分布式系统是构建大型架构的核心,而如何保证数据的一致性是其关键挑战之一。下面我们将详细解析分布式环境下常见的四种一致性方案。
强一致性(强同步协议)
强一致性要求任何一次写操作成功后,所有后续的读操作都能立刻读到最新的数据。
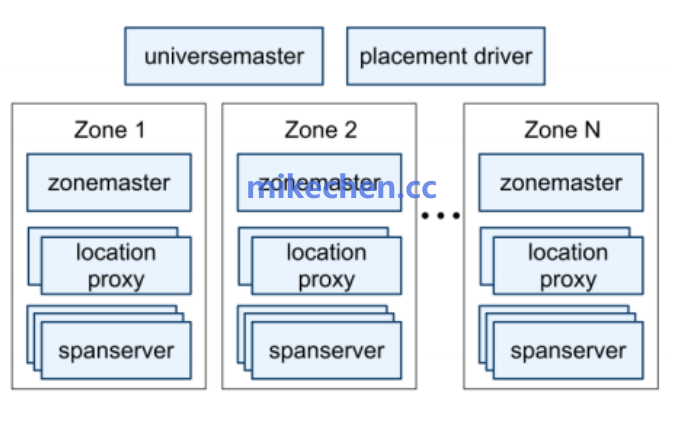
图1:典型的强一致性分布式系统架构示意图
其主要特征包括:
- 写操作必须等待多个节点确认后才能完成。
- 任一节点不可达,都可能导致整个服务不可用。
- 代表方案:两阶段提交(2PC)、三阶段提交(3PC)、Paxos、Raft 等分布式共识算法。
适用场景:适用于对数据准确性要求极高的场景,如金融系统的资金扣款。
优点:
- 读写操作后立即可见一致状态,逻辑简单,易于理解和验证。
缺点:
- 性能开销大,需要等待所有副本同步。
- 写操作需要跨网络进行确认,这会显著增加请求延迟(Latency)。
最终一致性(异步复制)
最终一致性是指系统在短时间内允许数据状态不一致,但在没有新写入的前提下,系统最终会收敛到一致的状态。
这是目前互联网分布式系统中最常用的技术方案。
代表方案:数据库的异步主从复制、Gossip 协议、基于消息队列的异步数据同步。
优点:
- 写入延迟低、系统可用性高(在网络分区时仍能提供读写服务),非常适合高吞吐量场景。
缺点:
- 短期内存在数据不一致的窗口期,应用层需要妥善处理可能的数据冲突和读到旧数据的情况。
弱一致性与可变一致性
在这种模型下,系统不保证读操作一定能读到最新写入的数据。它极度放松了对一致性的约束,以强调系统的性能和可用性。
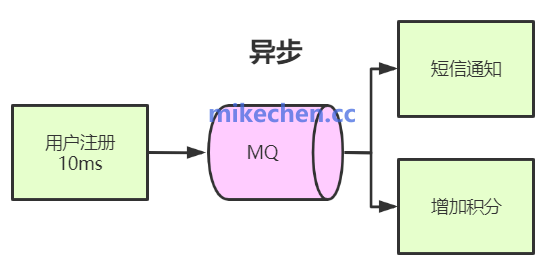
图2:基于消息队列的异步处理流程,常应用于弱一致性场景
该模型常用于缓存或临时数据存储,不适合对数据有强持久化要求的场景。
常见实现策略包括:读写分离、容忍读副本的延迟、客户端缓存以及使用向量时钟等进行版本控制。
优点:策略灵活,能极大提升系统性能与可用性。
缺点:增加了应用端的逻辑复杂性,开发者必须明确不一致的时间窗口并设计好补偿逻辑。
分区与分片一致性
这并非标准的一致性模型,而是针对数据分区(Partitioning,将数据分成独立部分)和分片(Sharding,将分区分布到不同节点)场景下,如何维护数据一致性的策略。

图3:分布式系统的物理基础——数据中心服务器集群
其重点是确保跨分区/分片的数据一致性,保证整个系统视图的统一,尽管数据在物理上是分散存储的。
常见做法包括:
- 使用分布式事务协议(如 XA、基于两阶段提交的全局事务)来保证跨分区操作的原子性。
- 设计为最终一致性的补偿型事务,例如 Saga 模式。
优点/缺点:分布式事务能保证强一致性但会牺牲性能与可用性;而 Saga 等模式通过拆分与补偿提高了可用性,但增加了业务逻辑的复杂度。 |  发表于 2025-12-31 02:23:47
|
查看: 196|
回复: 0
发表于 2025-12-31 02:23:47
|
查看: 196|
回复: 0
