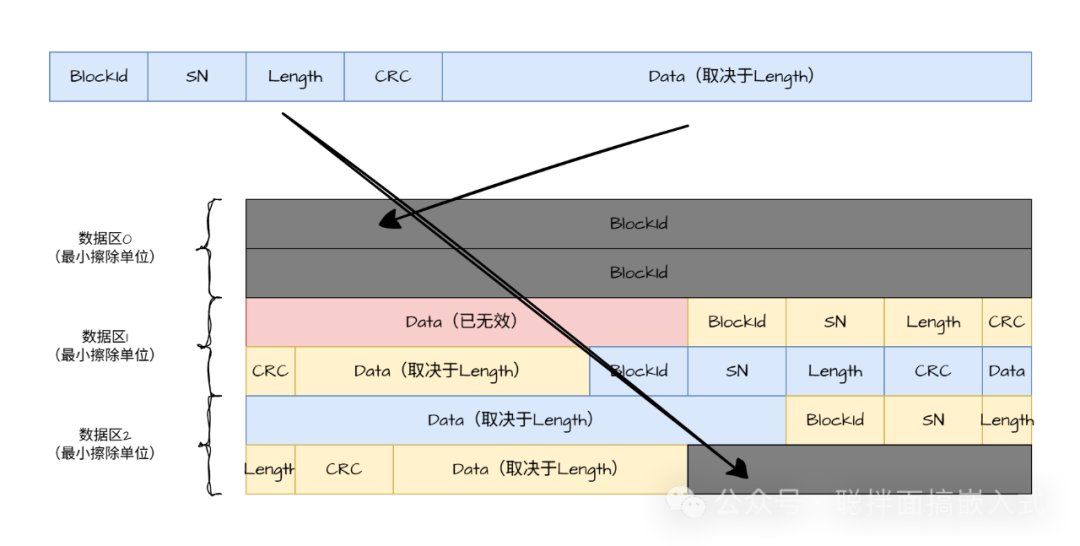
不过,在重新利用起始区域时,必须先进行擦除操作。擦除后,存储在该区域的原有数据将失效,其完整性被破坏。这引出了一个关键问题:当存储区循环写回起点后,我们该如何定位数据?因为起始区的部分数据可能已经被新数据覆盖或处于擦除状态。
因此,我们需要放弃从绝对起始点开始正向遍历的策略,转而采用逆向追溯。
引入逆向追溯地址指针
为了解决循环覆盖后的定位问题,我们为每条数据记录增加一个“上一个数据的地址”标签。同时,在上下文中(如RAM)始终保存着当前最新数据的地址。查找流程变为:
- 根据保存的最新数据地址,读取其头标签,判断ID是否匹配。
- 如果不匹配,则根据该记录中“上一个数据的地址”标签,定位到前一条数据记录。
- 重复此过程,直至找到目标数据或遍历完所有有效记录。
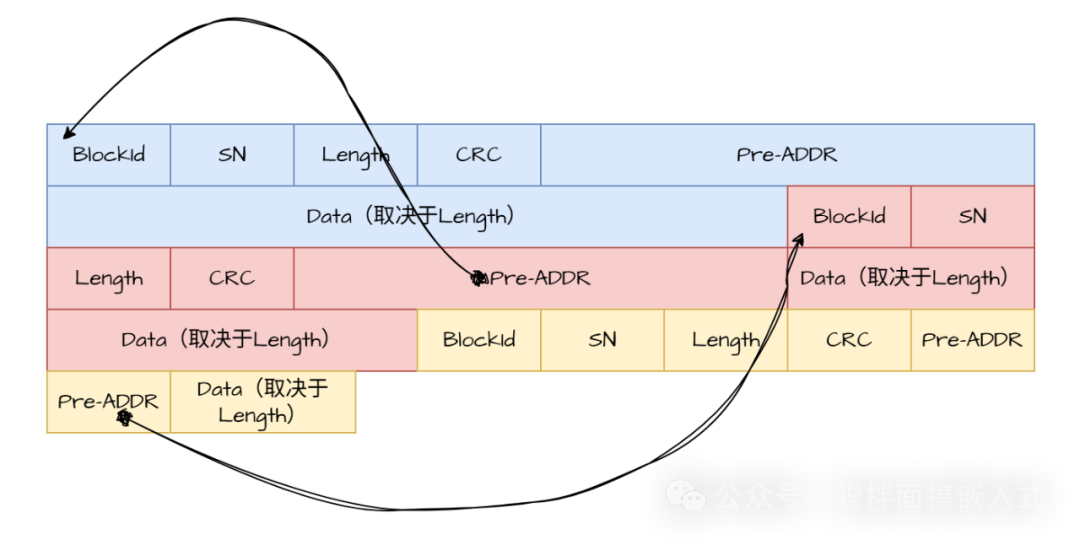
逆向追溯的好处在于,无论数据区被循环覆盖了多少次,我们始终能从最新的数据记录开始,向前追溯所有历史有效数据。这种设计思想与链表数据结构有异曲同工之妙,确保了数据链的连贯性。
异常处理机制
由于引入了地址指针,我们必须对指针的有效性进行判定。所有地址必须在预设的存储区地址范围内。如果读取到的地址超出此范围,则说明出现了错误。
主要存在两种异常情况:
- 上下文丢失:保存在上下文(如电池供电的RAM)中的“当前最新数据地址”无效(不在范围内)。这种情况发生概率极低,但一旦发生是致命的,因为它将导致整个数据链无法追溯。针对此情况,需要根据应用的重要性酌情考虑恢复策略。
- 数据链损坏:在向前追溯的过程中,发现某条记录的地址异常或其CRC校验失败。此时应停止追溯,因为后续的数据链可能已经损坏。
在安全性要求较高的应用中,即使对于情况一,我们也需要设计一些补救措施,例如通过遍历存储区来重建数据链,以使系统不至于完全崩溃。
增加数据间隔符以辅助恢复
为了在上述异常情况下能够重新定位数据,我们可以引入数据间隔符。
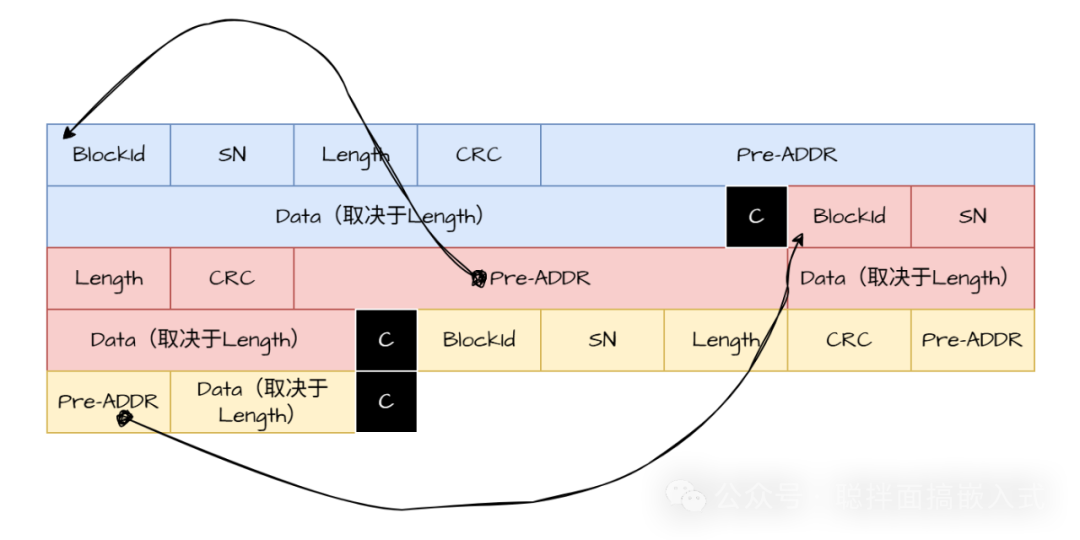
当上下文中记录的最新地址丢失时,我们可以遍历整个数据存储区,寻找最后一个有效的“数据间隔符”(一个预先定义的固定字符或模式)。找到后,从其位置向后检查数据的完整性(通过CRC校验)。如果完整性验证通过,即可将该位置判定为最新的有效数据位置,并据此恢复上下文。值得注意的是,下一个待写入地址应设置为下一个存储区块的起始处(并确保该区块已提前擦除),否则无法避免后续写入导致的数据错乱。
拓展:分区管理数据结构
上述的追加型存储结构在应对数据种类繁多且数据量大的场景时,查询效率可能成为瓶颈,因为每次查询都可能需要遍历较长的数据链。如果硬件平台资源允许,可以考虑采用分区管理策略:将Flash存储区划分为多个独立的子区,每个子区专用于存储同一种类型的数据。这样,将数据ID与固定分区绑定后,查询时可以直接跳转到对应分区进行操作,速度更快。这种设计思路类似于文件系统中一个文件独占连续磁盘扇区的概念。
总结
设计一个用于Flash的简易数据存储管理系统,从宏观上看,也是在构建一种微型的、专用的“文件系统”。这里的“文件”就是一条条的原始数据记录。这种在资源受限环境下对存储进行高效、可靠管理的设计,是嵌入式系统开发中的核心技能之一。感兴趣的读者可以深入研究计算机文件系统的底层存储设计,以获得更多启发。
 发表于 2025-12-25 11:08:19
|
查看: 233|
回复: 0
发表于 2025-12-25 11:08:19
|
查看: 233|
回复: 0
