PostgreSQL 18 的异步 IO 和跳跃扫描让数据库性能飙升,很多场景下 Redis 缓存层变得可选。三年维护的 847 行缓存代码,一周内被三个人独立删除。
那天代码评审会上,我正准备给新来的实习生讲解我们“精心设计”的缓存架构,屏幕上突然弹出一条消息——技术负责人在群里扔了张截图,是 PostgreSQL 18 的性能测试报告。我扫了一眼数字,愣住了。实习生凑过来看了看,问了句:“所以这个 Redis 缓存层…还有存在的必要吗?”
会议室安静了大概三秒钟。然后我们三个人几乎同时打开了各自负责的模块,开始删代码。847 行、1200 行、2100 行,加起来四千多行的缓存逻辑,就这么没了。没人提议,没人反对,甚至没人觉得需要讨论一下。
我守护了很久的架构
先给你看看我们之前的系统长啥样:
┌─────────────────────────────────────────────────────────┐
│ 应用程序 │
└─────────────────┬──────────────────────┬────────────────┘
│ │
▼ ▼
┌───────────────┐ ┌───────────────┐
│ Redis │ │ PostgreSQL │
│ (缓存) │ │ (存储) │
│ ~0.1ms │ │ ~5-15ms │
└───────┬───────┘ └───────────────┘
│ ▲
└──────────────────────┘
(缓存失效的噩梦)
这架构是我亲手搭的。设计评审会上我据理力争,写了一堆文档解释为什么这是“正确”的做法,还手把手教新人怎么处理缓存失效。
这套架构我维护了很长时间。847 行缓存逻辑散落在 12 个文件里,托管 Redis 集群每月账单 340 美元,缓存失效的 bug 隔三差五就来一次。监控面板要看两套,值班手册要背两份,半夜被叫起来的时候还得先想清楚这次是 Redis 的锅还是 PostgreSQL 的锅。
但说实话,我还挺为这套复杂架构骄傲的。它让我觉得自己是个真正在解决真问题的工程师。
然后 PostgreSQL 18 来了。
图书馆管理员终于学会了两只手一起用
PostgreSQL 18 带来了一个叫“异步 I/O”的特性。官方说明是这样写的:“一个新的 I/O 子系统,可以提升顺序扫描、位图堆扫描、清理操作等的性能。”
这描述吧,技术上没毛病,但听着跟念说明书似的。
让我给你翻译成人话。
以前的 PostgreSQL 就像个特别讲规矩的图书管理员。你问他要本书,他走到书架那儿,拿起来,走回来,递给你。然后你再要一本,他又走过去,拿起来,走回来,递给你。一次只拿一本,特别有秩序,特别慢。
新版 PostgreSQL 呢?就像这个管理员突然开窍了,发现自己原来有两只手。你说要十本书,他一趟全给你抱回来了。完事。
技术上讲,这叫 io_uring 和 Linux 内核的集成。说人话就是:PostgreSQL 终于学会一边走路一边嚼口香糖了。
官方说读取密集型场景能提升 2-3 倍性能。我当时就一个反应:吹吧,接着吹。数据库厂商的基准测试嘛,懂的都懂,哪个不是挑最好看的数字往 PPT 上贴?于是我把我们生产环境的真实查询拉出来跑了一遍,想看看到底有几斤几两。
让我怀疑人生的数字
我们产品仪表盘有个查询,加载用户最近 30 天的活动数据。没啥花哨的,就是按日期聚合单个用户的事件。这种查询我们系统里一天跑个几百万次。
SELECT date, sum(events)
FROM activity
WHERE user_id = $1
AND date > now() - interval '30 days'
GROUP BY date;
图1:PostgreSQL 18对比17的性能提升柱状图,延迟显著降低
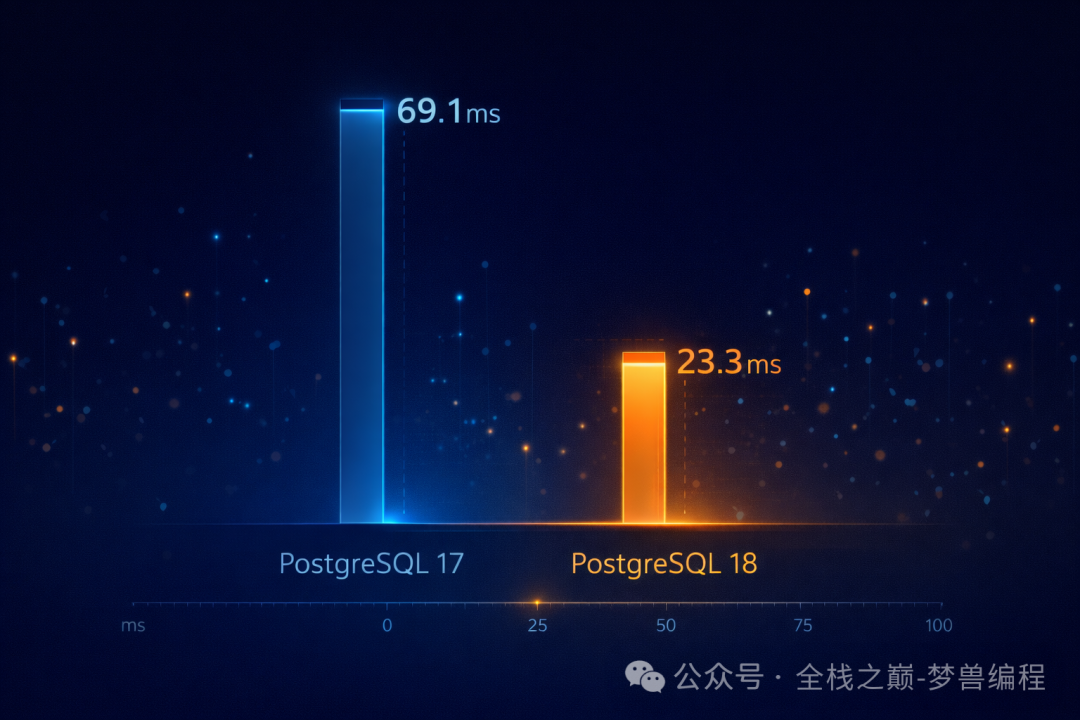
测试结果是这样的:
PostgreSQL 17:
PostgreSQL 18(开启异步 IO):
我跑了四遍,因为我不敢相信自己的眼睛。
热缓存 3 毫秒以内,查的是 30 天的聚合数据。没用 Redis,没有缓存层,就是 PostgreSQL 自己干的。
现在来算笔让人不舒服的账。
Redis 缓存命中时确实快,0.1ms。听着很美好对吧?但现实是我们的命中率只有 73%,剩下 27% 没命中的时候,15ms 的查询加上写回 Redis 的开销,直接把平均值拉下来了。再算上复杂对象序列化的 0.3ms、到托管 Redis 的网络往返 0.8ms,还有那些时不时冒出来的缓存失效 bug——这玩意儿的代价真没法用数字衡量。
把命中和没命中的加权平均算一下,我们那个“飞快”的 Redis 缓存,实际平均延迟大概是 4.2ms。而 PostgreSQL 18 不用任何缓存层,直接给你 2.1ms。你品,你细品。
五行配置改变一切
我们在 postgresql.conf 里改了这些:
-- 启用 io_uring 异步 IO
io_method = 'io_uring'
-- 让 Postgres 并发读取
effective_io_concurrency = 200
maintenance_io_concurrency = 50
-- 分配足够的缓冲区(我们有 64GB 内存)
shared_buffers = 16GB
-- 增加预读合并
io_combine_limit = 512kB
就这些。五个配置项。不用改代码,不用重构架构,不用搞什么六个月的迁移项目。部署上线后,仪表盘延迟直接降了 47%,然后就有了开头那一幕——三个人默契地开始删缓存代码。
没人提的隐藏功能:跳跃扫描
大家都在关注异步 IO 的时候,PostgreSQL 18 悄悄上了另一个对我们更重要的功能:B 树跳跃扫描。
我们有个订单表,在 (user_id, status, created_at) 上建了复合索引。标准套路,没啥特别的。
但我们也有这样的查询:
SELECT * FROM orders
WHERE status = 'pending'
AND created_at > '2025-01-01'
ORDER BY created_at DESC
LIMIT 50;
发现问题没?没有 user_id 过滤条件。
PostgreSQL 17 碰到这种查询,没法高效利用我们的复合索引。数据库要么全表扫描,要么走一条不太理想的路径。我们的解决方案是把结果缓存到 Redis,设 60 秒过期。
PostgreSQL 18 现在可以“跳过”索引的第一列了。它会对每个不同的 user_id 值做一系列范围扫描,即使 WHERE 子句里没指定第一列,也能用上索引。
我们的订单状态查询从 45ms 降到了 8ms。
不需要缓存,不需要管 TTL,不需要写失效逻辑。就是 PostgreSQL 团队把数据库做得更好了。
算一笔缓存的真实账单
我坐下来算了算,这套 Redis 缓存层到底花了我们多少钱。不只是基础设施成本,是全部成本。
托管 Redis 基础设施: 每月 340 美元,累计下来一万多美元。
处理缓存相关 bug 的工程师时间: 我翻了问题追踪系统,缓存相关的事故有二十多次,平均解决时间 7 小时。按保守的 150 美元/小时算,又是两万多美元的工程师时间。
功能开发变慢: 每个新功能都要考虑缓存失效策略,每次改表结构都要更新缓存键,每次部署都要考虑缓存预热。我估计这给开发效率增加了 15% 的负担,四个工程师,累计下来是几千个小时。
认知负担: 这个没法量化。但团队里每个工程师,在每次代码评审、每个架构决策、每次调试的时候,脑子里都得装着缓存失效的逻辑。这种心智负担是有成本的。
图2:缓存真实成本冰山模型图,水面下隐藏了大量工程与认知开销

保守估计:超过 36,000 美元,花在了一个 PostgreSQL 18 用一个内核特性和五行配置就能替代的基础设施上。
这不只是技术教训,这是关于不必要复杂性真实成本的商业教训。
Redis 还是有用武之地的
我得说清楚一件事:我不是说 Redis 死了,也不是说你明天就该删掉所有 Redis 代码,更不是在给内存缓存写讣告。
我想说的是:Redis 作为 PostgreSQL 查询的读取缓存,在很多场景下正在变得可选。
这几种情况 Redis 还是完胜的:
会话存储: 需要保证亚毫秒响应、零波动的时候。用户会话必须瞬间响应。PostgreSQL 就算开了异步 IO,纯键值查找速度也比不上 Redis。
限流: 带自动过期的原子递增操作。INCR 命令配合 TTL 就是 Redis 的拿手好戏。这不是缓存场景,这是数据结构场景。
发布订阅: 跨多个消费者的实时事件分发。PostgreSQL 有 NOTIFY,但 Redis 的发布订阅更成熟,高吞吐消息场景下扩展性更好。
排行榜和有序集合: Redis 的 ZADD 和 ZRANGE 操作就是为排名场景设计的。PostgreSQL 用窗口函数也能做,但 Redis 做得更优雅。
分布式锁: SETNX 模式做分布式锁,久经考验,稳定可靠。这是基础设施,不是缓存。
我们生产环境还在跑 Redis,用来做会话存储和限流。只是不再用它做查询缓存了。
现在我们的架构长这样:
┌─────────────────────────────────────────────────────────┐
│ 应用程序 │
└─────────────────┬──────────────────────┬────────────────┘
│ │
▼ ▼
┌───────────────┐ ┌───────────────┐
│ Redis │ │ PostgreSQL 18 │
│ (会话、限流) │ │ (其他所有) │
└───────────────┘ └───────────────┘
更简单,更便宜,事故更少,监控面板更少,给新人解释的东西更少。
什么情况下这招不管用
我不打算假装这方法对所有人都适用。让我说清楚限制条件。
延迟要求: 如果你的 P99 响应时间要求在 2 毫秒以内,光靠 PostgreSQL 18 可能达不到。真正的亚毫秒保证,还是需要内存方案。
流量规模: 如果你每秒要处理几百万个请求,而且都打到同样的热点键上,Redis 还是对的选择。光是连接开销就能把 PostgreSQL 压垮。
内核版本: io_uring 支持需要 Linux 内核 5.10 或更新。如果你跑在老基础设施上,异步 IO 的好处你享受不到。
数据集大小: 如果你的工作数据集装不进内存,而且 I/O 瓶颈在机械硬盘上,异步 IO 有帮助但不是魔法。SSD 对这个方案来说还是必需的。
云厂商限制: 有些托管 PostgreSQL 服务还不支持 io_uring 配置。迁移前先问问你的云厂商。
对自己的真实需求诚实一点。测量你的真实延迟。看看你的真实命中率。
那个让人不舒服的问题
删完那 847 行代码之后,有个问题一直在我脑子里转:
我代码库里有多少工程决策,是因为“资深工程师都这么干”,而不是因为“我们测过了这样更快”?
我在项目第一天就加了 Redis 缓存,因为这是有经验的开发者该做的事。我们默认就缓存,把数据库当成慢的,除非证明它不慢。我们构建复杂性,因为复杂性显得专业。
结果呢?我维护着一套解决我从未真正测量过的问题的基础设施。
PostgreSQL 团队花了好几年打造异步 IO。他们重写了数据库和存储通信的核心部分。他们集成了最前沿的 Linux 内核特性。他们跑了几千次基准测试,修了几百个边界情况。
而所有这些工作,让我那 847 行缓存代码暴露了它的本来面目:基于从未验证过的假设做的过早优化。
最后一个问题
每个代码库都有一些当时有充分理由、但已经过时的决策。每个架构都有一些因为有人假设必要、而不是证明必要而存在的复杂性。
PostgreSQL 18 逼着我直面自己工作中的一个这样的假设。那个我在代码评审中捍卫、在 wiki 里记录、手把手教给新人的缓存层,解决的是一个在 PostgreSQL 团队发布更好的 I/O 处理那一刻就不存在了的问题。
我不知道你的代码库里藏着什么假设。我不知道哪些复杂性在发挥作用、哪些是上个时代的遗留。我不知道你的 Redis 缓存是必需的还是可选的。
但我知道,测量是找出答案的唯一方法。
我删了 847 行代码,因为我终于去测量了。
也许你也该测测了。
以上思考与案例也欢迎在 云栈社区 与其他开发者进行交流。
 发表于 2025-12-30 03:30:42
|
查看: 220|
回复: 0
发表于 2025-12-30 03:30:42
|
查看: 220|
回复: 0
