如果说训练大模型的目标是稳定且高效地 Scale Up,那么 Agentic RL 给人的印象往往是既不稳定,也不高效,对于资源有限的团队来说,也很难进行有效的扩展。
笔者近期在一家初创公司进行了三个多月的 Agentic RL 实践,对相关技术有了更深的体会。本文将采用逆向视角,先从 Agentic RL 谈起。
关于 Agentic RL 的实践挑战
1. Rollout 阶段速度过慢
这里的“慢”,并非指参数更新的训练侧,而是指与环境交互的 Rollout 阶段。
Agent Rollout 通常需要在多个独立的 Docker 容器中进行交互,一些任务难免包含耗时操作,例如通过 apt 或 pip 安装依赖、使用 wget 下载文件等。网络请求虽可优化(如使用代理或缓存),但对于 LLM 生成的复杂算法,其运行时的环境交互时间也常常高达数十秒。
即便利用 asyncio 将所有轨迹采集写成异步,仍可能观察到 GPU 资源空转。在高环境交互成本下,完全异步化和低精度 Rollout 都难以显著改善,因为瓶颈在于环境反馈速度,而非 GPU 计算。
这最终导致了一个典型矛盾:训练侧消费数据过快,而生产侧(Rollout)生成数据过慢。虽然有研究(如 Meta 的 arXiv:2511.03773)尝试用 LLM 模拟真实环境,但对于涉及复杂系统逻辑(如需要深入理解的软件 Bug)的任务,很难相信 LLM 能推理出完全正确的环境状态。
在实践中,优化 Rollout 时间是重中之重,除了提升推理引擎速度,也需要大量精力优化环境交互逻辑。我们时常设想:如果存在一个交互极快、任务海量且多样性极高的仿真环境,那该多好。
2. 训练过程的不稳定性
不稳定的因素众多,可能源于环境噪声、算法缺陷或训推不一致。
- 环境问题:训练环境本身可能不完美,如 Docker 镜像问题、依赖冲突、超时等,导致 LLM 做出了正确决策却无法获得奖励。
- 算法问题:对负奖励样本的处理、Rollout 轨迹的过滤,特别是决定将哪些数据送入训练侧,会极大地影响训练效果。
- 训推不一致:这是非常有趣的一点。最初因推理与训练引擎不一致而出现 TIS(训推不一致)问题;训练混合专家模型时,又因专家选择不同而引入了 R2、R3、GSPO 等问题。测试模型对离线策略(Off-policy)数据的容忍度,本身也成为工程实践的一部分。这部分内容,年底阿里巴巴通义千问团队的文章(arXiv:2512.01374)总结得非常到位。
- 玄学 Bug:例如,Rollout 产生的 Token 经解码成文本后再编码回 Token,可能与原始 Token 不一致。总之,如何稳定地延长 Agentic RL 的训练周期,是一个核心难题。
3. 工程扩展的难度
难以扩展的原因主要源于上述两个问题:Rollout 慢导致训练步数难以增加,不稳定则易导致奖励崩溃。但除此之外,工程上的复杂度也是重要障碍。
随着 Agentic RL 和 RL 基础设施的发展,训练的工程复杂度日益增高。现阶段,算法与系统的耦合变得越来越紧密。想要高效实验新想法,需要深入理解整个 RL 框架的设计。有时一个复杂的算法构思,可能需要在训练侧和推理侧同时进行工程适配。
在推理侧,如何编写异步代码,使 Docker 容器启停、环境交互与 GPU 计算时间充分重叠,以打满 GPU 利用率至关重要。同时,也需要考虑哪些操作会阻塞事件循环、可能导致死锁。这些工程能力是传统监督学习时代较少涉及的。
调试一个 RL 系统也颇具挑战。由于许多环节存在随机性,有时连 Bug 本身都难以复现——这次训练出现的 Bug,重启一次后可能就消失了。好在像 SLIME 这样的框架提供了 Rollout 调试功能,可以保存上一次的 Rollout 数据供下次训练复用,这既节省了重新 Rollout 的时间,也有助于复现 Bug。
在 Agentic RL 时代,对工程能力的要求越来越高。可维护的代码、模块化解耦的设计、并行与异步的考量,以及对训推框架(如 Megatron、FSDP、SGLang、vLLM)的掌握,都应成为必备技能。整个优化过程对计算资源与工程效率提出了巨大挑战。
关于 RL 与推理能力
年初 DeepSeek-R1 的发布,以其思维链长度持续增长的曲线,点燃了社区对推理和强化学习的热情,似乎暗示模型能通过 RL 无限提升以解决更难的问题。
但后来的发展表明,在简单配置下,RL 并不能让模型能力无限提升。当时有一种观点认为,RL 本质上是在“抽签+筛选”,即 RL 并不能提升基础模型的能力上限,只是在放大其某一方面的能力。arXiv:2504.13837 中的一张图形象地说明了这一点。
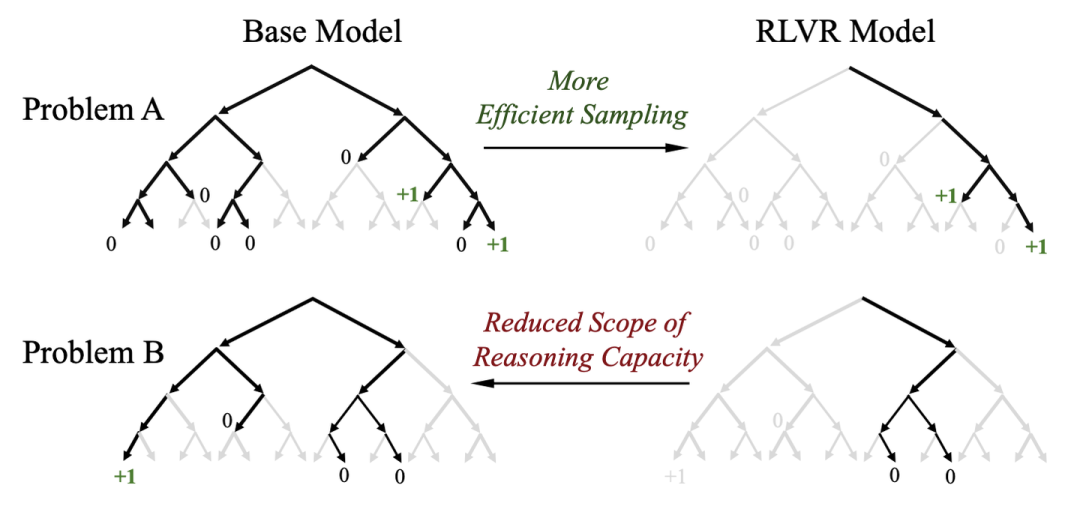
图源:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
训练开始时,模型本有多种推理路径,但 RL 会筛选掉无法获得奖励的轨迹,导致 RL 训练后的模型在 Pass@1 指标上表现优异,但在 Pass@K 上可能反而不如基础模型。这篇论文虽几经质疑,最终在 NeurIPS25 获得了高分。
如今,我的看法有所改变。这要从 RL 的一个重要副产品——思维链说起,它扮演了至关重要的角色。
1. CoT 是在搜寻一个压缩的概率空间
如果将 LLM 的输出比作“无限猴子打字”,虽然理论上能在无数次采样中找到正确答案,但关键在于其输出的概率空间极其巨大。CoT 可以被视为一个条件,我们希望 P(Y | CoT, Prompt) 能提供一个比 P(Y | Prompt) 更优的概率分布,从而让采样到正确答案变得更容易。
2. CoT 是自然语言形式的潜在空间
机器学习的核心在于特征。我们知道,特征是数据的有效表达,骨干网络生成的特征越强,后续任务头就越容易得到好结果。
CoT 就是一种自然语言形式的潜在特征。 它作为媒介,让模型能够调用一套对各种任务都通用的元能力来解题。也就是说,任务千变万化,但解决任务的能力可能是一个有限且通用的集合。如果说传统的特征提取器是在提取数据的有效表达,那么 RL 训练出的 CoT 就是在提取“解决任务的能力”的通用表示。最迷人的是,这种潜在特征是以人类可读的自然语言呈现的。
那么,RL 能提升基础模型的能力吗?可以,只是我们还不能稳定地做到这一点。 RL 提供了激励,但“如何”有效激励才是关键。
RL 的泛化能力
年初除了思维链曲线,RL 模型展现出的优异泛化能力同样令人兴奋。SFT 常面临灾难性遗忘问题,而 RL 不仅保留了模型原有的大部分能力,甚至能在任务 A 上训练后,提升在任务 B 上的表现。
当时我思考:对比 RL 和 SFT 的公式,它们看起来很相似,RL 的优势究竟在哪?一个关键区别在于:RL 的数据是模型自身合成的(On-policy),采样自其当前的分布;而 SFT 的数据分布往往与模型当前的分布存在较大偏差。 后来的论文 arXiv:2509.04259 也专门探讨了这一点。
至于为何能展现出对分布外(OOD)任务的能力,如前所述,CoT 正作为一种高效的潜在特征,让模型调用通用的任务解决能力来应对未见过的难题。
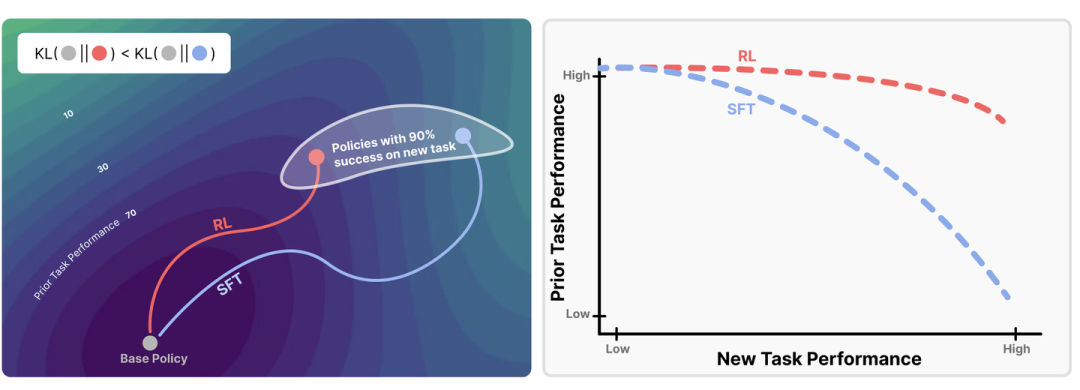
图源:RL’S RAZOR: WHY ONLINE REINFORCEMENT LEARNING FORGETS LESS
这一年来,RL for LLM 修复了不少 Bug,算法迭代了数轮,各种“XXPO”层出不穷。虽然系统层面已经历多次进化,减少了 Off-policy 数据并提高了效率,但仍有问题待解。RL 的基础设施在易用性与效率之间总需要权衡。
总的来说,我们非常期待未来社区在 Agentic RL 上的研究进展,早日让 LLM 能够真正代理人类完成现实世界中的复杂任务。
 发表于 2026-1-3 03:59:54
|
查看: 287|
回复: 0
发表于 2026-1-3 03:59:54
|
查看: 287|
回复: 0
