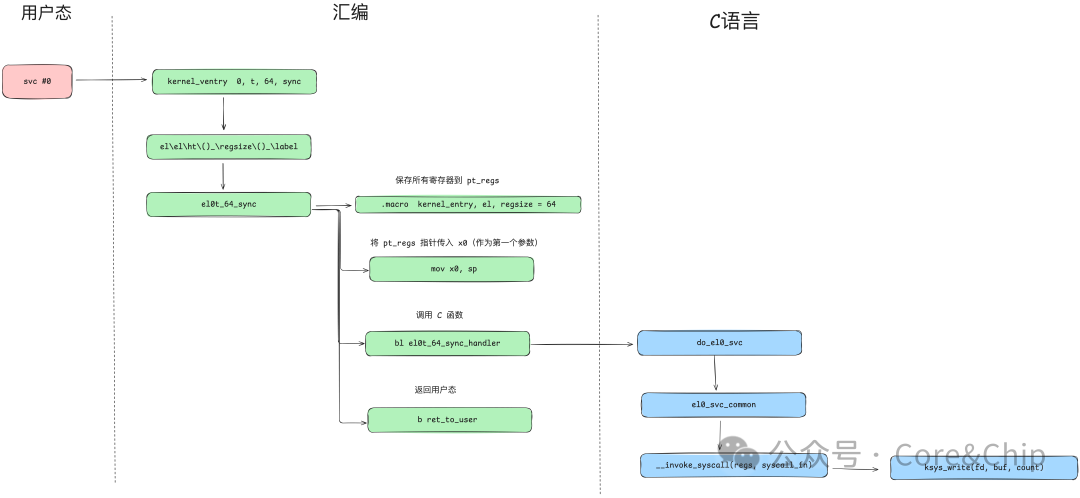
在前面的章节中,我们已经分析了 glibc 是如何封装系统调用,并最终在 ARM64 平台上通过 svc #0 指令触发内核陷入的。从这一刻开始,系统调用流程正式离开用户态代码,进入 CPU 和内核共同完成的一段执行路径。
从 svc #0 到系统调用返回用户态,这个过程主要有以下几个阶段:
- CPU对异常的路由
- 内核汇编入口对异常的接管
- 内核 C 代码对系统调用的分发与执行
下面我们就按照这个顺序,对整个流程进行一次完整梳理。
图1:从用户态到内核的系统调用流程概览
1. 异常向量表:entry.S 如何接住异常
我们上节提到过触发系统调用的 svc #0 是一个同步异常,发生异常后程序会从用户态切换到内核态。一个明确的结论是:进入到Linux内核的第一行代码是在 entry.S 中。
那么 entry.S 是如何接住这个异常的呢?这个过程中发生了什么?这其中涉及到CPU架构对于异常的路由机制。
ARMv8-A 架构中定义了 VBAR_EL1 -- VBAR_EL3 共三个异常向量基址寄存器,用于存放EL1 - EL3的异常向量基地址。那么什么是异常向量以及异常向量表?
异常向量(Exception Vector)是处理器架构中用于识别和处理不同类型异常的一个机制。每个异常类型都有一个唯一的异常向量,处理器通过该向量确定如何处理特定的异常。
异常发生时,处理器必须执行与异常相对应的处理程序代码。内存中存储处理程序的位置称为异常向量。在ARM架构中,异常向量存储在一个表中,称为异常向量表。
简单来说,异常向量是一个内存地址,这个地址中存放了异常处理程序,ARM架构定义了这个异常向量表。我将异常向量以及异常向量表的定义放在下面,内容来自于官网ARM v8架构手册。
图2:AArch64异常向量表定义

图3:异常类型对应的偏移量表
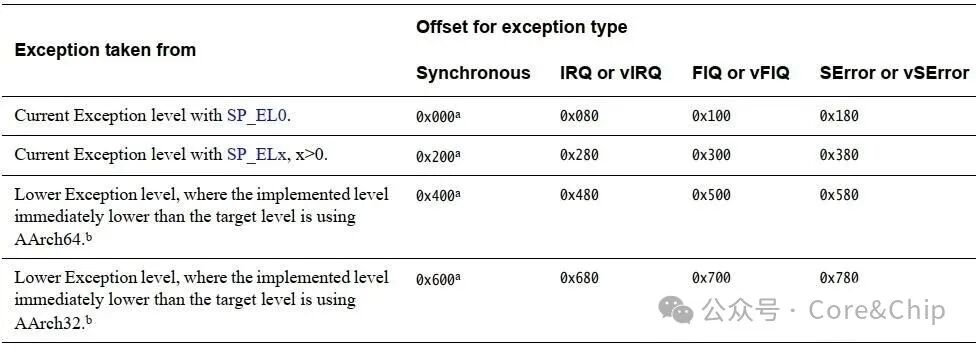
可以看到armv8中根据发生时异常的位置与异常类型定义了4组,形成了一共16个异常的入口,并为每个入口都指定了offset。对于这个向量表官方的定义与翻译网上有很多资料,我就不再复制了,较为抽象也不便于理解,我直接代入我们具体的案例来分析。
第一组表示如果发生异常并不会导致异常等级切换,并且使用的栈指针是 SP_EL0 在 Linux ARM64 中。内核始终在 EL1 使用 SP_EL1,因此该入口在实际系统中几乎不会被使用。其实几乎所有的操作系统都不会支持在用户态处理异常,ARM定义这组异常向量只是为了保证系统对称性,所以这一组可以忽略。
第四组表示的是32位的异常处理,我们主要分析的是Aarch64架构,所以常用的就是第二和第三组。第二第三组都表示会在 EL1 中也就是内核态来处理异常,区别在于:
前者表示当前等级发生也就是内核态发生的异常,对应的例如有空指针,缺页异常等
后者表示低一级也就是用户态发生的异常,我们这章讲的系统调用就属于这一类。
这两者本质区别在于发生异常后是否需要切换异常级 / 栈 / 地址空间语义,对应的后续流程会有所区别。
Linux内核中对于异常向量表也是和ARMv8手册中的定义是一一对应的,提供了16个异常入口。
Linux 在 entry.S 中定义了异常向量表 vectors,并在内核启动早期由初始化代码将 vectors 的地址写入 VBAR_EL1。此后当异常发生时,CPU 根据架构规则,以 VBAR_EL1 为基址并加上固定的 offset,跳转到对应的异常入口执行。关于 Kernel 和系统底层的更多知识,你可以在 网络/系统 板块找到深入的讨论。
图4:内核异常向量入口定义代码片段
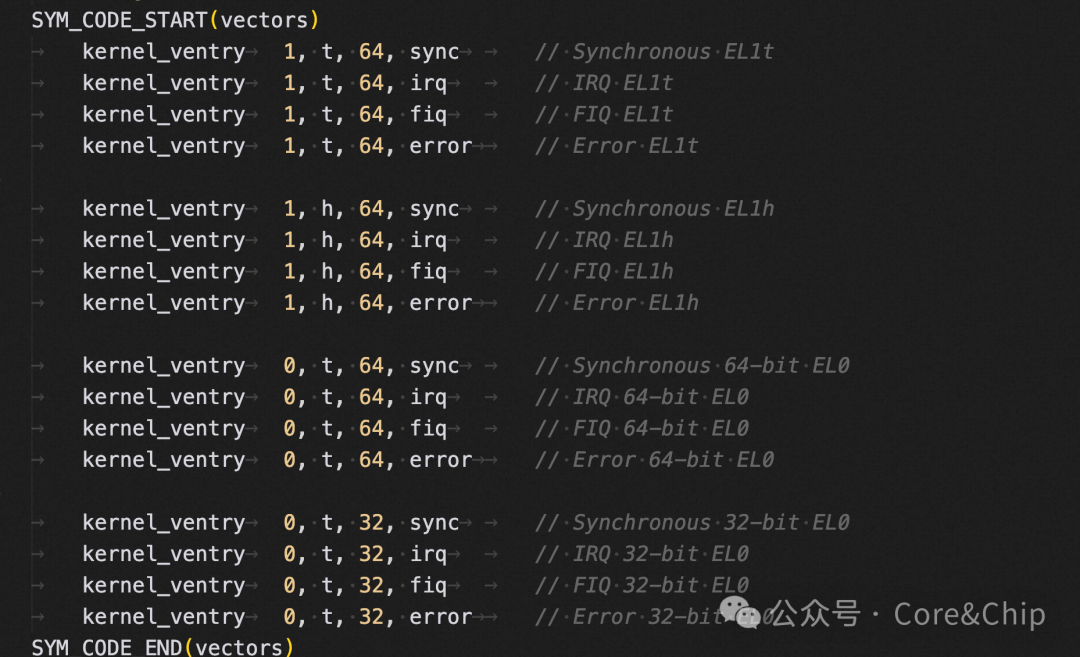
对于我们arm64架构则目录是 arch/arm64/kernel/entry.S,来自 EL0 的 64 位同步异常 会命中这一项:
/* arch/arm64/kernel/entry.S */
SYM_CODE_START(vectors)
...
kernel_ventry 0, t, 64, sync // Synchronous 64-bit EL0
kernel_ventry 0, t, 64, irq
kernel_ventry 0, t, 64, fiq
kernel_ventry 0, t, 64, error
...
SYM_CODE_END(vectors)
2. 汇编的处理:保存上下文的具象理解
异常向量入口做一些准备工作如对齐边界、预留占空间、检查栈溢出的工作后,调用:
b el\el\ht\()_\regsize\()_\label
这是汇编宏的参数拼接语法。对于 kernel_ventry 0, t, 64, sync,参数拼接如下:
- \el = 0
- \ht = t
- \regsize = 64
- \label = sync
拼接结果:el + 0 + t + + 64 + + sync = el0t_64_sync所以展开后就是:
b el0t_64_sync
而 el0t_64_sync 又会进一步展开,展开过程就不再讨论了,直接展示最终的结果:
el0t_64_sync:
kernel_entry 0, 64 // 保存所有寄存器到 pt_regs
mov x0, sp // 将 pt_regs 指针传入 x0(作为第一个参数)
bl el0t_64_sync_handler // 调用 C 函数
b ret_to_user // 返回用户态
而 kernel_entry 主要工作是保存各类寄存器,这个操作其实就是我们常说的保存上下文,我将部分代码放在下方,并加了注释,有兴趣的稍作了解即可。
.macro kernel_entry, el, regsize = 64
...
// 1. 保存所有通用寄存器
stp x0, x1, [sp, #16 * 0]
stp x2, x3, [sp, #16 * 1]
stp x4, x5, [sp, #16 * 2]
stp x6, x7, [sp, #16 * 3]
......
......
stp x26, x27, [sp, #16 * 13]
stp x28, x29, [sp, #16 * 14]
.if \el == 0
// 2. EL0 特殊处理
clear_gp_regs
mrs x21, sp_el0 ← 保存用户栈指针
ldr_this_cpu tsk, __entry_task, x20
msr sp_el0, tsk
...
.endif
// 3. 保存异常相关寄存器
mrs x22, elr_el1 ← 读取异常返回地址
mrs x23, spsr_el1 ← 读取保存的处理器状态
stp lr, x21, [sp, #S_LR] ← 保存 LR 和用户栈指针
// 4. 创建栈帧记录
.if \el == 0
stp xzr, xzr, [sp, #S_STACKFRAME]
...
.endif
// 5. 保存 PC 和 PSTATE
stp x22, x23, [sp, #S_PC] ← 保存 ELR 和 SPSR 到 pt_regs
// 6. 初始化系统调用号
.if \el == 0
mov w21, #NO_SYSCALL
str w21, [sp, #S_SYSCALLNO]
.endif
...
.endm
保存完上下文之后就会进入到 el0t_64_sync_handler,最后处理完成后通过 ret_to_user 再返回用户态。
3. C阶段:系统调用的分发与执行
从 el0t_64_sync_handler 之后就进入 C 代码了,系统调用流程正式进入内核通用逻辑阶段。通过读取esr寄存器可以获取到本次异常的类型,实现异常处理分发,对于我们的系统调用就进入到 el0_svc。
图5:根据ESR寄存器进行异常分发的C代码
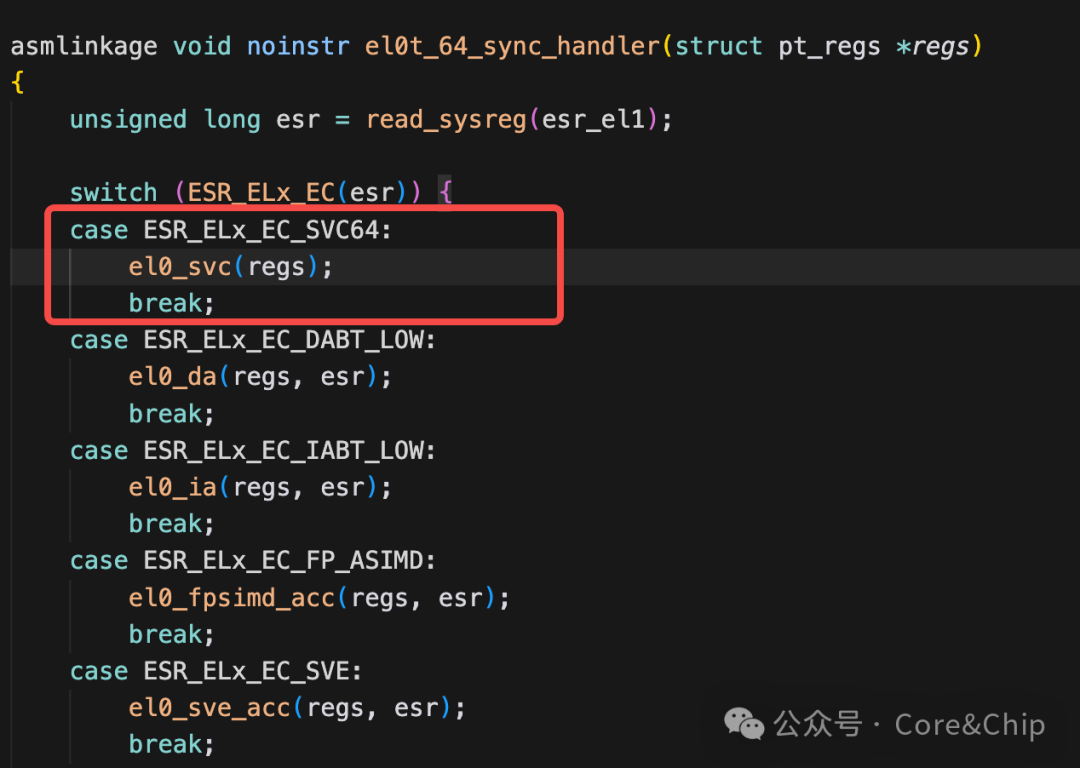
3.1 入口函数:do_el0_svc()
void do_el0_svc(struct pt_regs *regs)
{
el0_svc_common(regs, regs->regs[8], __NR_syscalls, sys_call_table);
}
el0_svc_common
|--invoke_syscall(regs, syscall_fn);
regs->regs[8] 包含系统调用号,x8寄存器的值,对于我们举例write来说就是64,这在上节glibc中的已经做了介绍了sys_call_table 是系统调用表,包含所有系统调用的函数指针
do_el0_svc 调用了 el0_svc_common 函数并将系统调用表以及调用号传递进去,el0_svc_common 是系统调用的核心处理逻辑函数,其中最关键的是 invoke_syscall,我们重点看一下:
static void invoke_syscall(struct pt_regs *regs, unsigned int scno,
unsigned int sc_nr,
const syscall_fn_t syscall_table[])
{
......
// 假设 scno = 64 (__NR_write)
if (scno < sc_nr) {
syscall_fn_t syscall_fn;
// 1. array_index_nospec(64, __NR_syscalls) 返回 64(安全处理)
// 2. sys_call_table[64] 获取数组第 64 个元素
// 3. 这个元素的值是 __arm64_sys_write 函数指针
syscall_fn = syscall_table[array_index_nospec(scno, sc_nr)];
// syscall_fn 现在指向 __arm64_sys_write 函数
ret = __invoke_syscall(regs, syscall_fn);
} else {
ret = do_ni_syscall(regs, scno);
}
......
}
这里通过系统调用号(64)从 sys_call_table 数组中索引到对应的系统调用处理函数。系统调用表通过包含头文件自动初始化,初始化展开后是这样的:
const syscall_fn_t sys_call_table[__NR_syscalls] = {
[0] = __arm64_sys_ni_syscall,
[1] = __arm64_sys_ni_syscall,
...
[63] = __arm64_sys_read,
[64] = __arm64_sys_write, // ← write 系统调用
[65] = __arm64_sys_readv,
...
};
对于write系统调用,会找到 __arm64_sys_write 会。
3.2 系统调用实现
但其实 __arm64_sys_write 也是一个封装函数,经过编译和展开之后最后会调用到 __do_sys_write。
而 __do_sys_write 来源于:SYSCALL_DEFINE3(write, ...)
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
return ksys_write(fd, buf, count);
}
SYSCALL_DEFINE3 宏会展开为:
static inline long __do_sys_write(unsigned int fd, const char __user *buf, size_t count)
{
return ksys_write(fd, buf, count); // 调用 ksys_write
}
ksys_write 最终内部会调用到 vfs_write,后面就到了文件系统的工作了,我们这章就不去涉及了。
总结
在这一节中,我们从 ARM64 架构视角,完整梳理了一次系统调用在内核中的真实执行路径。
从用户态执行 svc #0 开始,系统调用首先以同步异常的形式被 CPU 接管,通过 VBAR_EL1 跳转到 entry.S 中对应的异常向量入口。随后在汇编阶段完成上下文保存,将通用寄存器、用户栈指针以及异常相关寄存器统一整理为 pt_regs,为后续内核逻辑提供完整的执行现场。
在进入 C 代码后,内核根据 ESR_EL1 判断异常类型,将系统调用分发到 do_el0_svc,并通过系统调用号索引 sys_call_table,最终找到对应的系统调用实现函数。以 write 为例,系统调用会从 __arm64_sys_write 逐步展开,最终进入 ksys_write,并继续向文件系统层传递。
系统调用我想到这里就暂时告一段落了,这章虽然只有三节,但是我认为这些内容充分掌握了对于我们BSP工程师来说在系统调用这一块已经够用了。如果关于系统调用大家还有什么感兴趣的话题,欢迎在技术社区如 云栈社区 进行更深入的讨论。
我们这个系列后面大的模块还会包括文件系统、平台总线、中断、设备树、并发与竞争等BSP工程师必须掌握的内核知识。
 发表于 2025-12-30 01:46:15
|
查看: 261|
回复: 0
发表于 2025-12-30 01:46:15
|
查看: 261|
回复: 0
