性能是构建大型、稳定系统的基石。当CPU使用率达到100%时,系统真的就立刻崩溃了吗?这背后其实有一套完整的设计哲学与工程技术在支撑。
这里有一个常见的误解需要澄清:CPU使用率100%仅仅意味着计算资源已被充分利用,并不等同于系统宕机。
从操作系统内核的角度看,只要内核还能正常调度并分配时间片,系统就仍在运行。对于应用程序而言,100%的CPU使用率通常表现为请求处理速度变慢、请求开始排队。但只要应用的处理速度仍然高于新请求涌入的速度,服务就依然可用,并不会立即“挂掉”。

真正导致服务崩溃的元凶,往往是其他因素:
- 内存溢出(OOM):持续的高负载导致请求堆积,内存被逐渐耗尽,最终触发系统强制终止进程。
- 雪崩效应:上游服务因超时而不断重试,将数倍于正常流量的压力传递给下游,导致依赖链上的服务连环崩溃。
那么,大型互联网公司是如何构建韧性,从容应对此类挑战的呢?
1. 微服务与拆分化架构
将庞杂的单体应用拆分为多个职责单一的独立服务。这种架构的核心优势在于隔离性:即使某个具体服务进程或节点发生过载,其影响也被限制在局部,不会直接导致整个系统不可用。结合负载均衡与服务发现机制,流量可以被动态地引导至健康的服务实例,从而有效平滑局部CPU峰值压力。这种对系统边界的清晰划分和治理,是构建高可用架构的第一步。
2. 容量预留与弹性伸缩
这是应对流量波动的核心自动化手段。通过容器化技术与自动伸缩策略,系统能够实时感知负载变化。当监控到某些实例的CPU利用率长时间处于高位时,自动化流程会快速拉起新的实例以分担流量,实现横向扩容。同时,利用cgroups、容器资源限制等机制进行资源隔离,并配合服务质量等级策略,确保核心业务始终能获得必要的计算资源,优先得到调度,从而显著降低因资源争抢导致的“雪崩”风险。
3. 异步化与降级策略
为了降低核心链路的峰值压力,大厂普遍将非关键路径的业务逻辑改为异步处理。例如,通过消息队列解耦耗时操作,或者将任务流水线化。同时,设计合理的超时、重试与熔断机制。当后端服务压力过大时,系统会果断启用功能降级策略,例如直接返回缓存数据或静态兜底内容,并配合严格的限流措施。其设计目标是,在极端情况下优先保障核心服务的可用性,而非功能的完整性。
4. 智能调度与可观测体系
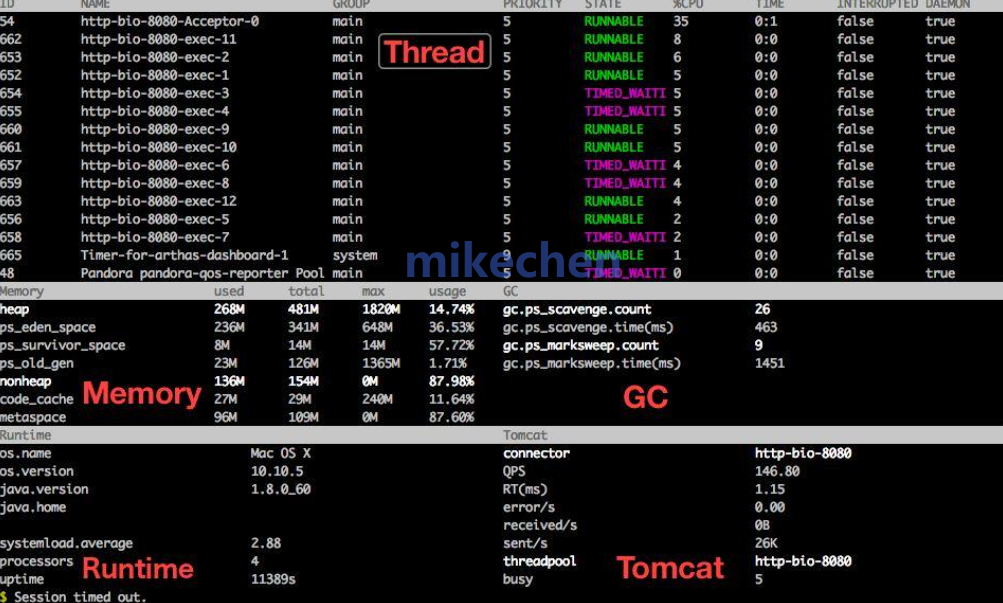
强大的实时响应能力依赖于完善的监控、告警与分布式链路追踪系统。当CPU出现异常指标时,这套体系能帮助工程师迅速定位瓶颈所在,究竟是代码热点、慢查询还是资源竞争。结合智能调度器与运维自动化平台,可以在问题扩散之前执行流量切换、实例替换或预案调整。此外,定期的性能剖析与全链路压测,有助于在业务高峰来临前提前发现并优化潜在的性能瓶颈。
从架构隔离到弹性伸缩,从异步削峰到立体监控,这一系列措施共同构成了现代高并发系统应对资源极限挑战的防线。理解这些设计思路,对于开发和维护稳定可靠的在线服务至关重要。如果你想深入探讨更多系统设计或运维保障的实战经验,欢迎在云栈社区与其他开发者交流分享。 |  发表于 2026-1-3 09:21:45
|
查看: 245|
回复: 0
发表于 2026-1-3 09:21:45
|
查看: 245|
回复: 0
