我花了半天时间才把Gemini老师推荐的开源项目在本地跑通,并且又花了2天时间把这个开源项目作为后端对接到我的vibe coding项目中,完成异步识别逻辑。
等我终于想起来问Gemini老师这件事可不可以更简单一点的时候,TA说:“我给你推荐另外一个开源项目......”
这是一个悲伤的坑,踩完之后我才是真的意识到想要在本地部署AI模型,“硬件”和“时效”真的是很重要的制约条件。
起因还是我想要实现转录并且储存一些很长的音频播客。国外的播客语速起飞又夹杂很多的俚语和我不知道的单词,没有可以储存的字幕完全无法消化。
做这件事最简单的方案当然是直接去找一个商业级别的语音识别API,但是我一查人家转录都是按照分钟收费的,有点心疼。更何况年初我本来就是为了打通黑神话自己组了一台电脑,咬牙配了RTX 5070,不用白不用。
我需要能够直接进行语音识别+时间戳输出+说话人区分的模型,要实现本地部署。这些需求输给Gemini,TA当然是立刻就推荐了Whisper系列的开源项目,其中使用了WhisperX项目完美的契合了我的诉求。
什么是WhisperX?
WhisperX是一个转录长音频的流水线,旨在解决 Whisper 长音频时间戳不准和无法并行推理的问题,它应用到了三种模型:
- 基础语音转文字:Whisper
- 词汇级别的强制时间戳对齐:wav2vec2
- 说话人识别:pyannote
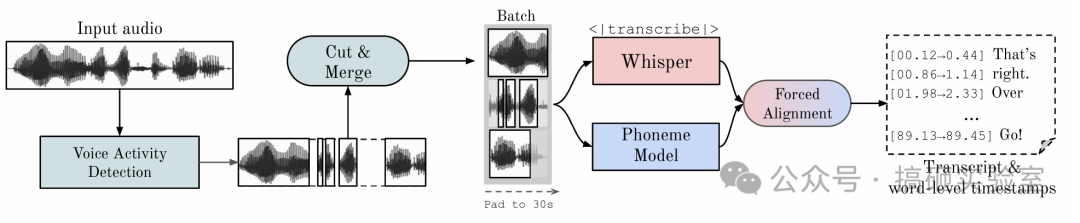
它的处理工作流是这样子的:
- 利用 pyannote 识别人声活动,把输入的长音频文件切割成非常小的块(30s左右)。
- 把小音频片段送给 Whisper 模型“并行”转录,可见这个速度是可以很快的。
- 转录的结果交给另外一个模型来把“词汇”与“音素(声音的基本单元)”进行匹配,从而产生出非常精准的时间戳。
- 把打好时间戳的文件跟音频对比分配说话人。
- 最后能够支持各种格式的转录文件输出,比如 json 和标准字幕文件 srt、vtt等。
硬件依赖与报错排坑
这个开源项目是23年提出的,现在已经有19k+ stars了,说明是有人维护的。于是我开始在自己的电脑上尝试安装。
首先用了项目首页推荐的 pip 安装。

按照作者说的方法,如果使用GPU进行推理,音频转录的速度会非常快。
我自己的实践也证明了这一点:我的设备转录一个 5min的音频,如果使用CPU推理大概需要2min;而后面调通了GPU之后,21秒左右就可以跑完整条转录+对齐+说话人识别流水线。这可是一个巨巨大的差别。
可是问题就恰好出现在我要求模型去“使用GPU推理”的时候。这个硬件依赖是怎么产生的呢?
首先,WhisperX使用的是Python语言,所有模型调用依托的都是 PyTorch。PyTorch作为一个极其流行的AI开发库,既有调用 CPU 推理的版本,也有调用 GPU 推理的版本。但是在使用 pip 安装的时候,默认下载的是 CPU 版本的 PyTorch,所以调用 WhisperX 的时候我直接走到了 CPU 推理的逻辑。
为了解决这个问题,我手动把 pip 下载的 PyTorch 卸载了,再手动安装一个可以调用 GPU 版本的 PyTorch。
一开始直接找到这个默认携带 CUDA 12.6 版本的 PyTorch,还是报错:“RuntimeError: no kernel image is available.”

Pytorch 是怎么可以调用 GPU 进行推理的?因为它使用了CUDA来调度底层硬件。我的显卡型号是 RTX 5070,我选择的打包了12.6版CUDA的PyTorch,还没有适配这个新硬件。我改成打包了13.0版CUDA的PyTorch,才不再报这个错误了:
import torch
print(f"PyTorch Version: {torch.__version__}")
# PyTorch Version: 2.9.1+cu130
print(f"Supported Archs: {torch.cuda.get_arch_list()}")
# Supported Archs: ['sm_75', 'sm_80', 'sm_86', 'sm_90', 'sm_100', 'sm_120']
不过改成这样,依然是跑不起来的——是 WhisperX 调用了 pyannote 去进行说话人识别导致的。
PyTorch版本一高(2.6+),它的安全策略就更加严格,对于 torch.load 默认传参 weights_only=True,导致加载 Whisper 和 Pyannote 模型时报 UnpicklingError 或 omegaconf 错误。
虽然 torch.load 非常好用,但它存在一个严重的安全性缺陷。pickle 的设计初衷是信任解析的数据的,它在加载文件时,可以执行文件里包含的任意 Python 代码。所以如果你加载的文件是含有恶意代码的,当你运行的瞬间,它可以在你的电脑上执行恶意脚本。
在 WhisperX 项目中,如果 torch.load 传参 weights_only=True,会报错。我跟着每次报错加白名单,反复好多次还是报错,最后只能写了个 wrapper 函数给他把这个参数强制改成了 false(当然在安全上来看就在裸奔了,不建议轻易尝试)。
# 强制关闭 weights_only 检查(解决 pyannote 模型加载报错)
try:
_original_torch_load = torch.load
def safe_load_wrapper(*args, **kwargs):
kwargs['weights_only'] = False
return _original_torch_load(*args, **kwargs)
torch.load = safe_load_wrapper
except Exception:
pass
这个问题解决了,运行一次 WhisperX 还是会继续报错。这是因为 pyannote 使用了比较旧版本的 PyTorch,新版本移除了/改变了 torchaudio 中部分旧 API(如 AudioMetaData,list_audio_backends,get_audio_backend),导致代码运行的时候直接崩掉。
于是又写了几个补丁函数,假装被删除的几个 API 还在(就是强行把人家删掉的 attribute 给加回去了)。
# 修复 torchaudio Nightly 缺少的 API
if not hasattr(torchaudio, “AudioMetaData”):
try:
from torchaudio.backend.common import AudioMetaData
setattr(torchaudio, “AudioMetaData”, AudioMetaData)
except ImportError:
from dataclasses import dataclass
@dataclass
class AudioMetaData:
sample_rate: int
num_frames: int
num_channels: int
bits_per_sample: int
encoding: str
setattr(torchaudio, “AudioMetaData”, AudioMetaData)
if not hasattr(torchaudio, “list_audio_backends”):
def _mock_list_audio_backends():
return [“soundfile”]
setattr(torchaudio, “list_audio_backends”, _mock_list_audio_backends)
if not hasattr(torchaudio, “get_audio_backend”):
def _mock_get_audio_backend():
return “soundfile”
setattr(torchaudio, “get_audio_backend”, _mock_get_audio_backend)
这样做可以:
- 欺骗依赖库:pyannote.audio 等库在 import 阶段会检查 torchaudio.backend.common 是否存在。如果不存在,程序直接崩溃。上面的代码在它们运行之前,先在内存里“画”了一个假的模块和类给它们看。
- 不会影响功能:WhisperX 的核心音频加载逻辑使用的是 ffmpeg 命令,完全不依赖 Torchaudio 的 backend。因此,我们在 Torchaudio 里造假并不会导致音频加载失败,反而绕过了无谓的检查。
- 新版 Torchaudio 虽然删了 API,但底层的 load() 功能还在。当它真正去读音频时,它调用 torchaudio.load()。虽然这个函数现在的实现变了,但参数签名没变。Pyannote 依然能成功读取到音频数据。
把上述的代码集合起来变成了我现在RTX 5070运行WhisperX的专属补丁。终于可以本地顺利跑通整条处理流水线:转录5min的音频文件用时大概在21s。
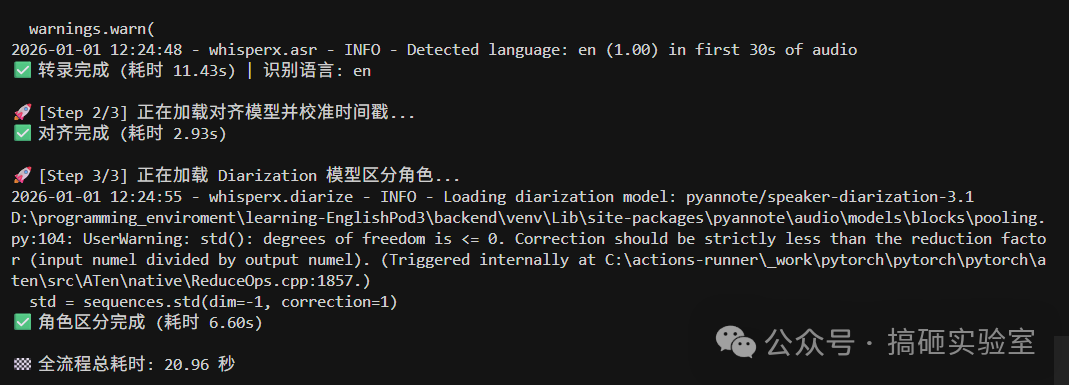
反思与替代方案
在我使用了大半天的时间在本地跑通WhisperX,并且把它对接在前端界面上后,我再返回去跟Gemini老师聊天。
我说:“这个要依据硬件打补丁也太不通用了,有没有什么办法能把这个代码写得更加通用一点?”
Gemini老师:“你说得对,我推荐另外一个字幕识别的开源项目给你,可以完美适配你显卡,不用自己去打补丁。”
我:“……那你为什么当初要推荐WhisperX?”
Gemini老师:“在词汇时间戳达到毫秒级别的精准上WhisperX还是很受人认可的。但是Faster-Whisper的large-v3模型现在的原生时间戳精度已经足够好,虽然没到‘毫秒级完美’,但对于‘区分说话人’这个任务来说,误差完全在可接受范围内。”
仔细想一下,这个踩坑的点在于我对AI模型本地运行的逻辑不是很了解,因此根本就意识不到需要把我的硬件信息说出来。Gemini依据自己搜索到的信息推荐了一个各方评价还不错的项目,没想到跟我的显卡不适配。在不适配的情况下,我没有问还“有没有更好的选项”,而是直接下达了“debug”的指令,才绕了这么一大圈,这是我在一开始的技术栈就没有选好。
这个故事告诉我们:
- 开源项目的时间比较重要,现在AI相关的东西变化太快了,如果你在尝试一些旧的开源项目容易踩坑。
- 如果要咨询本地部署AI的方案,记得告诉AI老师你的硬件是什么,这是一个比较重要的约束条件。
- 技术选型时,多问一句“有没有更适合我当前环境的替代方案?”可能省下大量时间。
下面附上几个 Whisper 系列开源项目的对比表格,希望能帮助大家选到适合自己的模型:

如果你也遇到了类似的硬件兼容性问题,或者在技术选型上有更多心得,欢迎来云栈社区交流讨论。
 发表于 2026-1-3 06:06:00
|
查看: 271|
回复: 0
发表于 2026-1-3 06:06:00
|
查看: 271|
回复: 0
