在Linux系统的运维与开发工作中,性能瓶颈如同难以察觉的“暗礁”。CPU使用率骤升、内存缓慢泄漏、I/O延迟激增等问题时有发生。传统的分析工具往往因无法深入内核底层,只能停留在表面现象进行推测,难以触及问题根源。
而基于eBPF技术所实现的“内核级透视”能力,正在改变这一现状。它让性能诊断实现了从“模糊猜测”到“精准定位”的跨越。无需修改内核源码,也无需重启系统,便能安全地探查内核与应用间的交互细节,直指性能问题的核心。
一、什么是BPF?
1.1 BPF的概述
BPF,全称伯克利数据包过滤器(Berkeley Packet Filter),其历史可以追溯到1992年。它最初由Steven McCanne和Van Jacobson开发,旨在高效解决网络数据包过滤的难题。传统的包过滤技术效率低下,而BPF允许用户在内核空间运行过滤代码,极大地提升了处理效率,相比当时的技术有数量级的提升。我们所熟知的tcpdump工具,其底层正是基于BPF技术实现的。
随着时间的推移,BPF逐渐展现出其局限性。它功能较为单一,难以满足更广泛的内核编程需求。因此,在2014年,扩展伯克利数据包过滤器(eBPF,Extended Berkeley Packet Filter)应运而生。eBPF对传统BPF进行了全面扩展,使其从一个单纯的网络过滤工具,演变为一种强大、通用的内核编程技术,应用领域得到了极大的拓宽。
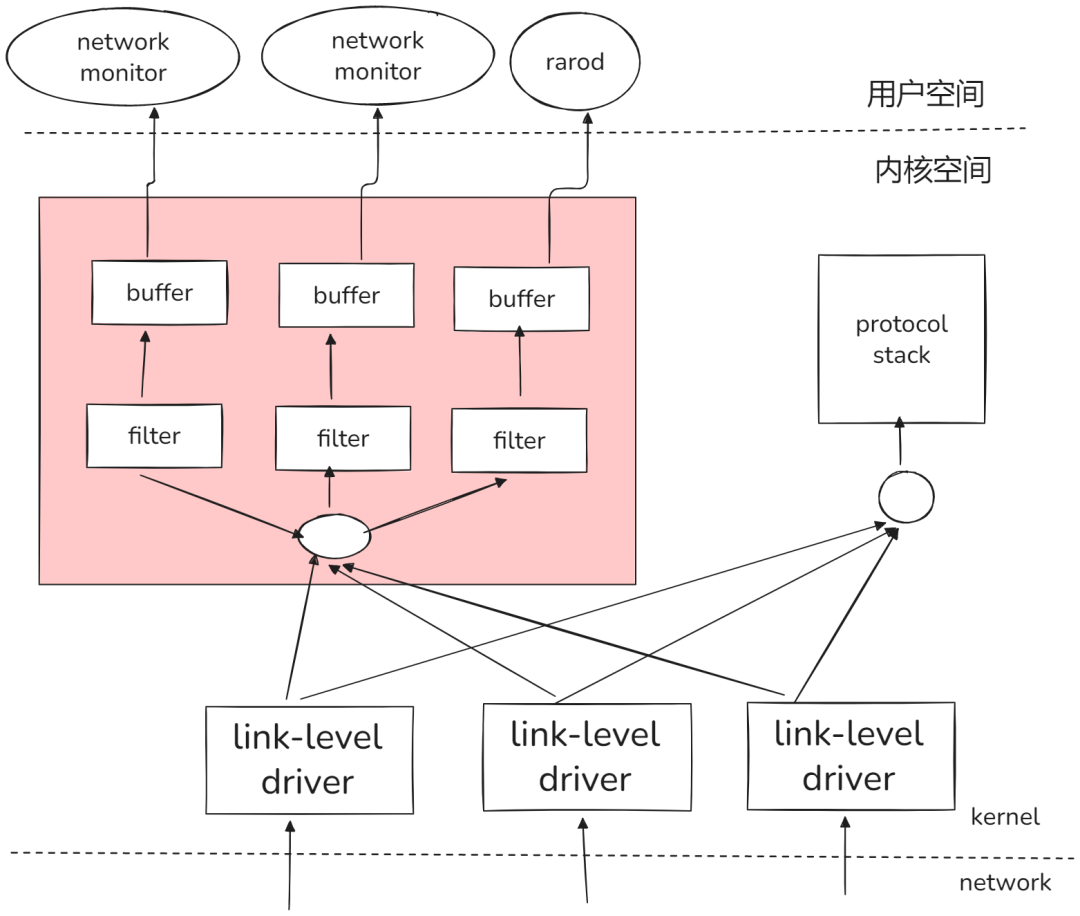
图1:BPF在网络监控中的数据流示意图,展示了用户空间与内核空间、协议栈间的交互关系。
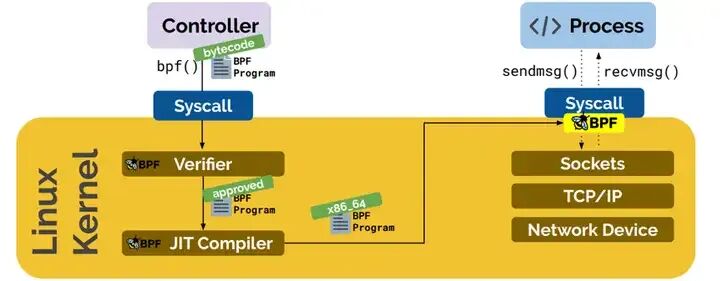
图2:eBPF程序从加载、验证到JIT编译和执行的核心工作流程。
(1)BPF环境准备:确保内核版本支持
eBPF需要较新版本的Linux内核支持,通常建议至少为4.1以上。首先检查你的内核版本:
# uname -r
4.20.13-1.el7.elrepo.x86_64
(2)使用Docker快速体验BCC工具集
为了方便地使用BPF工具集BCC(BPF Compiler Collection),我们可以快速运行一个包含BCC的Docker镜像:
docker run -it --rm \
--privileged \
-v /lib/modules:/lib/modules:ro \
-v /usr/src:/usr/src:ro \
-v /etc/localtime:/etc/localtime:ro \
--workdir /usr/share/bcc/tools \
zlim/bcc
1.2 BPF的工作原理剖析
BPF的工作原理基于一个巧妙的设计——它定义了一套虚拟机指令规范。你可以将其视为一种运行在内核中的微型虚拟机。这一特性使得我们能够在不修改内核源代码和重新编译的情况下,动态地扩展内核功能。
具体的工作流程如下:
- 编写eBPF程序:开发人员通常使用C语言编写eBPF程序,定义需要追踪的事件和处理逻辑。
- 编译为字节码:通过LLVM编译器将C代码编译成符合eBPF指令集架构的字节码。这套指令集经过精心设计,能够有效防止运行时错误。
- 提交与验证:通过
bpf()系统调用将字节码提交给内核。内核中的验证器(Verifier)会对其进行严格的安全检查,包括防止无限循环、检查非法内存访问等。
- JIT编译:通过验证的字节码会被即时编译器(JIT)翻译成本地机器码,以保证高效的执行性能。
- 事件触发与执行:当预设的内核事件(如系统调用、网络数据包到达)发生时,对应的eBPF程序就会被触发执行。
- 数据输出:eBPF程序将处理结果存储到一种称为“映射(map)”的共享数据结构中,用户空间的程序可以从中读取结果进行分析。
1.3 BPF工具集
(1)BCC(BPF Compiler Collection)
BCC是一个开源项目,它既是一个功能丰富的高级性能分析工具集,也是一个用于构建此类工具的框架。像Facebook、Netflix这样的公司都在广泛使用BCC进行系统性能剖析。
安装BCC非常方便,主流的Linux发行版都提供了对应的软件包(如 bcc-tools)。BCC的工具可以分为两类:
- 专用工具:遵循“做一件事并做好”的原则。例如:
biolatency:汇总块I/O延迟并以直方图显示。biotop:按进程实时显示块I/O使用情况。biosnoop:跟踪每一次块I/O请求,输出详细信息。
- 通用工具:更为灵活,功能强大。例如:
argdist:显示函数参数值的分布(直方图或计数)。funccount:统计指定内核或用户空间函数的调用次数。funcslower:追踪执行时间超过阈值的内核或用户空间函数调用。
BCC还支持便捷的单行命令,例如快速统计所有vfs_开头的内核函数调用次数:funccount ‘vfs_*’。
(2)bpftrace
bpftrace是基于eBPF的高级动态跟踪工具,它使用一种类似AWK和C语言语法的、简洁的声明式脚本语言。它非常适合快速编写单行命令或简短脚本来进行系统探索。
例如,跟踪所有进程的系统调用次数:
sudo bpftrace -e ‘tracepoint:syscalls:sys_enter_* { @[comm] = count(); }’
再比如,测量vfs_read()内核函数的执行时间并以直方图输出:
#!/usr/local/bin/bpftrace
// 此程序测量 vfs_read() 的执行时间
kprobe:vfs_read
{
@start[tid] = nsecs;
}
kretprobe:vfs_read /@start[tid]/
{
$duration_us = (nsecs - @start[tid]) / 1000;
@us = hist($duration_us);
delete(@start[tid]);
}
二、Linux性能瓶颈的BPF透视
2.1 CPU瓶颈:定位内核态函数耗时
CPU瓶颈通常表现为几种形式:
- 用户态占满:在
top命令中%us值很高,通常是计算密集型进程导致。
- 内核态占满:
%sy值持续高位,可能由频繁的上下文切换、大量中断处理等引起。
- I/O等待:
%wa值高,表明CPU在等待磁盘或网络I/O。
传统工具如top只能告诉你CPU“忙”,但不知道“忙什么”。BPF可以深入到内核函数级别。
案例:某电商秒杀服务在峰值时CPU突然达到100%,top显示是业务进程,但应用层日志无异常。此时,很可能是内核态函数消耗了大量CPU。
使用BPF的profile工具追踪内核函数耗时:
# 对所有进程的内核函数进行采样,每100ms一次,输出耗时最长的前20个函数
sudo profile -F 10 -K -top 20
运行10秒后发现,mutex_lock_interruptible函数的耗时占比高达40%——这表明存在严重的内核态锁竞争。
进一步使用lockstat工具定位具体的锁竞争:
# 追踪进程PID为12345的锁竞争事件
sudo lockstat -p 12345
最终定位到是业务代码调用的某个底层库,在高并发下频繁触发了内核态的互斥锁竞争。通过调整锁的粒度,CPU使用率从100%下降到了30%。
2.2 内存溢出:揪出“隐形”内存泄漏点
内存瓶颈主要体现为:
- 内存不足导致交换:
free命令显示可用内存available极少,交换空间swpd被使用。
- 内存泄漏:某个进程的常驻内存
RES持续增长且不释放。
应用层工具valgrind对内核态内存泄漏无能为力,而BPF可以。
案例:某日志收集服务的内存每天以1G的速度增长,使用valgrind排查应用层未发现泄漏。问题可能出在内核态。
使用BPF的memleak工具追踪内核内存分配:
# 追踪PID为6789的进程的内核内存分配,累计5秒后输出可能的泄漏点
sudo memleak -p 6789 -a 5
结果显示,内核函数sk_alloc(在创建socket时调用)被频繁执行,但其对应的释放函数sk_free却未执行。最终发现是代码在创建UDP socket后,某个异常分支路径忘记调用close(),导致内核中的socket结构体无法释放,造成内核态内存泄漏。修复后,内存增长问题彻底解决。
2.3 网络延迟高:定位数据包在哪个环节“卡壳”
网络I/O问题可能源于带宽不足、配置错误或内核协议栈处理瓶颈。tcpdump能看到包,但不知道包在内核里“停留”了多久。
案例:某支付服务的接口延迟从50ms飙升至500ms。使用tcpdump抓包发现数据包能到达网卡,但应用层接收缓慢,怀疑是内核处理耗时过长。
使用BPF的tcpconnect工具分析TCP连接建立过程:
# 追踪目标端口为8080的TCP连接,并输出耗时信息
sudo tcpconnect -P 8080 -t
输出显示,在skb_copy_datagram_iovec这个阶段耗时占比高达70%。这是内核将网络数据包从内核缓冲区复制到应用缓冲区(userspace)的过程。
进一步排查发现,应用层使用了很小的缓冲区进行循环读取,导致内核需要频繁执行大量的小规模内存复制操作。将应用层的接收缓冲区从4K调整为64K后,系统调用次数大幅减少,网络延迟恢复到了正常水平。
2.4 传统性能分析工具的局限性
工具如top、htop、vmstat、iostat在宏观资源监控上非常有用,但它们存在共同的局限性:
- 信息维度有限:只能展示系统或进程层面的资源汇总数据(如CPU%、MEM%)。
- 无法深入上下文:当看到CPU使用率高时,无法知道是哪些内核函数、哪一行用户代码导致的。
- 缺乏动态追踪能力:难以针对特定事件(如“当打开某个文件失败时”)进行跟踪和统计。
这些局限性使得在诊断复杂、偶发或深层次的性能问题时,传统工具往往力不从心。而这正是BPF等内核级追踪技术大显身手的地方。
三、BPF实现内核级透视的核心方法
3.1 BPF的关键跟踪能力
BPF之所以能实现深度透视,源于其多种强大的跟踪点(Tracepoint)机制:
- kprobe:动态内核探针。可以在几乎所有内核函数的入口和出口处插入探针,获取函数参数、返回值和执行时间。它是分析内核行为最灵活的武器。
- uprobe:用户空间探针。与kprobe类似,但作用于用户空间的应用程序函数。用于分析应用程序的运行时行为。
- tracepoint:静态内核跟踪点。这是内核开发者预先在关键路径上设置的“观测钩子”,更加稳定且性能开销更小。覆盖了调度、系统调用、文件系统、网络等大量事件。
这些跟踪点构成了BPF观测系统的基石,就像在内核和用户空间的各个角落安装了“高清摄像头”。
3.2 BPF工具实战演示
使用bpftrace进行快速分析
使用BCC编写定制化工具
BCC允许你用Python或C++编写更复杂的BPF程序。例如,一个简化的统计网络收包数的程序框架如下:
// 示例:使用BCC库统计网络接收数据包数量(概念框架)
#include <bcc/BPF.h>
#include <iostream>
const std::string bpf_program = R"(
BPF_HASH(packet_counter, u32); // 定义一个哈希表映射
int count_packet(struct pt_regs *ctx) {
u32 key = 0;
u64 *val = packet_counter.lookup_or_init(&key, &key);
(*val)++;
return 0;
}
)";
int main() {
bcc::BPF bpf;
bpf.init(bpf_program);
// 将 count_packet 函数附加到网络接收的kprobe上
bpf.attach_kprobe(“netif_receive_skb”, “count_packet”);
// ... 循环读取并打印 packet_counter 中的值
return 0;
}
四、BPF案例深度剖析
4.1 案例一:系统调用追踪 - opensnoop 与 execsnoop
opensnoop和execsnoop是BCC工具集中用于追踪文件打开和进程执行的经典工具。
- opensnoop:追踪
open、openat等系统调用。可以实时显示哪个进程(PID)、以什么结果(成功/失败及错误码)打开了哪个文件。对于排查配置文件丢失、权限问题、文件描述符泄漏等场景极其有效。
- execsnoop:追踪
execve系统调用。可以实时显示新进程的启动,包括其PID、父进程PID、命令行参数等。对于发现短命进程、排查恶意进程、分析启动链非常有用。
4.2 案例二:网络性能监控 - TCP 相关工具
BCC提供了一系列针对TCP协议栈的分析工具:
- tcplife:追踪TCP会话的完整生命周期。显示连接从建立(四元组、进程)、到传输(收发字节数)、再到关闭(持续时间、状态)的全过程。用于分析连接行为、发现异常长连接或短连接。
- tcpconnect:专用于追踪主动的TCP连接建立。显示哪个进程发起到哪个远程地址的连接,以及连接是否成功、耗时多少。对于诊断连接超时、网络分区、服务发现失败等问题至关重要。
4.3 案例三:Netflix性能分析实战
Netflix分享了他们在迁移微服务从AWS EC2虚拟机到自有容器平台Titus时,遇到的性能分析案例。新平台上请求延迟降低了3-4倍,他们需要找出原因。
分析过程:
- 对比分析:在虚拟机和容器上同时运行相同的负载,并使用相同的BPF/BCC工具集进行对比。
- 宏观指标:使用
uptime、mpstat发现虚拟机CPU利用率接近饱和(98%),而容器主机利用率很低(22%)。虚拟机内核态时间(%sys)也更高。
- 深入挖掘:仅凭宏观指标无法解释根本原因。他们进一步检查硬件配置,发现容器主机使用了最后一级缓存(LLC)更大(45MB vs 33MB)的CPU。
- 核心验证:通过性能监控单元(PMC)计数器分析证实,更大的LLC带来了更高的缓存命中率。这意味着容器在处理相同计算任务时,访问内存的频率大大降低,这是延迟降低3-4倍的核心原因。
这个案例深刻说明,现代性能分析需要从宏观指标深入到CPU微架构级别,而BPF及其生态工具(结合PMC)提供了这种深度透视的能力。
总结
BPF技术为Linux系统的性能分析和运维提供了革命性的内核级深度观测能力。它打破了用户空间与内核空间之间的信息壁垒,使得定位CPU竞争、内存泄漏、网络延迟等复杂问题变得前所未有的精准和高效。
从BCC工具集的即开即用,到bpftrace的灵活脚本,再到基于BPF API的自定义开发,不同层次的使用者都能找到适合自己的武器。掌握BPF,意味着你拥有了透视系统内部运作的“X光机”,能够在性能优化的道路上从被动应对走向主动洞察。
欢迎在云栈社区交流更多关于Linux内核与性能优化的实践经验。
 发表于 2025-12-30 04:22:38
|
查看: 220|
回复: 0
发表于 2025-12-30 04:22:38
|
查看: 220|
回复: 0
