前言: 从时间片到完全公平
在 CFS(Completely Fair Scheduler,完全公平调度器)出现之前,Linux 使用的是 O(n) 和 O(1) 调度器。这些调度器基于固定的时间片(time slice)和优先级,就像给每个进程分配固定长度的“发言时间”。但这种方式存在明显问题:
- 交互式进程响应慢:即使高优先级的交互进程,也要等低优先级进程用完时间片。
- 不公平现象:CPU 密集型进程可能占用过多时间。
- 参数调整复杂:需要手动调整 nice 值、时间片长度等参数。
2007 年,Ingo Molnár 提出了 CFS,它彻底改变了调度哲学:不再分配固定的时间片,而是追求每个进程获得公平的 CPU 时间比例。
第一部分: CFS 的核心设计思想
1.1 公平性的数学建模
CFS 的核心思想可以用一个简单的比喻理解:
想象一场马拉松比赛,但不是比谁先到终点,而是确保每个选手跑步的时间比例相同。
在实际比赛中:
- 每个选手都有自己的“虚拟时间”(virtual runtime)
- 跑得快的选手(优先级高)虚拟时间走得慢
- 跑得慢的选手(优先级低)虚拟时间走得快
- 调度器总是选择虚拟时间最少的选手上场比赛
这种设计确保:在任意时间段内,每个进程获得的 CPU 时间与其权重成正比。
1.2 CFS 的四个基本原则
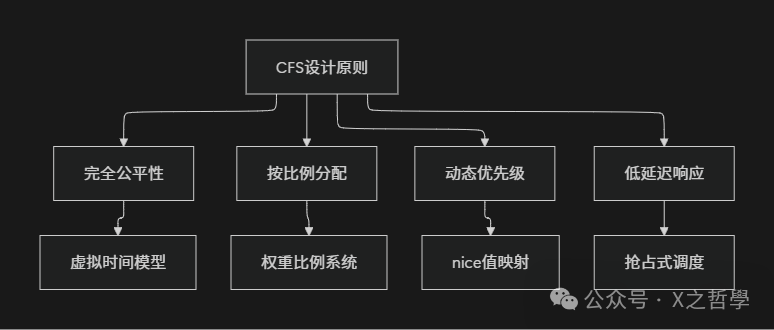
表1: CFS 与传统调度器的对比
| 特性维度 |
传统 O(1) 调度器 |
CFS 调度器 |
| 调度单位 |
固定时间片 |
虚拟时间差 |
| 公平性 |
基于优先级的时间片轮转 |
按权重比例的完全公平 |
| 复杂度 |
O(1) |
O(log N)(红黑树操作) |
| 交互性 |
需要启发式算法识别 |
自然获得良好响应 |
| 参数调整 |
需要调整多个参数 |
主要调整 nice 值 |
第二部分: 核心概念深入解析
2.1 虚拟时间(vruntime):公平的度量衡
虚拟时间是 CFS 最核心的概念。每个进程维护一个 vruntime,表示该进程在 CPU 上运行的“虚拟时间量”。
计算公式如下:
vruntime = 实际运行时间 * (NICE_0_LOAD / 进程权重)
其中:
- 实际运行时间:进程在 CPU 上执行的真实时间(纳秒)
- NICE_0_LOAD:nice 值为 0 的进程的权重(默认 1024)
- 进程权重:根据进程的 nice 值计算得出
举个例子:
假设有两个进程 A 和 B:
- A 的权重是 1024(nice=0)
- B 的权重是 820(nice=1)
- 如果都运行了 10ms 实际时间
那么:
- A 的 vruntime 增加:10ms × (1024/1024) = 10ms
- B 的 vruntime 增加:10ms × (1024/820) ≈ 12.5ms
CFS 总是选择 vruntime 最小的进程运行,这样 B 虽然这次运行增加了更多虚拟时间,但下次会更早被调度,长期来看两者获得的 CPU 时间比例是 1024:820。
2.2 权重系统:从 nice 值到 CPU 比例
Linux 使用 nice 值(-20 到 19)表示进程优先级。CFS 将 nice 值映射为权重,这是操作系统调度策略的关键转换。
// kernel/sched/core.c 中的权重转换表
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
权重与 CPU 比例的关系:
如果一个进程的权重是 w_i,所有可运行进程的权重和是 W,那么该进程应获得的 CPU 时间比例为:
CPU比例 = w_i / W
表2: nice 值、权重与 CPU 比例变化
| nice 值 |
权重 |
相对 CPU 比例 |
实际解释 |
| -20 |
88761 |
~1000% |
最高优先级,获得最多 CPU |
| 0 |
1024 |
100% |
标准优先级 |
| +10 |
110 |
~10.7% |
低优先级,CPU 较少 |
| +19 |
15 |
~1.5% |
最低优先级,CPU 最少 |
有趣的现象:nice 值每增加 1,CPU 比例下降约 10%(不是线性!)。
2.3 调度延迟与最小粒度
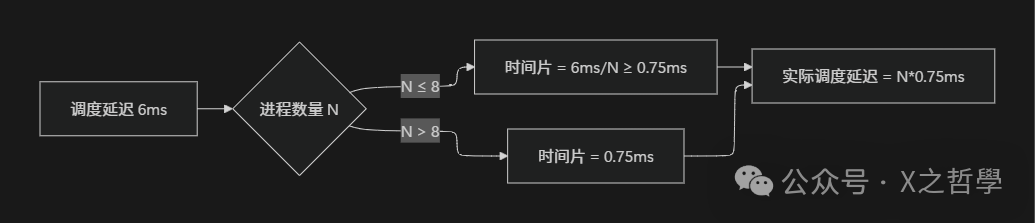
虽然 CFS 追求完全公平,但为了避免过度频繁的上下文切换(context switch),CFS 引入了两个重要参数:
- 调度延迟(sched_latency):保证每个可运行进程至少运行一次的时间周期。
- 默认值:6ms(可通过
/proc/sys/kernel/sched_latency_ns 调整)
- 计算公式:
调度时间片 = 调度延迟 / 进程数量
- 最小粒度(min_granularity):每个进程最少运行的时间。
- 默认值:0.75ms(可通过
/proc/sys/kernel/sched_min_granularity_ns 调整)
- 防止进程数量过多时,时间片过小导致切换开销过大
举个例子:
- 系统中有 4 个进程
- 调度延迟 = 6ms
- 理论时间片 = 6ms / 4 = 1.5ms(大于最小粒度 0.75ms)
- 每个进程至少运行 1.5ms
第三部分: CFS 的数据结构与实现
3.1 核心数据结构
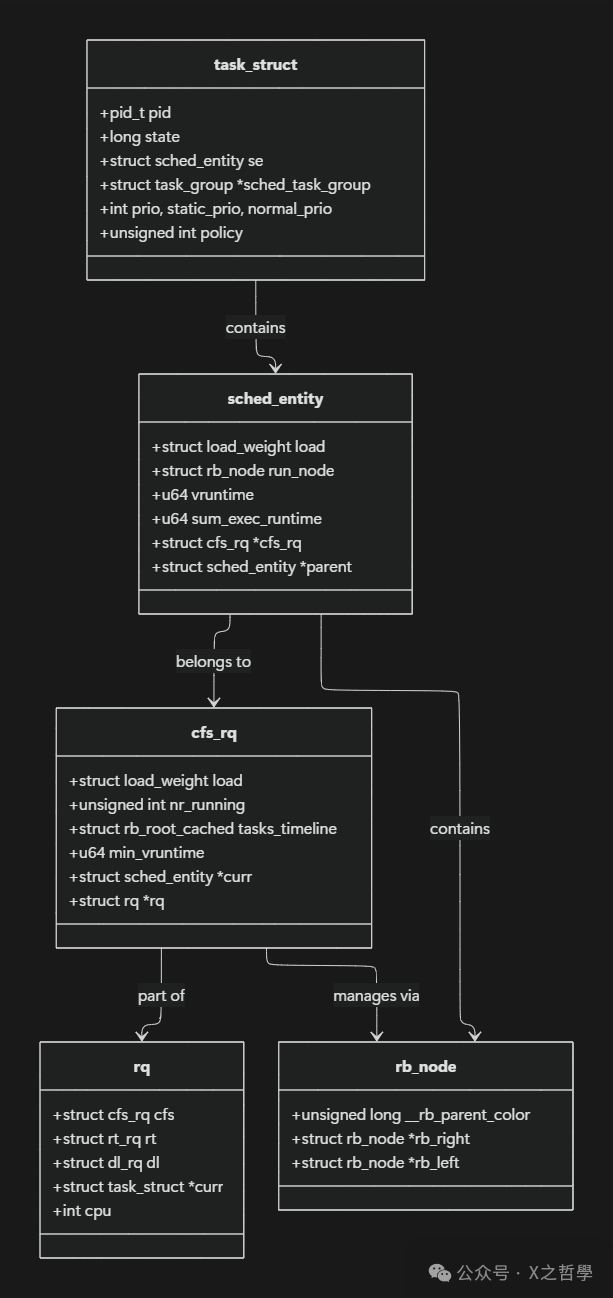
3.1.1 调度实体(sched_entity)
// include/linux/sched.h
struct sched_entity {
// 负载权重
struct load_weight load;
// 红黑树节点
struct rb_node run_node;
// 链表节点(用于组调度)
struct list_head group_node;
// 当前是否在运行队列上
unsigned int on_rq;
// 开始运行的时间
u64 exec_start;
// 累计运行时间
u64 sum_exec_runtime;
// 虚拟运行时间(核心!)
u64 vruntime;
// 上次运行的总和
u64 prev_sum_exec_runtime;
// 统计信息
u64 nr_migrations;
// 组调度相关
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent;
struct cfs_rq *cfs_rq;
struct cfs_rq *my_q;
#endif
};
3.1.2 CFS 运行队列(cfs_rq)
// kernel/sched/sched.h
struct cfs_rq {
// 负载权重总和
struct load_weight load;
// 可运行进程数
unsigned int nr_running;
// 红黑树根节点
struct rb_root_cached tasks_timeline;
// 当前运行进程
struct sched_entity *curr;
// 下一个要运行的进程
struct sched_entity *next;
// 最后运行的进程
struct sched_entity *last;
// 跳过运行的进程(负载均衡)
struct sched_entity *skip;
// 最小虚拟时间(红黑树最左节点)
u64 min_vruntime;
// 统计信息
u64 exec_clock;
// 组调度相关
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq;
struct task_group *tg;
#endif
};
3.2 数据结构关系图解
3.3 红黑树:高效选择下一个进程
CFS 使用红黑树(Red-Black Tree)来组织可运行进程,这是一种高效的数据结构,原因在于:
- 平衡性:红黑树是自平衡二叉树,保证操作复杂度 O(log N)。
- 快速查找:可以快速找到 vruntime 最小的进程(最左节点)。
- 高效插入/删除:进程唤醒或睡眠时需要快速更新。
红黑树组织方式:
- 键值:进程的 vruntime
- 最左节点:vruntime 最小的进程,下一个被调度
- 插入新进程:根据 vruntime 插入到合适位置
- 删除进程:进程睡眠或被迁移时删除
// kernel/sched/fair.c - 选择下一个进程
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
// 获取红黑树最左节点(vruntime最小)
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
if (!left || (curr && curr->vruntime < left->vruntime))
return curr;
// 检查是否应该跳过某些进程
se = left;
if (cfs_rq->skip && cfs_rq->skip == se) {
struct sched_entity *second = __pick_next_entity(se);
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
return se;
}
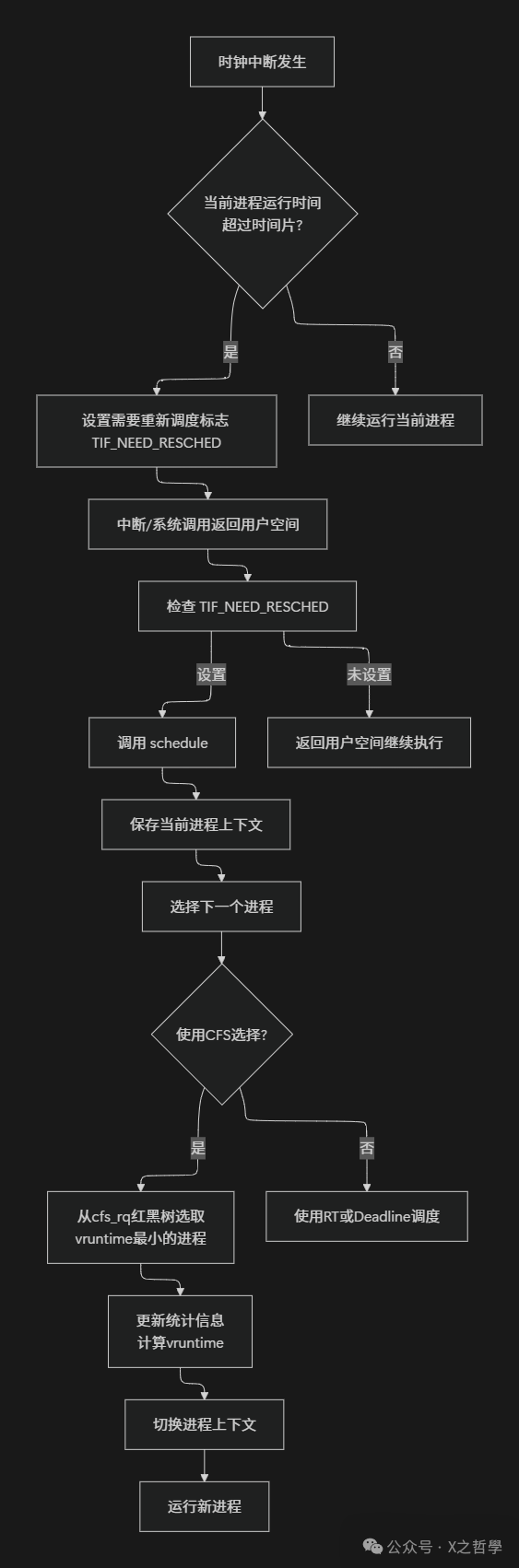
第四部分: CFS 调度算法流程
4.1 完整的调度周期
4.2 关键算法详解
4.2.1 vruntime 更新算法
// kernel/sched/fair.c - 更新当前进程的 vruntime
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (!curr)
return;
// 计算实际运行时间
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
// 更新开始时间
curr->exec_start = now;
// 累计实际运行时间
curr->sum_exec_runtime += delta_exec;
// 更新 vruntime(核心计算)
curr->vruntime += calc_delta_fair(delta_exec, curr);
// 更新 cfs_rq 的最小 vruntime
if (curr->vruntime < cfs_rq->min_vruntime)
cfs_rq->min_vruntime = curr->vruntime;
}
4.2.2 进程唤醒时的 vruntime 调整
当一个进程被唤醒时,不能直接使用原来的 vruntime,否则会不公平地获得过多 CPU 时间:
static void
place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;
if (initial) {
// 新创建的进程
vruntime += sched_vslice(cfs_rq, se);
} else {
// 唤醒的进程
u64 sleep_time = rq_clock_task(rq_of(cfs_rq)) - se->exec_start;
if (sleep_time > 0) {
// 补偿睡眠时间,但不能超过当前最小vruntime
vruntime -= calc_delta_fair(min(sleep_time, sysctl_sched_latency), se);
}
}
// 确保不会设置得太小
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
第五部分: 组调度(CFS Group Scheduling)
5.1 组调度的必要性
想象一个场景:用户 A 运行了 100 个进程,用户 B 只运行了 1 个进程。没有组调度时,B 的进程只能获得约 1% 的 CPU 时间,这显然不公平。
组调度将进程分组,在每个组内应用 CFS,在组间也应用 CFS,实现多层次公平。
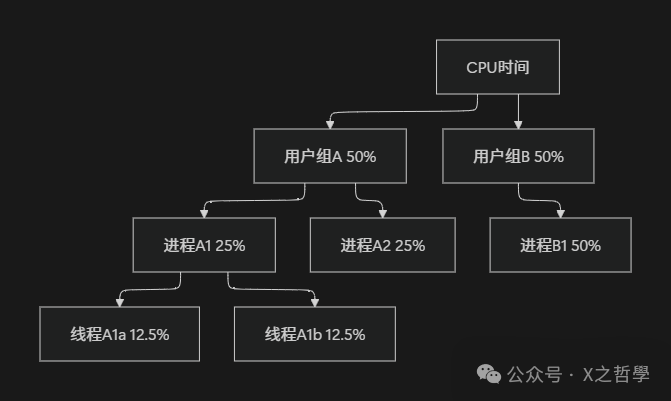
5.2 组调度的实现机制
// 组调度相关数据结构
struct task_group {
// CFS 组调度
struct cfs_bandwidth cfs_bandwidth;
// 每个 CPU 上的运行队列
struct cfs_rq **cfs_rq;
// 权重
struct sched_entity **se;
struct cfs_bandwidth cfs_bandwidth;
};
// 在更新 vruntime 时考虑组调度
static inline void
update_curr(struct cfs_rq *cfs_rq)
{
// ... 之前的代码 ...
#ifdef CONFIG_FAIR_GROUP_SCHED
// 更新父级调度实体
if (parent_cfs_rq(cfs_rq))
update_curr(parent_cfs_rq(cfs_rq));
#endif
}
组调度的关键点:
- 每个任务组都有自己的 CFS 运行队列。
- 组作为整体在父组中竞争 CPU 时间。
- 组内进程再按照普通 CFS 规则竞争组内时间。
第六部分: CFS 参数调优与监控
6.1 可调参数
表3: CFS 主要可调参数
| 参数文件 |
默认值 |
说明 |
影响 |
/proc/sys/kernel/sched_latency_ns |
6,000,000 ns |
调度延迟 |
影响进程切换频率 |
/proc/sys/kernel/sched_min_granularity_ns |
750,000 ns |
最小时间片 |
保证进程最小运行时间 |
/proc/sys/kernel/sched_wakeup_granularity_ns |
1,000,000 ns |
唤醒粒度 |
影响唤醒进程的抢占性 |
/proc/sys/kernel/sched_tunable_scaling |
1 (对数) |
参数缩放方式 |
根据CPU数量自动调整 |
/proc/sys/kernel/sched_child_runs_first |
1 |
子进程优先运行 |
fork后子进程先运行 |
/proc/sys/kernel/sched_nr_migrate |
32 |
负载均衡迁移数量 |
多核负载均衡 |
6.2 监控工具与命令
6.2.1 系统级监控
# 1. 查看运行队列信息
$ cat /proc/sched_debug
CFS运行队列信息:
cfs_rq[0]:/
.exec_clock = 125431423
.MIN_vruntime = 1244321
.min_vruntime = 1254321
.nr_running = 4
.load = 4096
# 2. 查看调度统计
$ cat /proc/schedstat
version 15
timestamp 4297293276
cpu0 0 0 0 0 0 0 1254321423...
# 3. 使用 perf 跟踪调度事件
$ perf sched record -- sleep 1
$ perf sched latency
6.2.2 进程级监控
# 1. 查看进程调度信息
$ cat /proc/<PID>/sched
se.exec_start : 1254321.123456
se.vruntime : 54321.654321
se.sum_exec_runtime : 123456.789012
nr_switches : 12345
nr_voluntary_switches : 12300
nr_involuntary_switches : 45
# 2. 使用 chrt 设置调度策略
$ chrt -f -p 10 <PID> # 设置 FIFO 调度,优先级 10
$ chrt -r -p 50 <PID> # 设置 RR 调度,优先级 50
$ chrt -b -p 0 <PID> # 设置 CFS 调度(默认)
# 3. 使用 taskset 控制 CPU 亲和性
$ taskset -p <PID> # 查看进程的 CPU 亲和性
$ taskset -pc 0,2 <PID> # 设置进程只能在 CPU 0 和 2 上运行
6.2.3 调试工具
# 1. ftrace 跟踪调度器
$ echo 1 > /sys/kernel/debug/tracing/events/sched/enable
$ cat /sys/kernel/debug/tracing/trace_pipe
# 2. 使用 latencytop 分析调度延迟
$ sudo latencytop
# 3. 使用 cyclictest 测试实时性
$ cyclictest -t5 -p 80 -n -i 10000 -l 10000
6.3 性能调优实例
场景:提高交互式应用程序的响应速度。
# 1. 提高进程的静态优先级(更低的nice值)
$ nice -n -10 my_interactive_app
# 2. 调整调度器参数(临时)
$ echo 3000000 > /proc/sys/kernel/sched_latency_ns
$ echo 500000 > /proc/sys/kernel/sched_min_granularity_ns
$ echo 500000 > /proc/sys/kernel/sched_wakeup_granularity_ns
# 3. 设置 CPU 亲和性,避免缓存失效
$ taskset -c 0-3 my_interactive_app
# 4. 使用 cgroups 限制竞争进程
$ cgcreate -g cpu:/interactive
$ echo "1000000" > /sys/fs/cgroup/cpu/interactive/cpu.cfs_period_us
$ echo "200000" > /sys/fs/cgroup/cpu/interactive/cpu.cfs_quota_us
$ cgexec -g cpu:interactive my_interactive_app
第七部分: CFS 的扩展与变种
7.1 SCHED_BATCH 和 SCHED_IDLE
除了默认的 SCHED_NORMAL,CFS 还支持两种特殊策略:
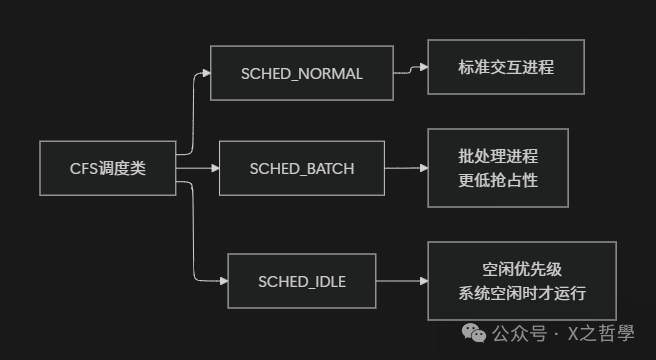
SCHED_BATCH:
- 针对非交互式批处理作业。
- 降低抢占频率,提高缓存利用率。
- 通过减少上下文切换提高吞吐量。
SCHED_IDLE:
- 优先级最低。
- 只在系统完全空闲时运行。
- 适合后台监控、统计任务。
7.2 CFS 带宽控制(CFS Bandwidth Control)
防止某个进程组独占 CPU:
# 设置 CPU 带宽限制
$ echo 100000 > /sys/fs/cgroup/cpu/mygroup/cpu.cfs_period_us # 周期 100ms
$ echo 20000 > /sys/fs/cgroup/cpu/mygroup/cpu.cfs_quota_us # 配额 20ms
# 结果:mygroup 最多使用 20% CPU
实现机制:使用令牌桶算法,每个周期分配一定配额,用完则节流。
第八部分: CFS 的局限与挑战
8.1 已知问题与解决方案
表4: CFS 的局限与应对策略
| 局限 |
表现 |
解决方案 |
| 缓存亲和性问题 |
频繁迁移导致缓存失效 |
唤醒亲和性、调度域 |
| NUMA 架构问题 |
远程内存访问延迟 |
NUMA 感知调度 |
| 实时性不足 |
不适合硬实时任务 |
与 RT 调度器共存 |
| 功耗优化冲突 |
公平性与省电矛盾 |
能效感知调度 |
| 超多核可扩展性 |
红黑树锁竞争 |
层级调度、无锁算法 |
8.2 CFS 与实时调度器的关系
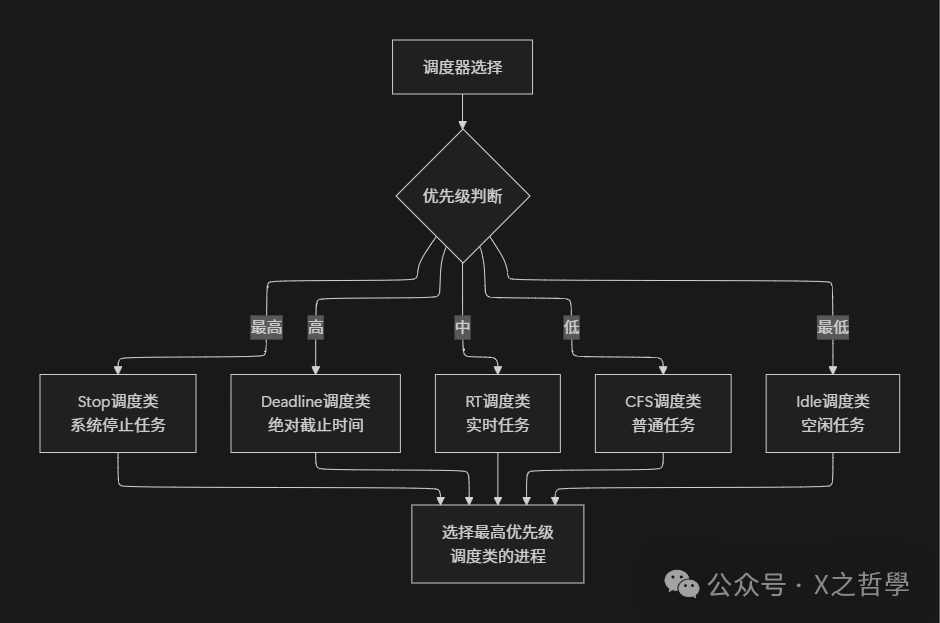
Linux 使用优先级层次结构,CFS 只是其中的一环。实时调度器(SCHED_FIFO、SCHED_RR)总是优先于 CFS 运行。
第九部分: 动手实验:实现简单的 CFS 模拟器
9.1 简化版 CFS 核心逻辑
#!/usr/bin/env python3
"""
简化版 CFS 模拟器
展示 vruntime 计算和进程选择
"""
import heapq
import time
class SimpleCFS:
def __init__(self, sched_latency=6.0):
self.rq = [] # 运行队列(最小堆)
self.min_vruntime = 0.0
self.sched_latency = sched_latency
# nice值到权重的简化映射
NICE_TO_WEIGHT = {
-20: 88761, -10: 9548, 0: 1024, 10: 110, 19: 15
}
def calc_delta_fair(self, delta_exec, weight):
"""计算虚拟时间增量"""
NICE_0_LOAD = 1024
return delta_exec * NICE_0_LOAD / weight
def enqueue_task(self, task):
"""进程入队"""
# 初始化 vruntime
if task.vruntime == 0:
task.vruntime = self.min_vruntime + self.sched_latency
heapq.heappush(self.rq, (task.vruntime, task))
def dequeue_task(self, task):
"""进程出队"""
self.rq = [(vr, t) for vr, t in self.rq if t != task]
heapq.heapify(self.rq)
def pick_next_task(self):
"""选择下一个运行进程"""
if not self.rq:
return None
return self.rq[0][1] # 返回 vruntime 最小的进程
def update_curr(self, task, exec_time):
"""更新当前进程的 vruntime"""
# 计算虚拟时间增量
delta_vruntime = self.calc_delta_fair(exec_time, task.weight)
task.vruntime += delta_vruntime
# 更新总运行时间
task.sum_exec_runtime += exec_time
# 更新最小 vruntime
if task.vruntime < self.min_vruntime:
self.min_vruntime = task.vruntime
# 重新入队(更新位置)
self.dequeue_task(task)
self.enqueue_task(task)
class Task:
def __init__(self, pid, nice=0):
self.pid = pid
self.nice = nice
self.weight = SimpleCFS.NICE_TO_WEIGHT.get(nice, 1024)
self.vruntime = 0.0
self.sum_exec_runtime = 0.0
def __lt__(self, other):
return self.vruntime < other.vruntime
# 模拟运行
if __name__ == "__main__":
cfs = SimpleCFS(sched_latency=6.0)
# 创建三个不同优先级的进程
tasks = [
Task(pid=1, nice=0), # 标准优先级
Task(pid=2, nice=-5), # 高优先级
Task(pid=3, nice=5), # 低优先级
]
# 所有进程入队
for task in tasks:
cfs.enqueue_task(task)
# 模拟调度 10 个周期
for cycle in range(10):
print(f"\n=== 调度周期 {cycle} ===")
# 选择下一个进程
next_task = cfs.pick_next_task()
print(f"选择进程 PID={next_task.pid}, vruntime={next_task.vruntime:.2f}")
# 模拟运行(运行时间与权重成反比)
exec_time = 1.0 * 1024 / next_task.weight
print(f"运行时间: {exec_time:.2f}ms")
# 更新进程状态
cfs.update_curr(next_task, exec_time)
# 显示所有进程状态
print("进程状态:")
for vruntime, task in sorted(cfs.rq):
print(f" PID={task.pid}: vruntime={vruntime:.2f}, "
f"总运行时间={task.sum_exec_runtime:.2f}")
9.2 运行结果分析
运行上述模拟器,你会看到:
- 高优先级进程(nice=-5)vruntime 增长较慢。
- CFS 总是选择 vruntime 最小的进程。
- 长期来看,CPU 时间按权重比例分配。
第十部分: 总结
10.1 CFS 的核心贡献
经过深入分析,我们可以看到 CFS 的设计体现了以下核心理念:
- 数学模型驱动:用 vruntime 精确量化公平性。
- 简单性:核心算法简洁优雅,易于理解和维护。
- 自适应性:自动适应不同负载和工作模式。
- 可扩展性:通过组调度支持复杂场景。
表5: CFS 调度器的核心优势总结
| 维度 |
传统调度器 |
CFS |
改进效果 |
| 公平性 |
基于优先级的时间片 |
按权重的比例公平 |
更精确的公平分配 |
| 交互性 |
需要启发式识别 |
自然获得良好响应 |
交互进程响应更快 |
| 吞吐量 |
固定时间片可能浪费 |
动态调整,减少切换 |
整体吞吐量提升 |
| 可配置性 |
多个复杂参数 |
主要调整 nice 值 |
用户接口更简单 |
| 代码维护 |
复杂启发式逻辑 |
简洁数学模型 |
更易维护和调试 |
10.2 CFS 的影响与启示
CFS 的成功不仅是技术上的,更是方法论上的:
- 从经验到科学:将调度问题转化为数学优化问题。
- 从复杂到简单:用简单模型替换复杂启发式规则。
- 从特殊到一般:统一处理各种类型的工作负载。
Linux CFS 调度器的设计深刻地展示了如何用优雅的数学模型解决复杂的系统工程问题,它的思想值得我们深入研究和借鉴。如果你想深入探讨更多关于系统底层原理或计算机基础的知识,欢迎访问云栈社区与其他开发者交流。
 发表于 2026-1-3 10:02:11
|
查看: 188|
回复: 0
发表于 2026-1-3 10:02:11
|
查看: 188|
回复: 0
