今天聊聊一个挺有意思的“可视化拖拽式数据流平台”。对于需要频繁处理数据同步、清洗但又不想写太多代码的团队来说,这类工具往往能显著提升效率。它主打通过简单的拖拽操作来配置复杂的数据流转逻辑,实现真正的低代码数据开发。
项目相关地址如下:
平台核心亮点
对比市面上的其他方案,这个平台有几个设计亮点比较实用:
- 流批一体:无论是实时监听数据变更,还是定时跑批处理任务,都可以在同一套流程中配置,无需为不同场景维护两套系统。
- 版本控制与回滚:数据流任务像代码一样支持版本管理。配置发布后生成新版本,一旦出现问题可以快速回退到历史稳定版本,降低了运维风险。
- 分布式与自动容错:采用分布式架构,支持动态伸缩。任务节点故障后会自动在其他可用实例上恢复,提高了系统的整体可用性。
- 完善的监控告警:平台内置了丰富的监控指标和灵活的告警规则配置,确保数据流转异常时能第一时间通知到负责人。
- 细粒度数据权限:支持对数据源、数据流、查询接口等资源进行权限配置,管理谁可以查看或操作哪些数据。
系统架构设计
平台在架构上支持弹性伸缩。这意味着在业务低峰期可以缩减资源以节约成本,而在如“双十一”等高并发场景下,可以通过快速扩容实例来承载更大的数据流量。其核心架构如下图所示:
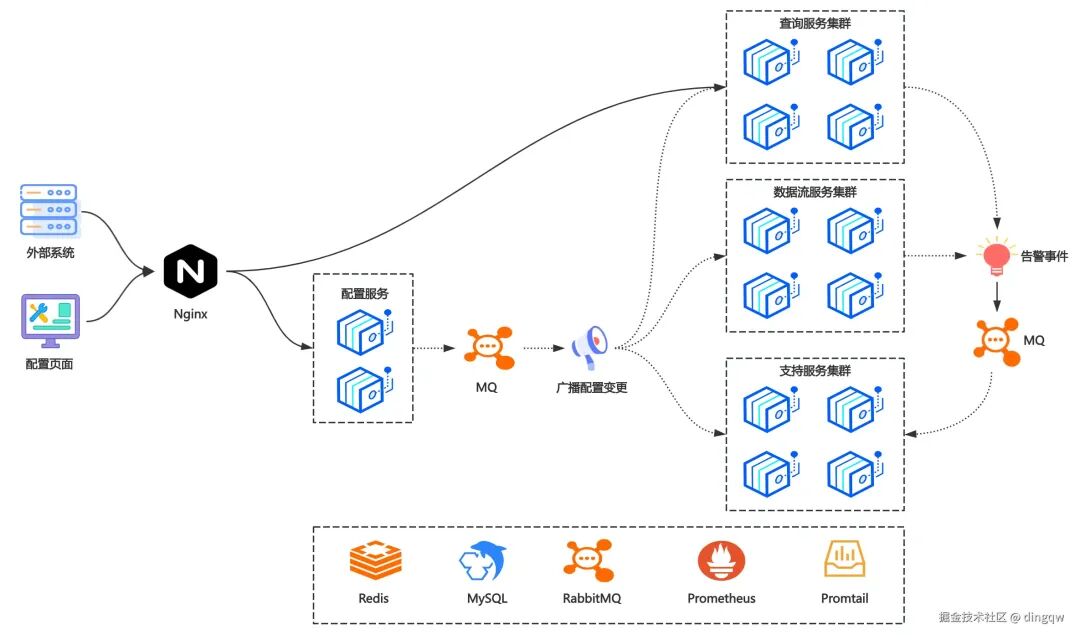
架构中依赖了 Redis、MySQL 及 RabbitMQ 等核心组件作为配置管理、状态存储和消息通信的基础。
平台功能界面一览
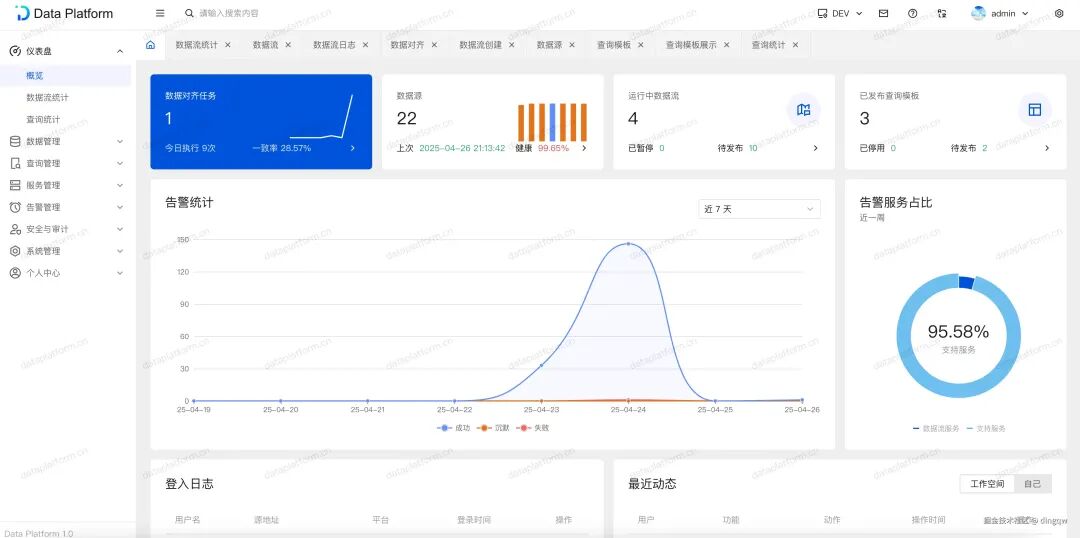
1. 首页仪表盘
登录后首先看到的是综合数据大盘,全局视角展示系统健康度,包括任务执行概况、数据源状态、实时告警统计等关键信息。
数据流统计
此模块专注于监控所有数据流任务的运行状态与服务器资源消耗情况,例如实例数量、CPU与内存使用率。
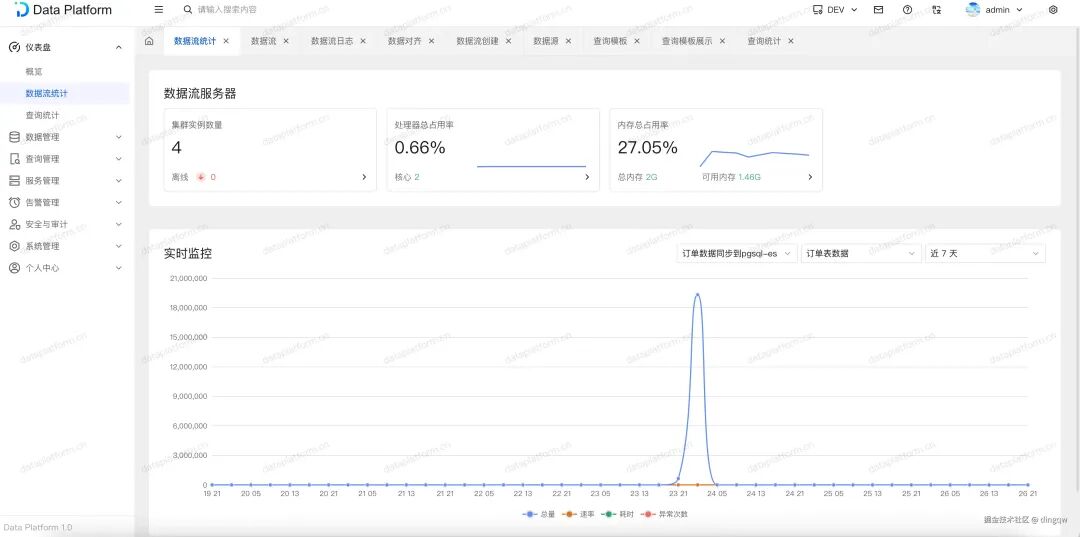
点击CPU或内存图表,可以下钻查看具体服务器的详细运行指标。
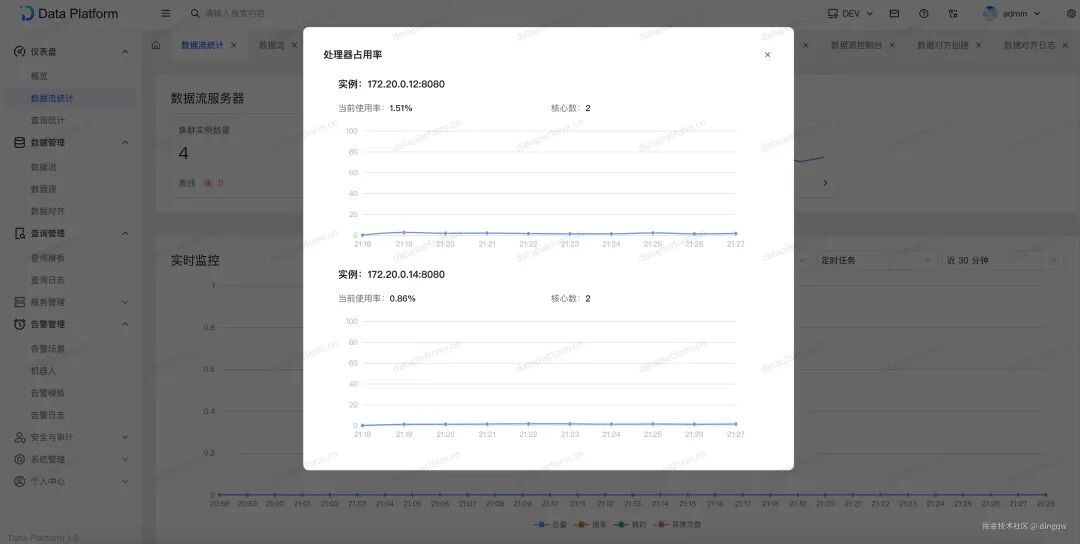
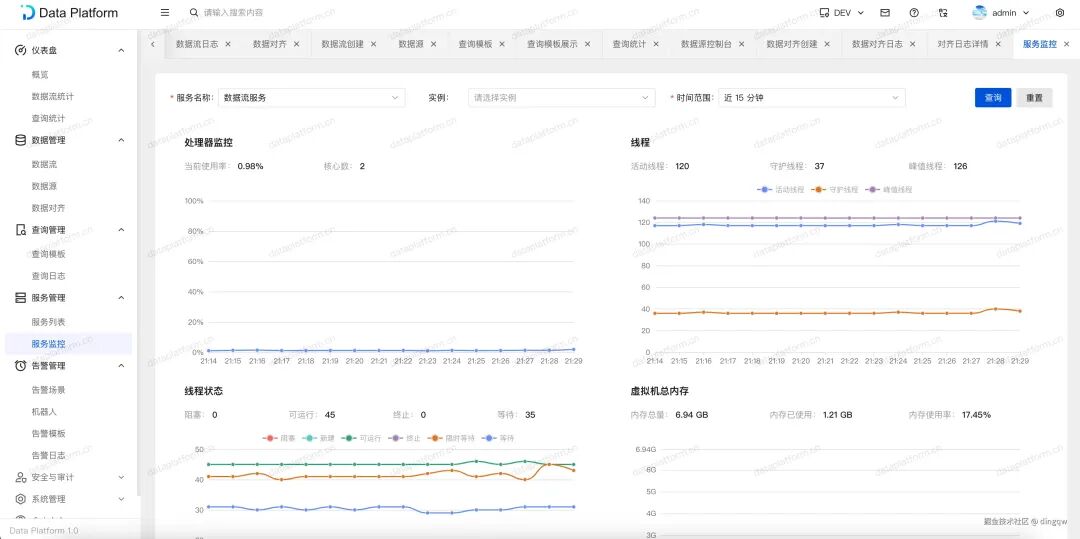
如果需要更深入的JVM级别监控,可以在“服务监控”页面查看线程、堆内存等详细信息。
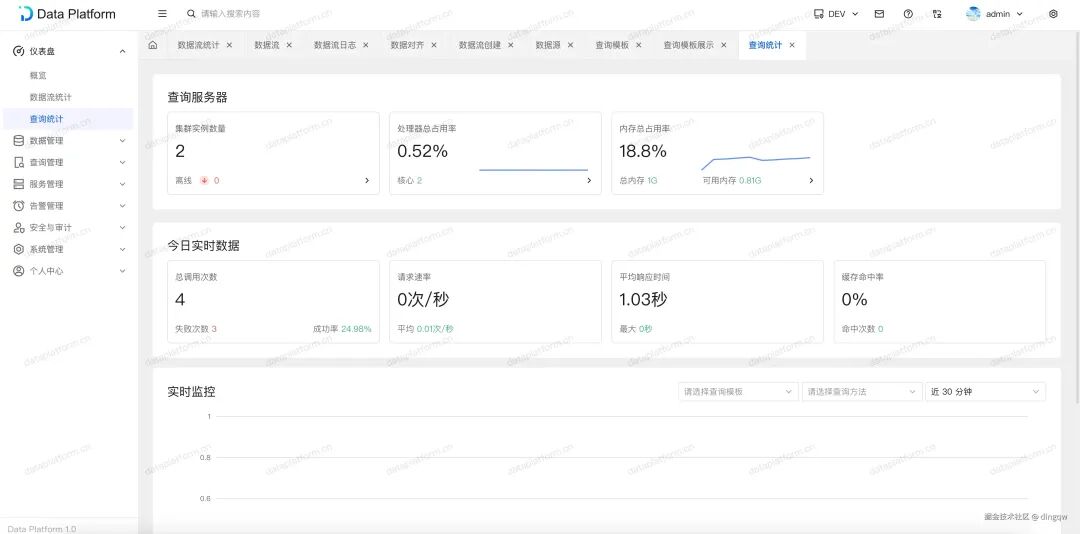
查询模板统计
对于平台提供的查询接口服务,这里统计了调用量、成功率、服务器负载以及缓存命中率等关键指标。
2. 数据管理核心功能
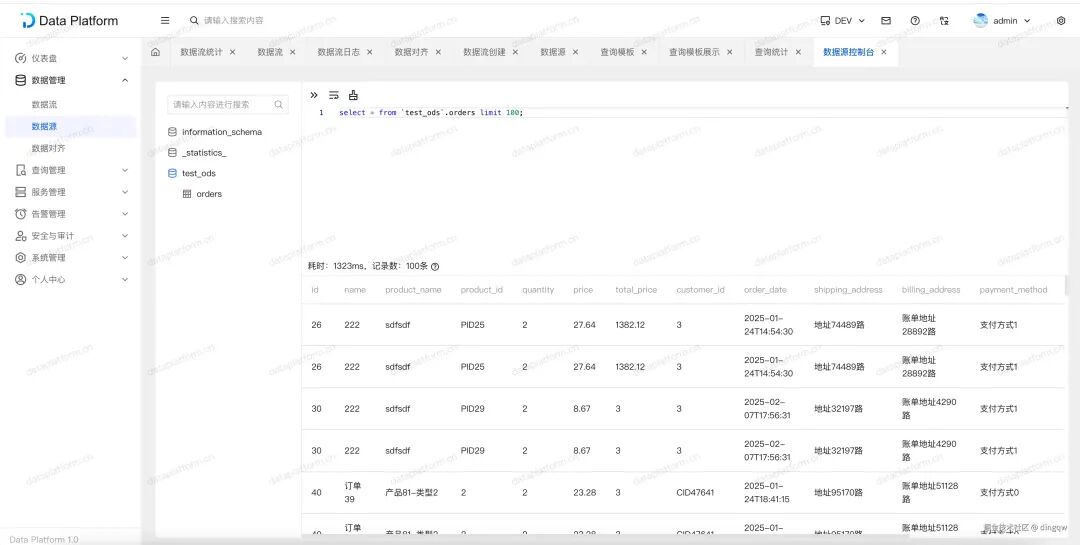
数据流
这是平台最核心的功能模块。用户通过可视化画布,以拖拽组件的方式构建从数据源到目标端的数据流,完成同步、过滤、转换等操作。
-
数据流列表:管理所有已创建的数据流任务,清晰展示其名称、状态、发布版本等信息。
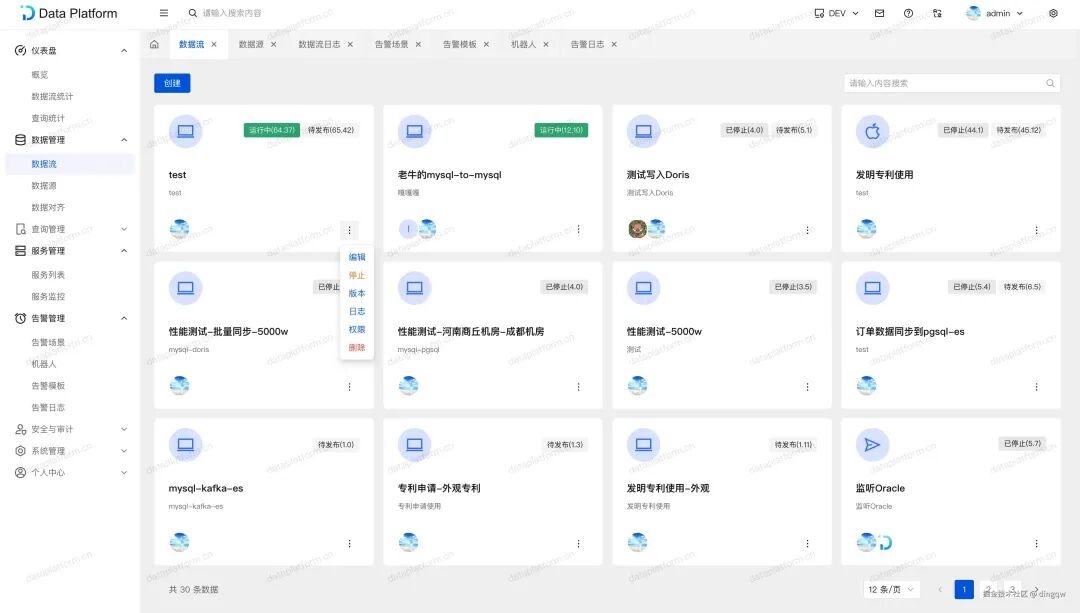
-
可视化数据流画布:通过拖拽“监听”、“过滤”、“转换”、“写入”等组件,并用连线表示数据流向,即可构建完整的数据处理管道。例如,配置一个从MySQL监听订单表,经过过滤和字段转换,最终写入Elasticsearch和Doris的流程。
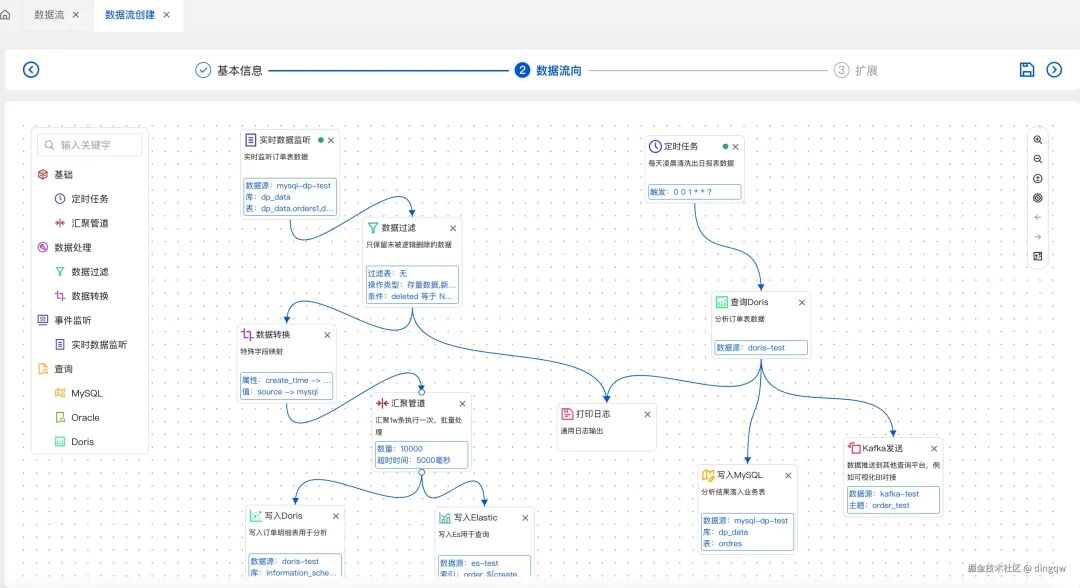
-
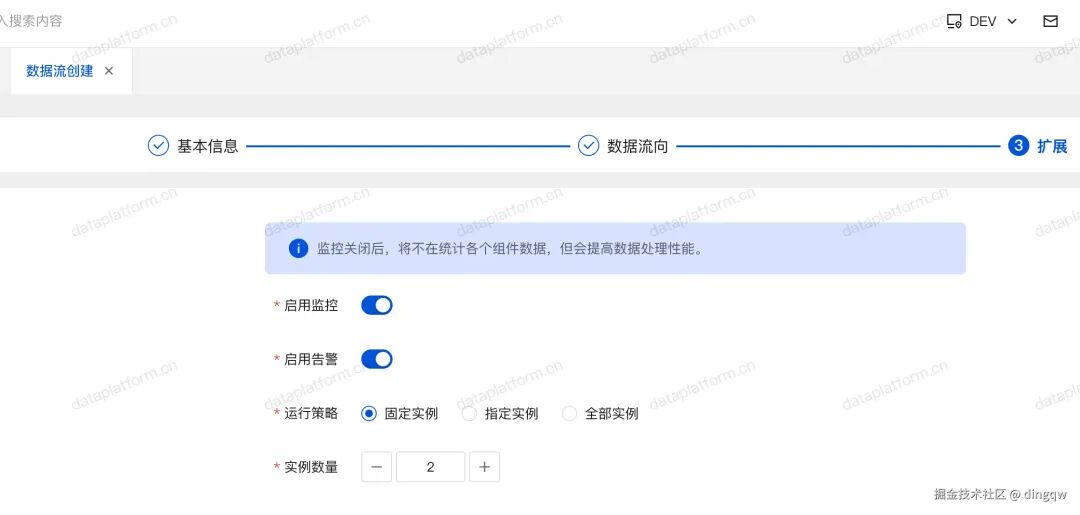
在发布流程时,可以指定运行策略(如固定实例或动态分配)和实例数量,系统支持故障自动转移和动态扩容。
-
实时运行日志:任务运行过程中产生的日志实时刷新,便于调试和跟踪数据流转细节。
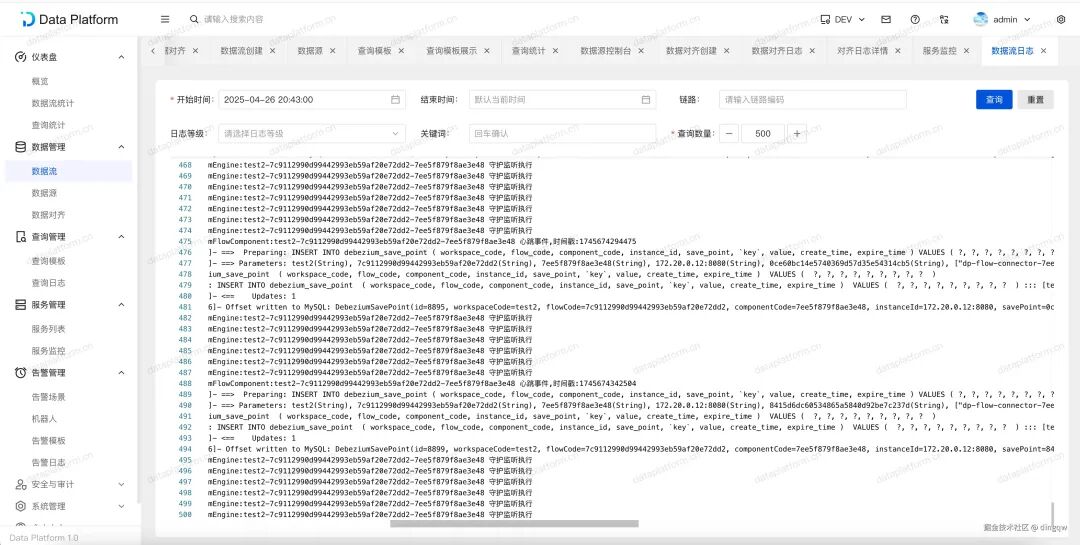
-
发布历史与版本回滚:所有历史发布版本都被记录,可以方便地查看、对比或回滚到任一旧版本。

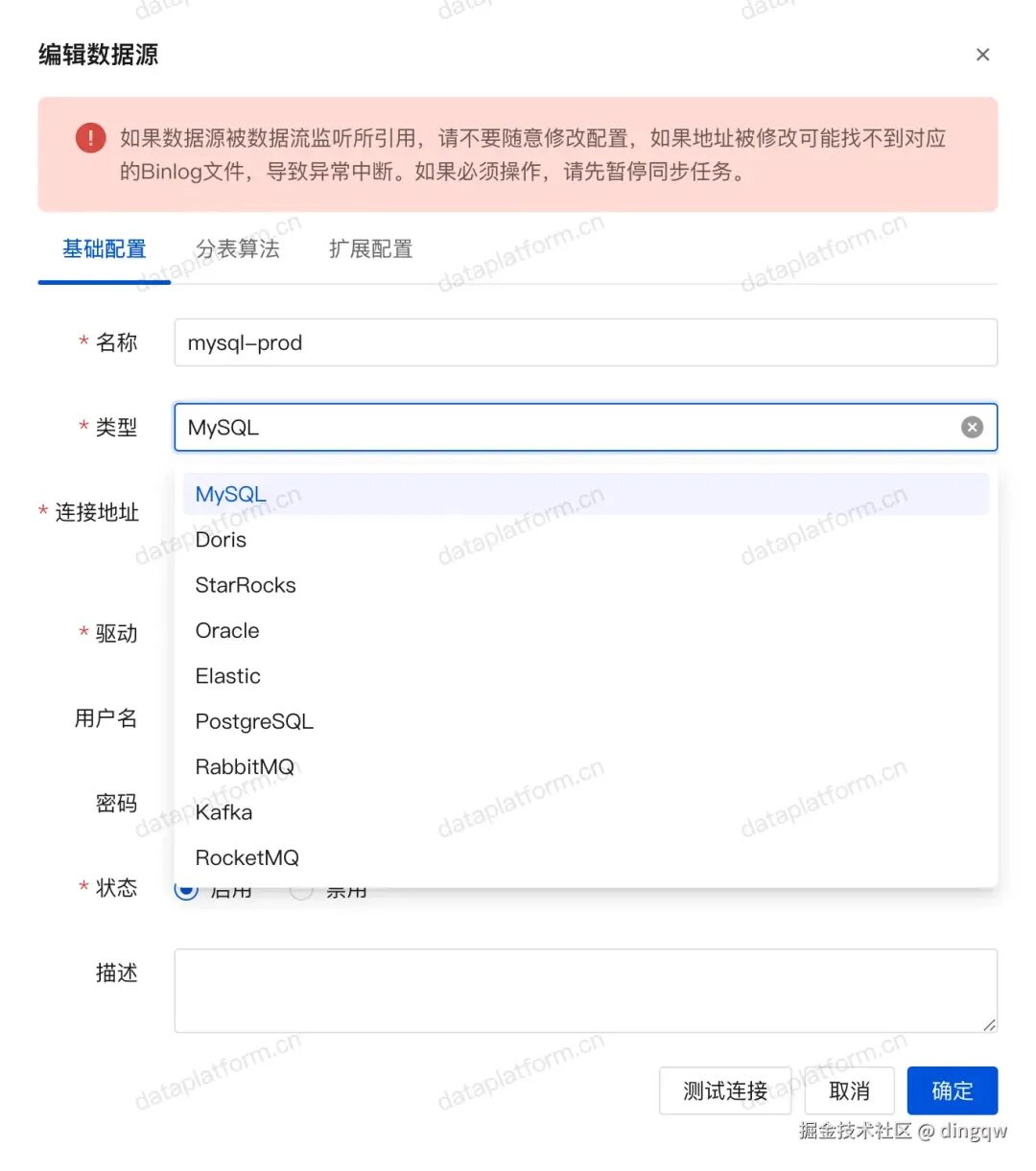
数据源管理
平台采用插件化设计,支持多种数据源,包括 MySQL、PostgreSQL、Oracle、Elasticsearch、Kafka、Doris、StarRocks等,并易于扩展。
数据对齐
这是一个非常实用的数据质量保障功能。用户可以配置任务,定期或实时对比两个数据源(可以是不同类型)之间的数据一致性,支持数量一致、内容一致等策略,并能定位差异详情。
-
数据对齐任务列表:管理所有对齐任务。
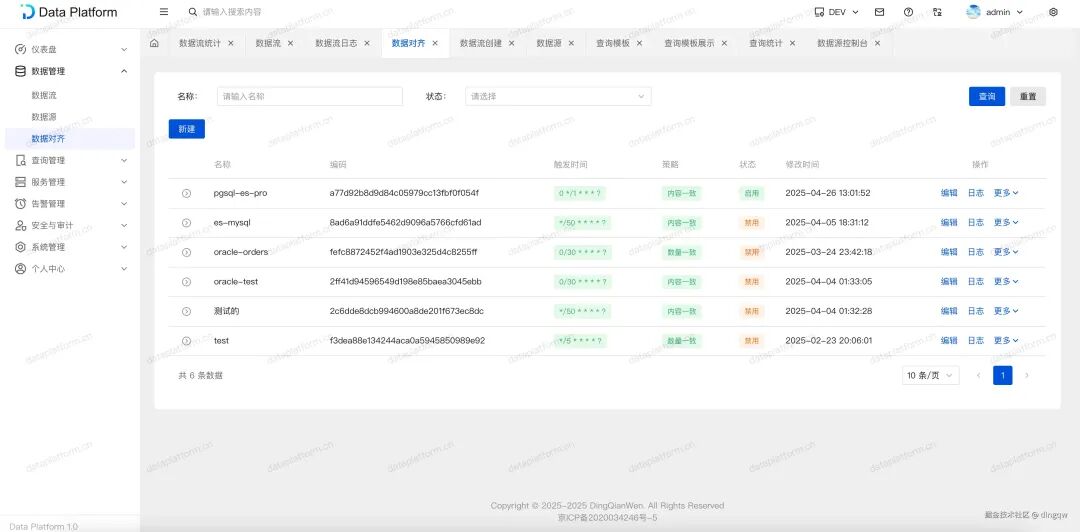
-
创建对齐任务:配置源和目标数据源、对比的时间范围、字段映射以及对比策略。
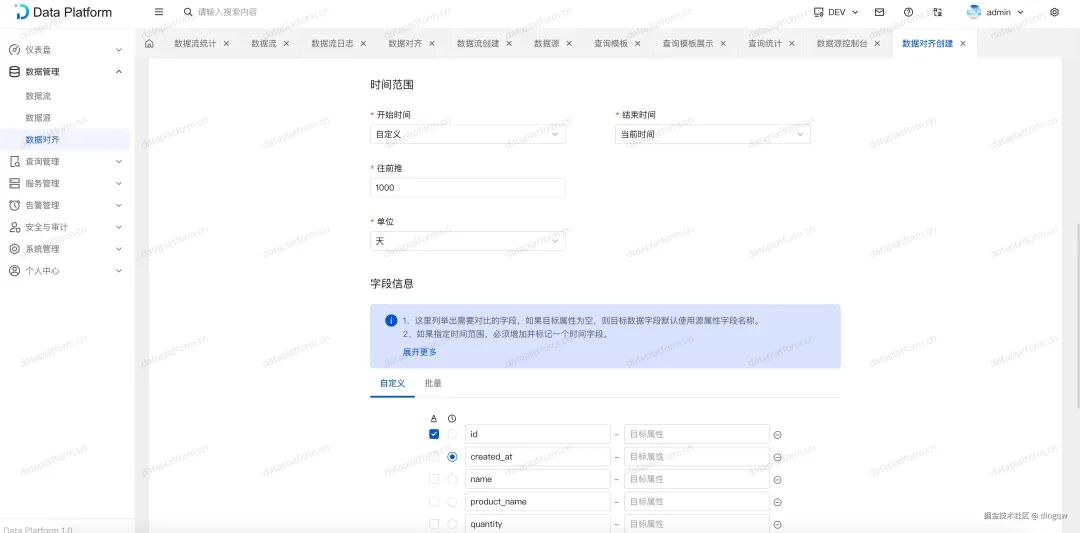
-
对齐执行日志:查看每次对齐任务的执行结果(一致、不一致、失败)。
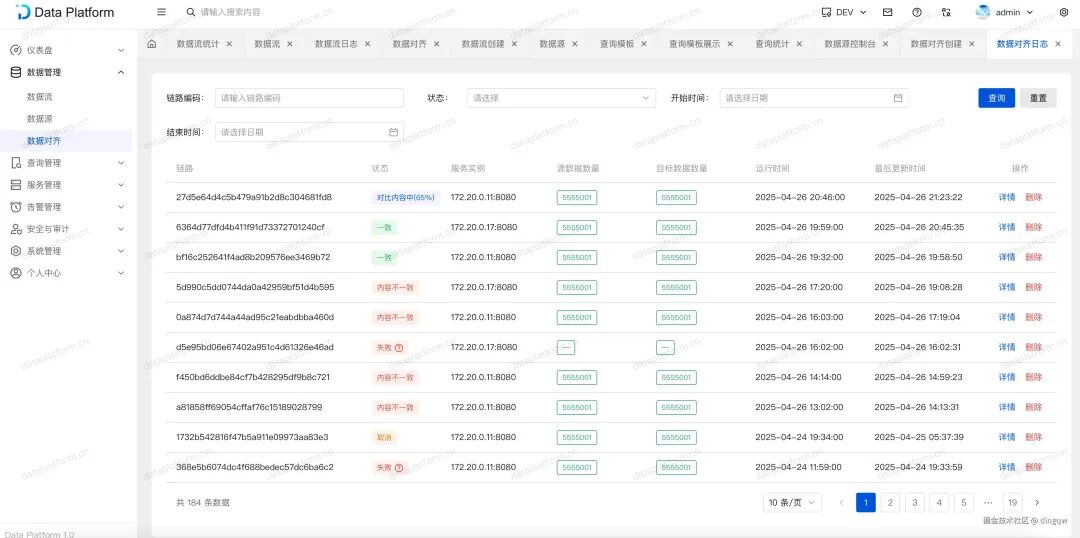
-
不一致数据详情:当发现数据不一致时,可以查看具体是哪条数据的哪些字段存在差异。
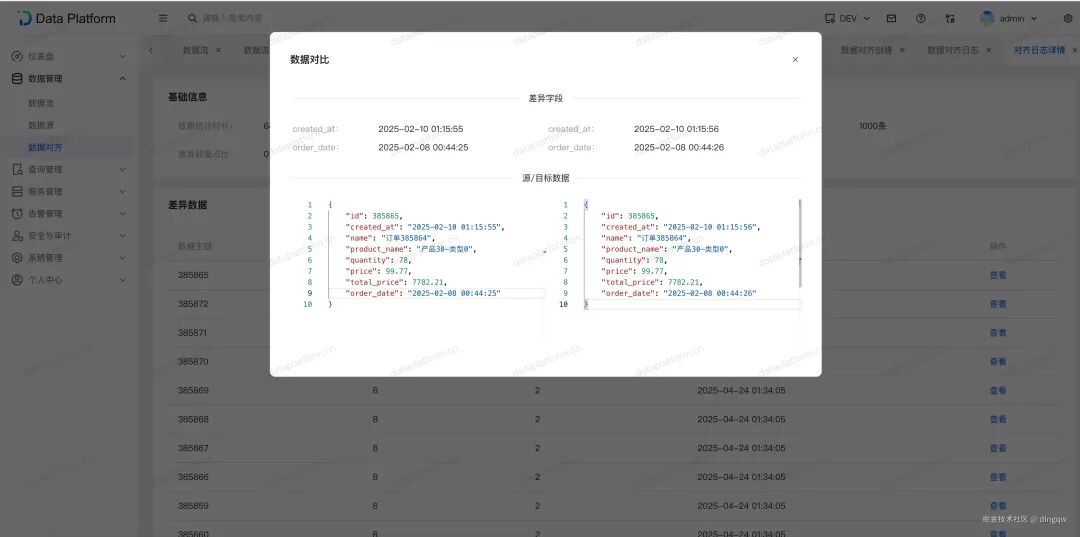
查询模板
此功能旨在将数据查询能力快速封装成API服务,减少后端开发重复编写查询代码的工作量。支持动态SQL、权限控制、限流、缓存等。
-
查询模板列表:管理所有已创建的查询接口模板。
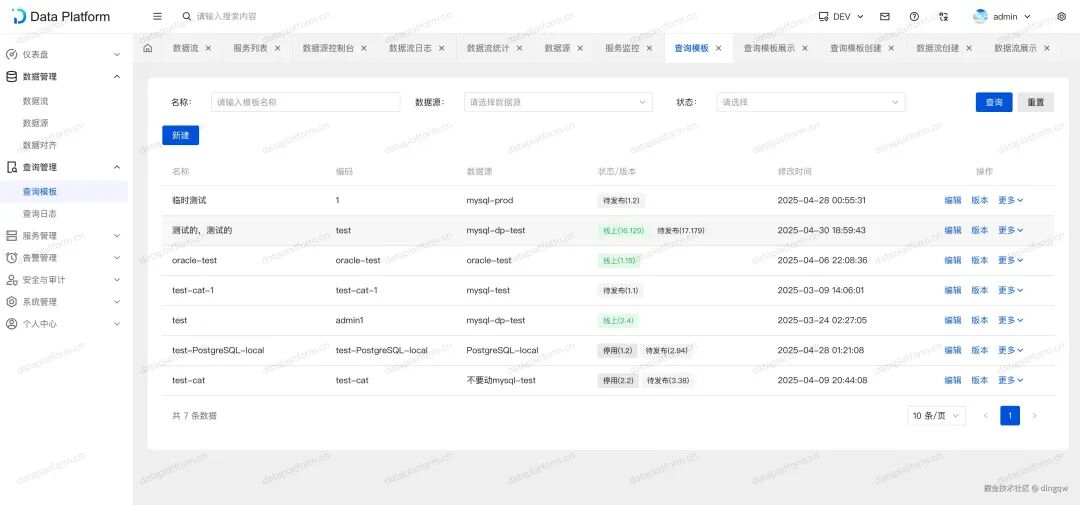
-
创建查询模板:编写SQL(支持MyBatis动态条件语法),并配置请求参数映射。
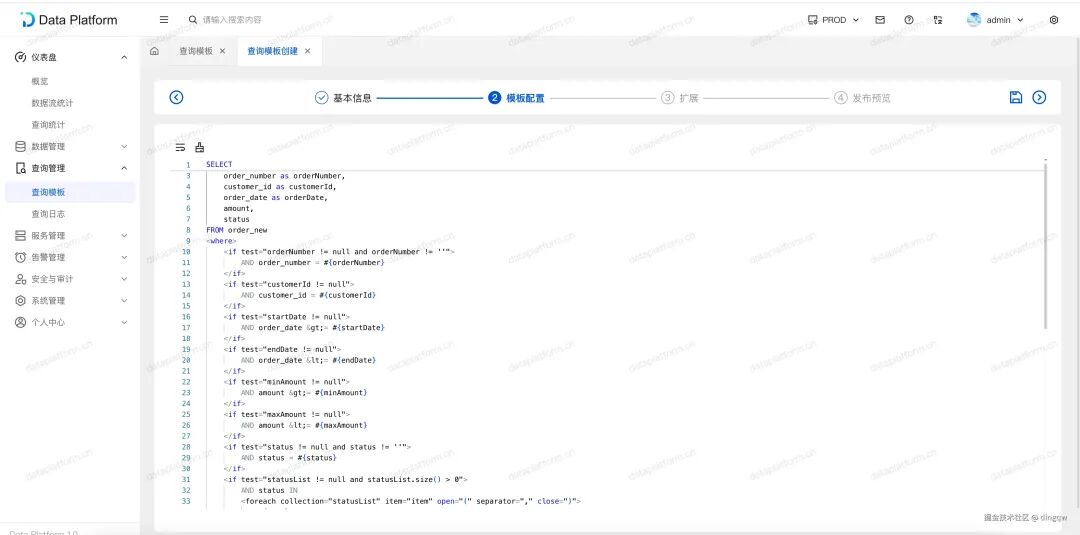
同时可以配置接口的超时时间、缓存、限流规则和日志记录开关。
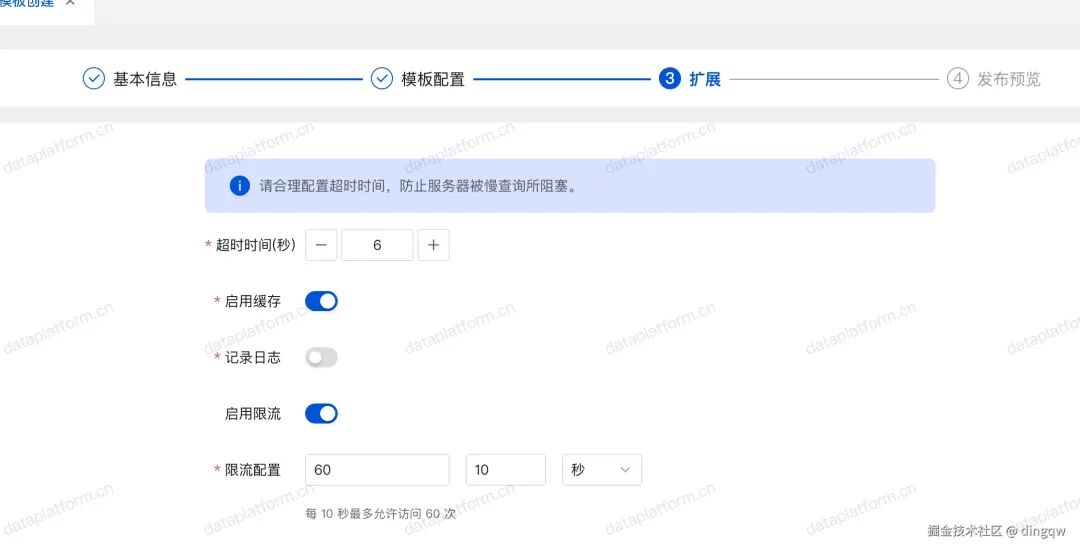
-
接口测试与发布:提供交互式测试界面,生成不同语言的调用示例,测试无误后即可发布。
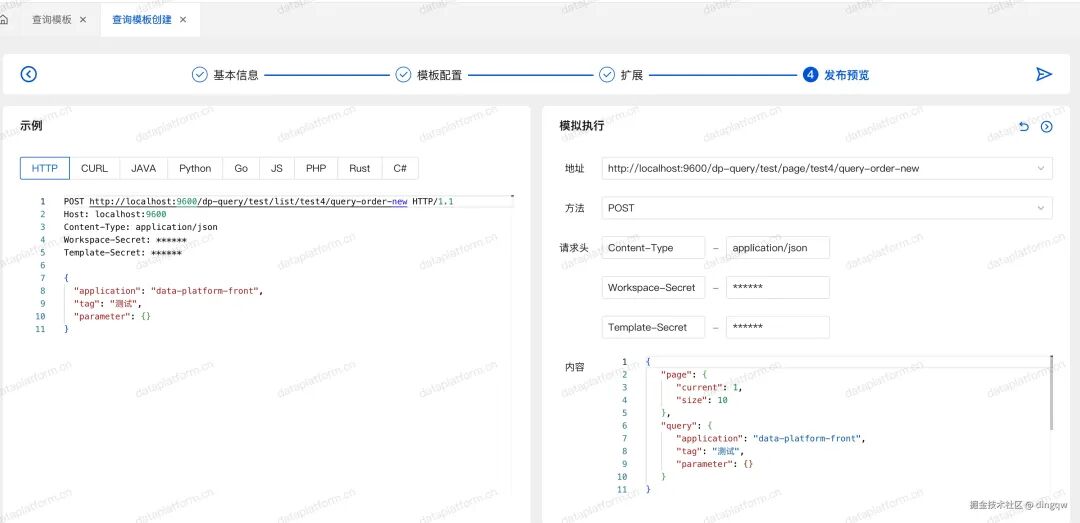
-
调用日志审计:所有通过查询模板发起的调用均被记录,包括请求参数、响应结果、耗时、状态等,便于审计和问题排查。
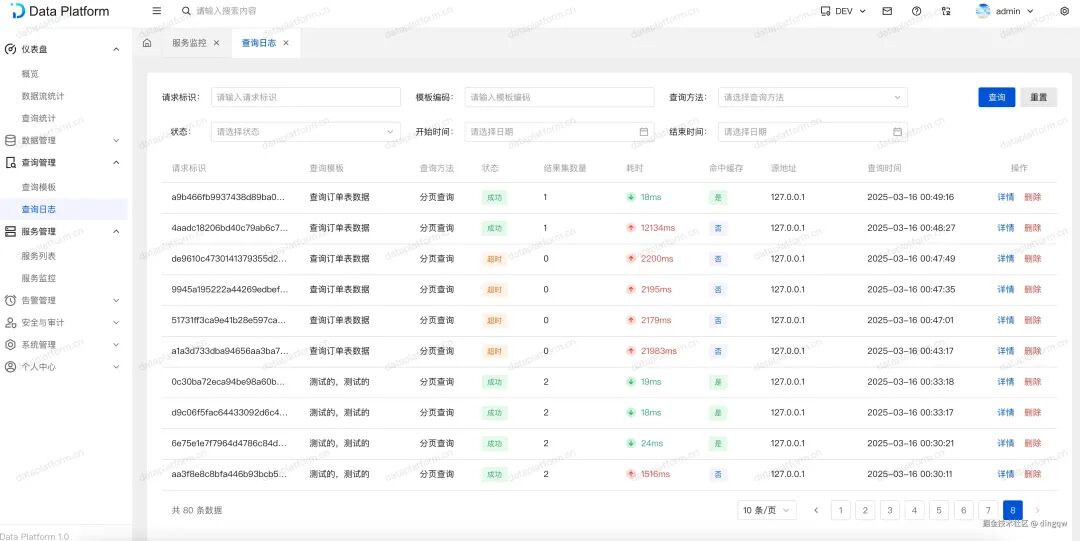

性能测试参考
根据平台提供的测试数据,在单实例(6核12G配置)环境下,其处理能力如下:
| 模式 |
硬件规格 |
实例数量 |
速率(单任务) |
| 监听-流处理 |
6c12g |
1 |
30058条/秒 |
| 批处理 |
6c12g |
1 |
60268条/秒 |
需要注意的是,以上为单任务性能。在分布式部署模式下,通过水平扩展实例,平台的整体吞吐量可以线性增长。
总结
这款可视化拖拽数据流平台通过降低数据开发的技术门槛,将数据同步、清洗、对齐及API服务封装等常见需求产品化。其版本管理、监控告警、弹性伸缩等特性也考虑了生产环境下的可用性与运维效率。对于寻求提升数据团队交付效率、实现低代码数据运维的企业或项目来说,是一个值得探索和评估的方案。如果你想了解更多此类技术实践或与同行交流,可以到 云栈社区 的相关板块看看。 |  发表于 2026-2-24 05:55:06
|
查看: 138|
回复: 0
发表于 2026-2-24 05:55:06
|
查看: 138|
回复: 0