概述
INSERT INTO 操作支持将 Doris 的查询结果直接导入到另一张表中。这是一种同步导入方式,执行后直接返回导入结果,便于用户即时判断任务成功与否。其核心优势在于保证了导入任务的原子性,确保数据要么全部成功写入,要么完全回滚,避免产生中间状态。这对于需要强一致性的数据处理场景至关重要。
语法
INSERT INTO 语句主要支持以下两种写入方式:
- 通过 SELECT 查询插入:将查询结果集写入目标表。
- 通过 VALUES 列表插入:直接指定要插入的数值。
对应的基础语法如下:
INSERT INTO tbl SELECT ...
INSERT INTO tbl (col1, col2, ...) VALUES (1, 2, ...), (1,3, ...)
操作示例
1. 创建目标表
首先,我们创建一个名为 insto 的测试表,用于接收后续插入的数据。
CREATE TABLE IF NOT EXISTS insto
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`age` SMALLINT COMMENT "用户年龄"
)
UNIQUE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true"
);
2. 使用 VALUES 插入单条数据
使用最基础的 VALUES 语法插入一条测试记录。
insert into insto values(1,10)
这种方式语法简单直接,常用于快速插入少量测试数据,但在生产环境处理海量数据时效率较低,并非最佳选择。
3. 通过 SELECT 查询进行批量插入
这是更符合生产实践的用法,通常涉及从另一张表或复杂查询中筛选数据并导入。
第一步:创建数据源表
我们创建一张包含更多字段的源表 jsontest。
CREATE TABLE IF NOT EXISTS jsontest
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`age` SMALLINT COMMENT "用户年龄",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATE COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true"
);
假设 jsontest 表中已有如下数据:
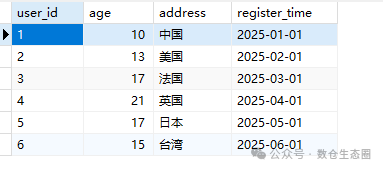
图1:jsontest 表中的示例用户数据
第二步:清理目标表数据
为确保演示清晰,我们先清空之前插入的测试数据。
delete from insto where user_id=1
第三步:执行 INSERT INTO ... SELECT
现在,我们从 jsontest 表中选取 user_id 和 age 字段,批量插入到 insto 表中。这正是处理 大数据 同步和ETL任务的典型场景。
insert into insto select user_id,age from jsontest
第四步:验证插入结果
执行成功后,查询 insto 表,可以看到数据已准确同步。
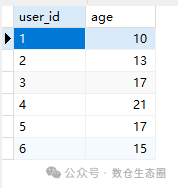
图2:通过SELECT查询验证插入结果
希望这篇关于Doris核心导入操作的详解能对你有所帮助。想了解更多数据处理与 数据库 技术,欢迎访问 云栈社区 进行深度交流与探索。
 发表于 2025-12-30 04:24:40
|
查看: 278|
回复: 0
发表于 2025-12-30 04:24:40
|
查看: 278|
回复: 0
