前两天我写了一篇《OpenClaw 是怎么工作的?一条消息的旅程讲清楚》,算是给整个系统画了一张总览图。
反响还不错,但有朋友问了一个很现实的问题:看懂了消息怎么流转,可我自己做类似系统的时候,还是到处踩坑——断线重连丢状态、重试触发重复执行、长任务把网关线程卡死。
这些问题有一个共同的根源:能跑通 ≠ 跑得稳。
消息能发出去、模型能回答,这只是 L1。真正的挑战在 L2:客户端断了怎么办?重试安不安全?30 秒的作业谁在追踪?可观测性有没有契约,还是全靠翻日志拼图?
今天这篇来分析一个点:控制面为什么要做成"两阶段协议",以及 runId 为什么是整个系统的观测抓手。
太长不看版(8 条)
- 控制面不是"让你点按钮的 UI",而是系统的协议契约:谁能连、能调哪些方法、能订阅哪些事件。
- OpenClaw 的 WebSocket 连接必须先
connect,服务端先发 connect.challenge(nonce),客户端必须在 10 秒握手超时 内完成认证,超时直接关闭(close code 1008),这不是形式主义,是在防重放、防半连接挂起。
agent 设计成"两阶段"是为了把长任务变成可控作业:先 accepted(给 runId),再 streaming(事件),最后 final(结算)。源码中 respond(true, accepted) 立即返回,后台 agentCommand(...) 异步执行。- 幂等键不是"锦上添花",是写进 TypeBox Schema 的 required 字段。没有幂等键,你的
send 和 agent 请求连 AJV 校验都过不去。
- 方法鉴权要保守:
operator.read/write/admin/pairing/approvals 五个 scope 常量,node 角色只允许 3 个方法(node.invoke.result、node.event、skills.bins),未知方法默认要求 admin。
- 去重机制分两层:
context.dedupe(已完成结果缓存,跨请求)+ inflightByContext(飞行中并发合并,WeakMap 随连接断开自动 GC)。不是一层 Map 能搞定的。
- 事件不重放意味着:客户端要学会"间隙恢复"——重连后拿
hello-ok 快照,主动拉 sessions/health,对还在跑的 run 走 agent.wait。
- 做同类系统时,最应该先抄的不是 Prompt,而是这套控制面契约:握手、鉴权、幂等、观测点。
1)不是聊天,是作业系统
很多团队做 Agent,下意识把它当"聊天"——发一条消息,等模型回一句话,完事儿。
这就像快手那篇 AI Coding 实践里说的:大部分人觉得"我已经在用 AI 了",但其实只用到了最浅的一层。Agent 系统也一样,你觉得"消息能收发了",但离生产可用还差得很远。
一旦接入真实世界,Agent 的行为模式更像"作业系统":
- 作业可能很长(推理 + 工具调用 + 子智能体编排),30 秒是家常便饭。
- 作业有副作用(发消息、写文件、调用 exec、触发节点能力如
camera.snap、canvas.navigate)。
- 作业随时可能被中断(断网、客户端崩溃、服务重启、provider 限速)。
- 并发有硬约束——同一会话必须串行(session lane
maxConcurrent=1),全局受 agents.defaults.maxConcurrent 限制。
到了这一步,控制面要回答的问题就变了:不再是"消息到了没有",而是——
怎么证明作业被系统接住了?怎么追踪进度?怎么在网络抖动下不重复执行?
OpenClaw 的答案:把 agent 做成"两阶段"。
2)两阶段协议长什么样
一句话概括:先接单,再干活。
网关对客户端的"RPC 合同"可以写成这样:
connect.challenge(nonce) ← 服务端主动推
connect(req, auth, device) → hello-ok(methods, events, snapshot, policy)
agent(message, idempotencyKey) → accepted(runId)
event:agent(streaming, seq) ← 异步推送
agent(final) → ok/error(runId, summary)
整个协议只有 3 种帧类型(定义在 GatewayFrameSchema,TypeBox 联合类型 + discriminator: "type"):
| 帧类型 |
type 字面量 |
方向 |
用途 |
| Request |
"req" |
客户端→网关 |
方法调用 |
| Response |
"res" |
网关→客户端 |
调用结果 |
| Event |
"event" |
网关→客户端 |
异步事件推送 |
完整的交互时序如下:
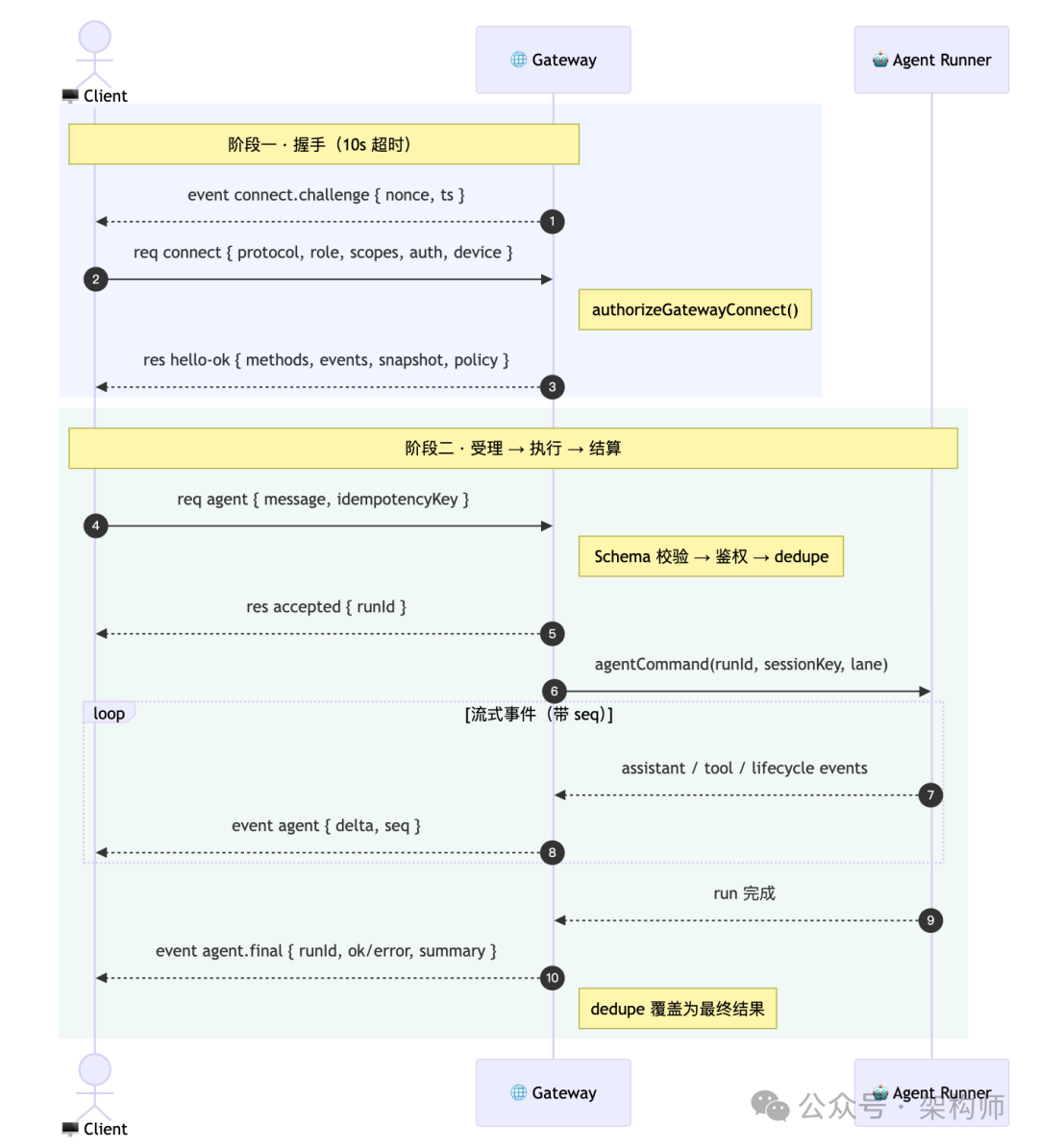
这个设计一次性钉住了 4 个关键约束:
| 约束 |
机制 |
工程价值 |
| "接住了"可证明 |
accepted 硬回执,立即拿到 runId |
不用猜请求是否被网关丢弃 |
| "等多久"可治理 |
控制面只负责受理,执行面走 lane 调度 |
长任务不阻塞网关线程 |
| "重试"可安全 |
幂等键 + 两层 dedupe |
同 key 请求不触发两次执行 |
| "观测点"可统一 |
runId 串联事件流 + 工具 + 结算 |
排障不再拼日志猜关联 |
这就是工程上的本质差异:你不是在做一个聊天窗口,而是在做一个可观测、可重试的作业调度面。
到这里可能有人会想:道理我都懂,但两阶段能工作的前提是什么?是连接本身要靠谱。如果连接都不可靠,accepted 发出去客户端收不到,那一切都白搭。
所以我们得先看看 OpenClaw 怎么解决连接可靠性的问题。
3)握手为什么要 challenge——别让控制面被"半连接"拖死
OpenClaw 在 WebSocket 层做了三件事来保证连接可靠:
A. 第一帧必须是 connect
message-handler.ts 里的消息状态机只有两个阶段:
| 阶段 |
接受的帧 |
拒绝行为 |
| 未连接 |
仅 method=connect |
关闭连接,不允许其他方法 |
| 已连接 |
普通 request frame |
交给 handleGatewayRequest |
好处很朴素:不允许"未认证但已发命令"的半连接状态存在,状态机更简单,超时直接关。
B. 服务端先发 challenge(nonce)
// 握手超时:10 秒内未完成 connect 握手则关闭
const handshakeTimer = setTimeout(() => {
ws.close(1008, "handshake timeout");
}, getHandshakeTimeoutMs());
connect.challenge 携带随机 nonce + 时间戳。非本地场景下,客户端签名必须包含该 nonce——旧签名无法复用到新连接:
// device nonce 校验
const providedNonce = connectParams.auth?.nonce;
if (providedNonce && providedNonce !== connectNonce) {
ws.close(1008, "device nonce mismatch");
return;
}
签名校验链覆盖完整的 payload 构建 + 验签(支持 v1/v2 格式兼容),确保 device.id 与公钥推导一致、签名时间戳未过期、nonce 匹配。
C. 认证判定有明确优先级
authorizeGatewayConnect 按固定顺序判定,先到先决:
trusted-proxy 模式(验证代理来源 + 指定用户头)- 限速检查(
rateLimiter,设备令牌和共享密钥使用独立 scope,互不影响计数)
- Tailscale 身份验证(
tailscaleWhois)
- Token / password 比对
本地直连检测(isLocalDirectRequest)则有三重条件:客户端 IP 是 loopback 且 Host 是本地域名或 .ts.net 且 无转发头或转发来自可信代理。
一句话:控制面认证靠协议强约束,不靠"部署时别搞错"的祈祷。
3.5)一个真实的坑:Control UI "connect failed"
我见过最容易把新人劝退的一幕:
把 Gateway 跑在一台机器上,用另一台的浏览器打开 http://<lan-ip>:18789/,UI 提示 connect failed 或 device identity required。
很多人第一反应是检查 token 和端口。但更常见的原因是:浏览器处在 HTTP 非安全上下文,WebCrypto API 被限制,UI 根本生成不了设备身份(device.id + publicKey + 签名),握手阶段就卡住了。
这件事暴露的是协议设计的一个深层约束:所有 WebSocket 客户端在 connect 时必须包含设备身份(除非显式开启 allowInsecureAuth),非本地连接必须签署 nonce。
解法很明确,都在"控制面边界"里,而不是"渠道配置"里:
- 走 HTTPS(Tailscale Serve / 反代),让 WebCrypto 正常工作;
- 或 loopback 本地访问(
127.0.0.1);
- 或 SSH 隧道转发。
写这段不是为了讲"怎么用",而是强调:控制面要把"远程访问的默认形态"也纳入协议设计。
连接和认证解决了"谁能进来"的问题。接下来要回答的是:进来之后,能干什么?
4)鉴权为什么这么"保守"
控制面最怕的事情很朴素:某天新增了一个方法,忘了加权限,结果默认放行了。或者某个插件注入了一个 handler,绕过了核心安全边界。
这类问题的根源都是一样的——默认策略太宽松。OpenClaw 的做法不是喊"最小权限"口号,而是代码级强制。
角色层:node 只给 3 个方法
const NODE_ROLE_METHODS = new Set([
"node.invoke.result", // 返回调用结果
"node.event", // 上报事件
"skills.bins", // 获取 skill 可执行文件列表
]);
node 角色命中白名单才放行,其他一律拒绝——能力宿主(camera/screen/canvas)不需要也不应该碰控制面方法。
Scope 层:9 步判定链
authorizeGatewayMethod(server-methods.ts)的完整判定逻辑:
❶ node 角色 → 只允许 NODE_ROLE_METHODS(3个)
❷ operator.admin → 直接放行全部
❸ "exec.approvals." 前缀 → 强制 admin
❹ ADMIN_ONLY_METHODS(config.set / update.install / sessions.delete 等)→ 强制 admin
❺ APPROVAL_METHODS(3个) → 要求 approvals 或 write
❻ PAIRING_METHODS(11个) → 要求 pairing(write 不覆盖)
❼ READ_METHODS(15+个) → 要求 read 或 write
❽ WRITE_METHODS(14个) → 要求 write
❾ 未知方法 → 要求 admin(保守默认)
最关键的是第 ❾ 条:未知方法默认不授权。这不是安全洁癖——当你有插件(extraHandlers 优先于 coreGatewayHandlers)、子系统、版本演进时,"默认放行"迟早会以最难看的方式爆炸。
还有一个容易忽略的细节:operator.write 隐含了 read 权限,但 operator.pairing 是独立 scope,必须显式授予。配对操作的敏感性决定了它不能被 write "顺带"覆盖。
做架构评审时,我会把这一条写成硬指标:任何新增控制面方法,必须有明确 scope 归属,否则不上线。
好了,连接可靠了,权限也管住了。下一个问题来了:客户端断线重连后重试请求,怎么保证不把同一件事做两遍?
5)幂等键:重试的底座,副作用治理的起点
自动重连一旦做了,"请求到底发出去没有"就成了薛定谔问题——客户端不确定,就会重试。
没有幂等键的重试,后果可以预见:同一条消息发两次、同一个工具执行两次、同一个外部系统被打两次写操作。然后你开始在业务层打补丁——工具层去重、数据库加唯一索引、UI 禁用按钮。都能缓解,但都不是根治。
根治方案只有一个:控制面把幂等变成契约。
两层去重:不是一个 Map 能搞定的
OpenClaw 的幂等实现分两层,这是我在源码中看到最值得借鉴的设计之一:
第一层:context.dedupe(已完成结果缓存)
// 跨请求的历史缓存
const dedupeKey = `agent:${idem}`;
const cached = context.dedupe.get(dedupeKey);
if (cached) {
respond(cached.ok, cached.payload, cached.error, { cached: true });
return;
}
第二层:inflightByContext(飞行中并发合并)
// 外层 WeakMap 以 GatewayRequestContext 为 key,连接断开时自动 GC
const inflightByContext = new WeakMap<
GatewayRequestContext,
Map<string, Promise<InflightResult>>
>();
// 同 key 并发请求复用同一 Promise,只真正执行一次
const existing = inflight.get(dedupeKey);
if (existing) {
const result = await existing;
respond(result.ok, result.payload, result.error);
return;
}
| 层次 |
作用 |
范围 |
生命周期 |
context.dedupe |
已完成请求的结果缓存 |
跨连接生命周期 |
持久化层管理 |
inflightByContext |
飞行中请求并发合并 |
单次连接上下文 |
WeakMap 随断连 GC |
agent 的 dedupe 写了两次——这个细节很重要:
// 立即写入 accepted(客户端重试会拿到同一个 runId)
context.dedupe.set(`agent:${idem}`, { ts: Date.now(), ok: true, payload: accepted });
respond(true, accepted); // 立刻返回
// 后台异步执行完成后,覆盖为最终结果
void (async () => {
const result = await agentCommand(...);
context.dedupe.set(`agent:${idem}`, { ts: Date.now(), ok: true, payload });
// 或失败
context.dedupe.set(`agent:${idem}`, { ts: Date.now(), ok: false, payload, error });
})();
前缀不同不会碰撞:send:${idem} / poll:${idem} / agent:${idem}。
Schema 级强制:没有幂等键连校验都过不去
幂等键在 AgentParamsSchema 和 SendParamsSchema 中都是 required NonEmptyString,additionalProperties: false。客户端不传这个字段,AJV 校验直接 400,连业务逻辑的门都进不了。
幂等键怎么设计
两条规则写死:
- 客户端生成,服务端只管"同 key 不重复副作用"。
- 跨重连保留,否则重连一次就等于换了一个请求。
实现上不需要花哨——UI 侧每次点"运行"生成一个 UUID 绑定到本地记录;消息入口侧如果能拿到上游平台的稳定 message id,直接编码进 key。不要用"时间戳 + 随机数",因为你最后解释不清哪次重试算"同一请求"。
工程方法派最怕的不是"没优化",而是"没有合同,只有习惯"。
幂等解决了"重试不重复"的问题。但还有一个问题:客户端掉线那段时间发生的事件,能补回来吗?
6)事件不重放——你需要"间隙恢复",而不是幻想永远在线
很多人默认 WebSocket 订阅就像消息队列——断线重连后能回放。但 OpenClaw 在架构文档中写得很明确:
事件不会重放;客户端必须在出现间隙时刷新。
这意味着掉线期间的事件补不回来。事件帧携带 seq 和 stateVersion,但那是给你做间隙检测用的,不是回放用的。
因此设计控制面时,你必须同时写下两套路径:
| 路径 |
触发时机 |
机制 |
| 推 |
正常在线 |
订阅事件(agent/chat/presence/heartbeat/cron),广播有 scope 过滤 + 慢消费者保护 |
| 拉 |
间隙/重连 |
刷新快照(hello-ok.snapshot + sessions.list + health),把状态拉齐 |
只做推路径的系统看起来很酷,但一旦有网络抖动就变成"偶现 bug 地狱"。
最小间隙恢复流程(可抄)
客户端恢复动作固定 3 步:
- 重连 → 重新
connect → 拿新的 hello-ok(含 snapshot.presence + snapshot.health + policy)。新连接会生成新的 connId 和 nonce。
- 主动拉一次
sessions.list + status + health,校准 UI 状态。
- 对本地有
runId 记录但未收到 final 的 run,走 agent.wait 拉结果——别依赖"流式事件一定补齐"。
这三步做完,"网络抖动导致 UI 偶现卡死"会少一大半。
💡 补充:事件广播不是全量广播。敏感事件(审批/配对)只推给有对应 scope 的连接,慢消费者(bufferedAmount 超阈值)会被跳过。客户端不能假设自己收到了所有事件——间隙恢复是必需品,不是锦上添花。
以上讲的都是运行时的机制。但还有一个更前置的问题:如果客户端发过来的数据本身就是错的,后面所有机制都白搭。所以 OpenClaw 在协议层就把脏数据拦住了。
7)错误前置:脏数据不进业务层
OpenClaw 用 TypeBox + AJV(不用 zod)做协议校验,策略很简单——在业务逻辑之前,把所有不合法的东西挡在门外:
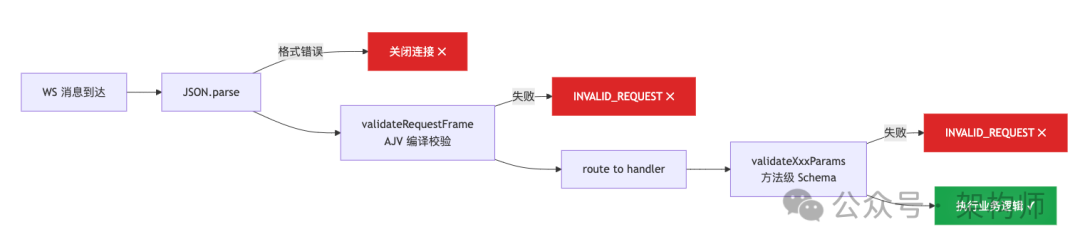
协议版本协商是显式的:PROTOCOL_VERSION = 3,客户端 minProtocol <= 3 <= maxProtocol,不匹配直接拒绝。
错误码体系只有 5 个值:NOT_LINKED、NOT_PAIRED、AGENT_TIMEOUT、INVALID_REQUEST、UNAVAILABLE。所有 handler 通过 errorShape(ErrorCodes.XXX, message) 统一返回,前端按 error.code 做逻辑判断,不靠解析 message 字符串。
工程启示:把格式错误拦截在协议层,业务代码可以假设入参合法。这不是多余的防守,而是降低整个系统的认知负担。
8)可抄清单:控制面的 12 条不变量
前面 7 节拆的都是具体机制。但如果你准备做一个类似系统,最好把这些机制提炼成不变量——写进设计文档,当硬约束维护,而不是当最佳实践建议。
下面 12 条,每一条都标注了 OpenClaw 中的对应实现:
连接层(1–3)
- 连接必须握手成功才允许调用方法——两阶段状态机,未 connect 只能 connect
- 握手必须有超时,超时直接关——默认 10 秒,close code 1008
- 非本地连接必须通过 challenge-nonce 参与认证——防重放,旧签名不可复用
协议层(4–6)
- 方法必须 Schema 校验——TypeBox + AJV,
additionalProperties: false,拒绝未知字段
- 角色与 scope 表达最小权限——
operator(5 scope)+ node(3 方法白名单)
- 未知方法默认拒绝——
"unknown method requires operator.admin"
执行层(7–8)
- 有副作用的方法必须强制幂等键——
idempotencyKey: NonEmptyString,required
- 长任务必须两阶段——先 accepted 后 final,dedupe 写两次
观测层(9–12)
- 事件必须带序号——
seq + stateVersion,客户端做间隙检测
- 推拉双路径——推:
broadcast(event);拉:hello-ok.snapshot + sessions.list + health
- 区分"服务存活"和"RPC 可达"——
health 方法 vs heartbeat/tick 事件
- 排障输出必须能安全分享——5 个标准
ErrorCodes,secrets 不出现在协议层
写完这份清单你会发现,很多被归咎于"模型不稳定"的问题,其实是控制面契约没立住。
就像快手用数据证明的那个不等式——用 AI 工具 ≠ 个人提效 ≠ 组织提效。Agent 系统也一样:能跑通 ≠ 跑得稳 ≠ 可运维。中间差的不是模型能力,而是你的控制面契约有没有真正钉死。
如果你想深入了解这类分布式系统的设计模式与实现细节,欢迎在云栈社区的相关板块进行交流与探讨。
 发表于 2026-2-24 07:48:25
|
查看: 317|
回复: 0
发表于 2026-2-24 07:48:25
|
查看: 317|
回复: 0
