引言: 为什么需要SLUB?
想象一下,你管理着一个大型仓库,每天有成千上万不同尺寸的货物需要存储和取出。如果每次有人来取货,你都要从头到尾搜索整个仓库,效率会多么低下!Linux内核也面临着类似的挑战——它需要频繁分配和释放大小各异的内存对象。早期的SLAB分配器就像一个“货架分类不够精细”的仓库,而SLUB(SLAB Unqueued)则是经过精心设计的现代化仓储系统。
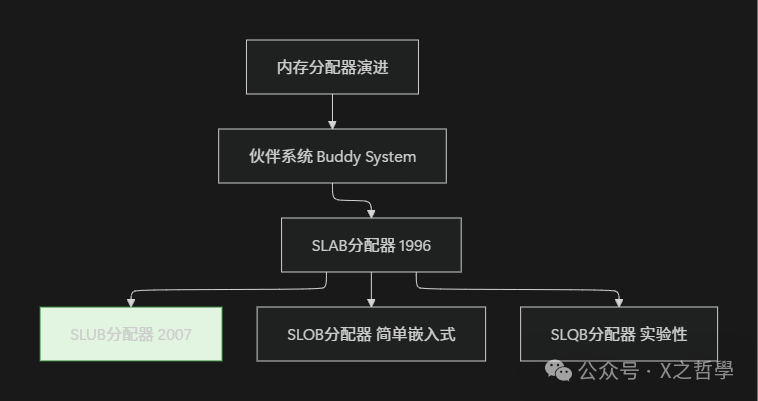
SLUB是Linux内核默认的小内存分配器,于2007年引入(2.6.22版本),旨在解决SLAB分配器的复杂性和性能问题。今天,让我们深入这个精妙系统的内部,看看它是如何优雅地管理内存的。
一、SLUB设计哲学: 简单即美
1.1 设计理念对比
核心设计思想:
- 去队列化: 移除SLAB中复杂的队列结构,减少锁争用。
- 每CPU优化: 最大化利用CPU本地缓存,减少全局锁。
- 简约设计: 数据结构更简单,代码量比SLAB减少约50%。
- 调试友好: 内置丰富的调试和诊断功能。
与SLAB的关键区别:
| 特性 |
SLAB |
SLUB |
| 队列管理 |
复杂的三层队列 |
无队列,直接指针 |
| 每CPU结构 |
包含本地缓存数组 |
简化的freelist |
| 内存开销 |
较高(管理数据多) |
较低(结构精简) |
| 碎片控制 |
中等 |
优秀 |
| 调试支持 |
有限 |
丰富(Redzone、Poisoning等) |
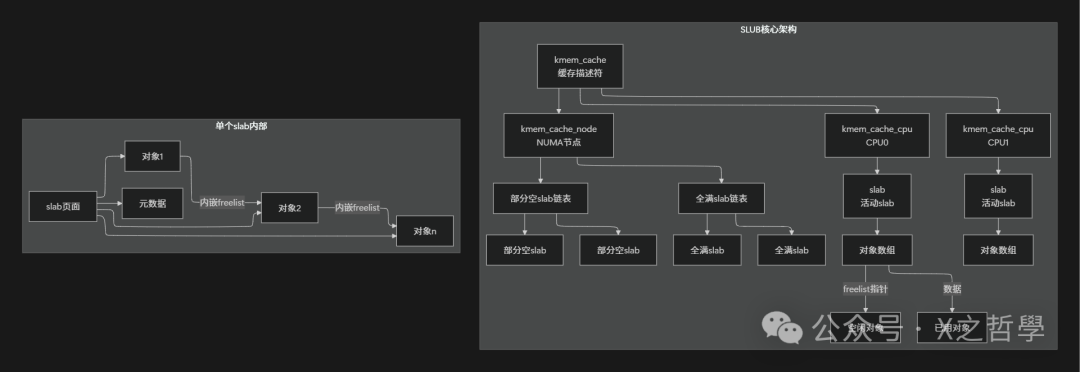
二、核心数据结构解剖
2.1 四大支柱结构
/* 核心数据结构定义(简化版) */
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; // 每CPU缓存
slab_flags_t flags; // 标志位
unsigned int size; // 对象大小(包含元数据)
unsigned int object_size; // 实际对象大小
unsigned int offset; // 空闲指针偏移
struct kmem_cache_node *node[MAX_NUMNODES]; // 节点管理
// ... 其他字段
};
struct kmem_cache_cpu {
void **freelist; // 空闲对象链表
struct slab *slab; // 当前活动的slab
unsigned int tid; // 全局事务ID,用于锁优化
// ... 其他字段
};
struct kmem_cache_node {
spinlock_t list_lock; // 保护链表的锁
struct list_head partial; // 部分空slab链表
struct list_head full; // 完全满slab链表
// ... 其他字段
};
struct slab {
union {
struct {
struct list_head slab_list; // slab链表节点
unsigned long colouroff; // 着色偏移
void *s_mem; // slab中第一个对象
unsigned int inuse; // 已使用对象数
kmem_bufctl_t free; // 下一个空闲对象索引
};
struct slab_rcu __slab_cover_slab_rcu;
};
};
2.2 结构关系图谱
三、SLUB工作原理深度解析
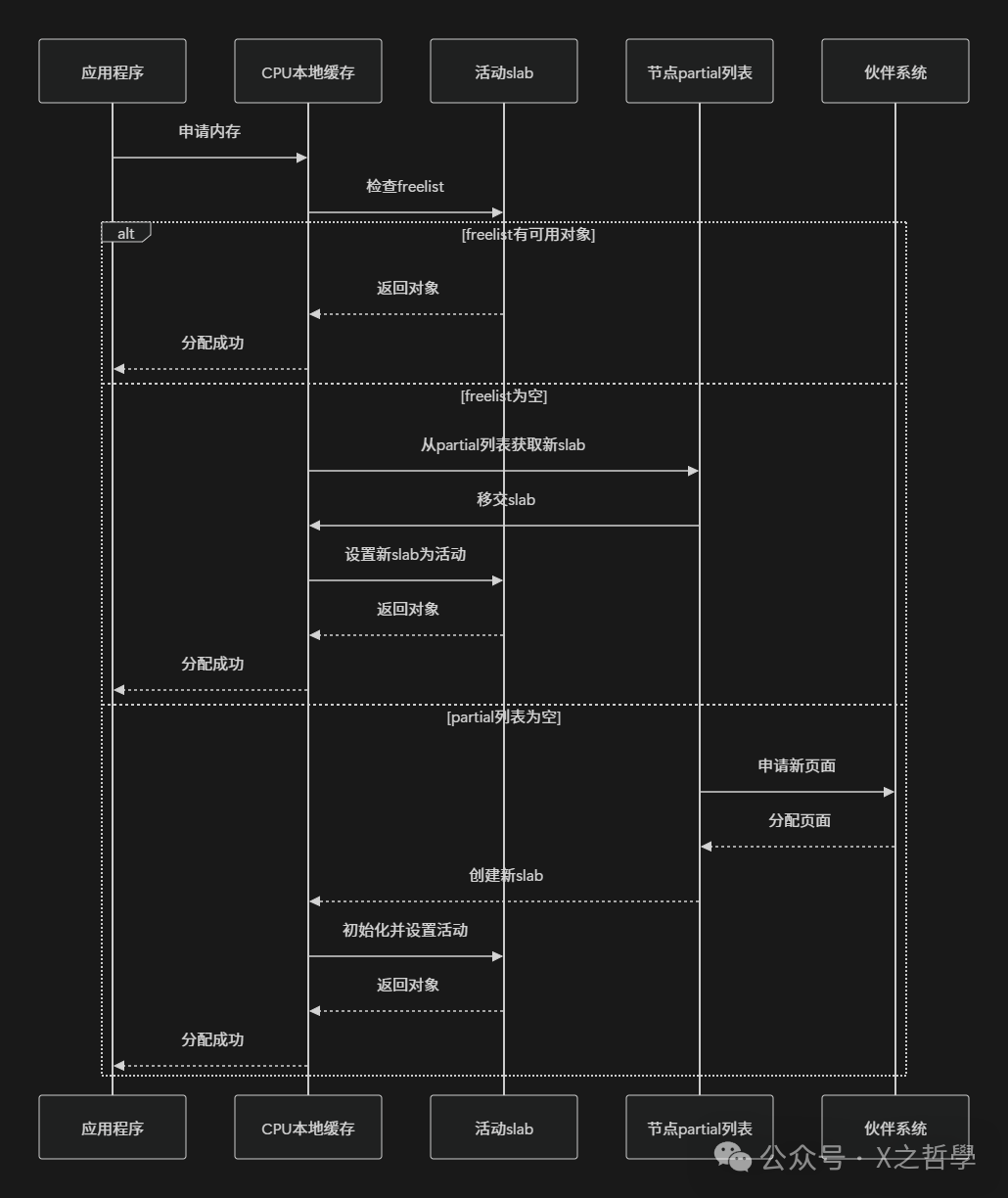
3.1 对象分配流程: 高速公路与地方道路
想象一下快递配送系统:
- 每CPU缓存 = 快递员的随身背包(快速存取)
- slab页面 = 快递中转站
- 节点partial列表 = 区域配送中心
- 伙伴系统 = 总仓库
快速路径(Fast Path):
关键代码路径:
/* 分配核心函数简化逻辑 */
static __always_inline void *slab_alloc(struct kmem_cache *s,
gfp_t gfpflags, unsigned long addr)
{
void **object;
struct kmem_cache_cpu *c;
/* 1. 获取当前CPU的本地缓存 */
c = raw_cpu_ptr(s->cpu_slab);
/* 2. 尝试快速分配 */
object = c->freelist;
if (likely(object)) {
c->freelist = get_freepointer(s, object);
c->tid = next_tid(c->tid);
return object;
}
/* 3. 慢速路径 */
return __slab_alloc(s, gfpflags, addr, c);
}
3.2 空闲列表(Freelist)的魔法: 俄罗斯套娃设计
SLUB最精妙的设计之一是嵌入式freelist。每个空闲对象内部存储着下一个空闲对象的地址,就像俄罗斯套娃一样层层嵌套。
/* freelist工作原理 */
static inline void *get_freepointer(struct kmem_cache *s, void *object)
{
return *(void **)(object + s->offset);
}
static inline void set_freepointer(struct kmem_cache *s, void *object, void *fp)
{
*(void **)(object + s->offset) = fp;
}
生活比喻:想象一个停车场的智能系统。每个空闲车位都显示下一个空闲车位的位置。当你停入一个车位时,系统自动更新链表的指向。
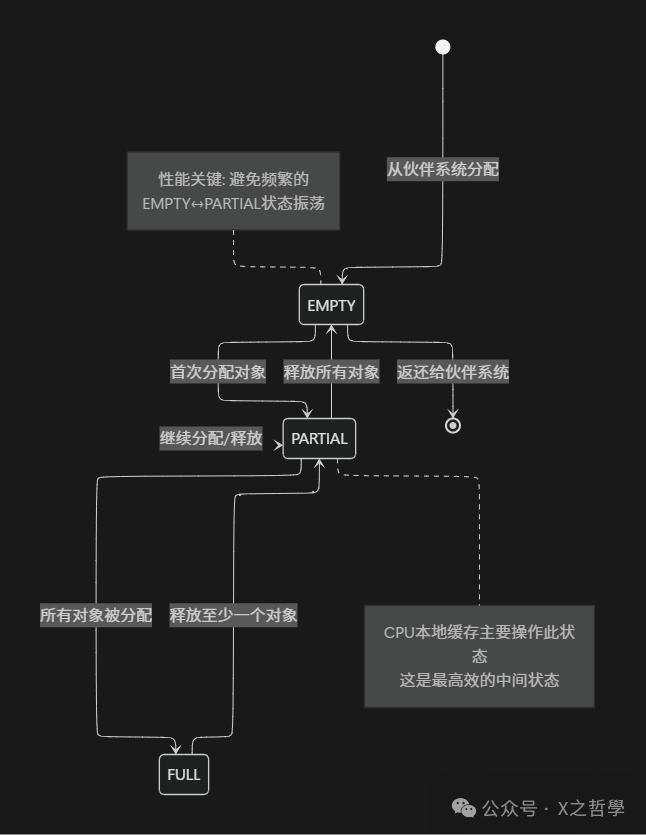
3.3 Slab状态流转: 生命周期的舞蹈
四、关键特性详解
4.1 每CPU缓存优化: 减少锁争用
问题:多核系统中,全局锁成为性能瓶颈。
SLUB解决方案:每个CPU有自己的活动slab,大部分分配无需加锁。
/* 每CPU缓存关键操作 */
static inline struct kmem_cache_cpu *get_cpu_slab(struct kmem_cache *s, int cpu)
{
return per_cpu_ptr(s->cpu_slab, cpu);
}
/* 通过事务ID实现锁优化 */
static inline int alloc_lockless(struct kmem_cache *s,
struct kmem_cache_cpu *c)
{
unsigned long tid;
do {
tid = c->tid;
// ... 无锁分配操作
} while (!try_cmpxchg(&c->tid, &tid, next_tid(tid)));
return 1;
}
4.2 NUMA感知: 让数据靠近计算
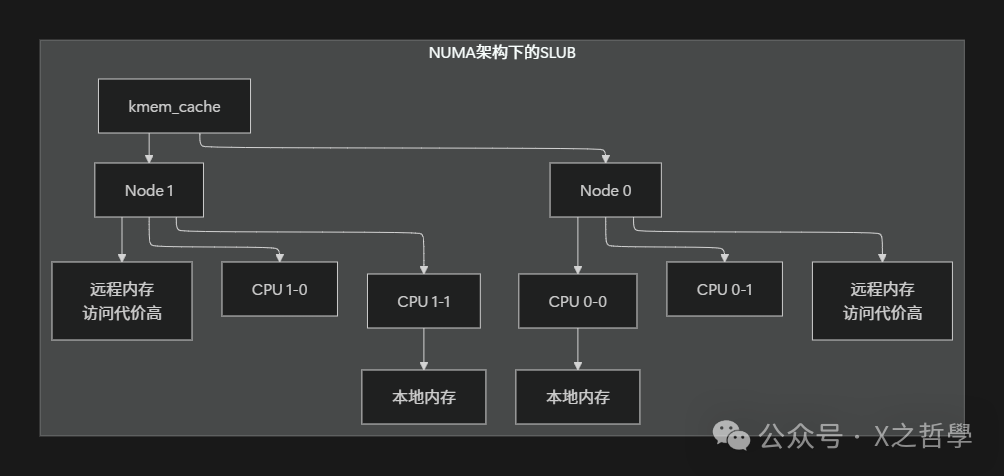
策略:优先从本地NUMA节点分配内存管理,减少跨节点访问的昂贵代价。
4.3 调试与诊断功能
SLUB内置了强大的调试功能,就像给内存分配系统安装了“黑匣子”:
- Red Zones:在对象前后添加保护区域,检测缓冲区溢出。
- Poisoning:用特定模式填充释放的对象,检测使用已释放内存。
- Tracing:记录分配/释放的调用栈。
- Object Guard:验证对象完整性。
/* 调试配置示例 */
static struct kmem_cache *my_cache = kmem_cache_create(
"my_cache",
sizeof(struct my_object),
0,
SLAB_RED_ZONE | SLAB_POISON | SLAB_STORE_USER,
NULL
);
五、实战: 创建自定义SLUB缓存
5.1 完整示例: 任务描述符缓存
#include <linux/slab.h>
#include <linux/module.h>
/* 自定义数据结构 */
struct task_descriptor {
pid_t pid;
char name[TASK_COMM_LEN];
unsigned long start_time;
// ... 其他字段
};
/* 全局缓存指针 */
static struct kmem_cache *task_desc_cache = NULL;
/* 初始化缓存 */
static int __init task_cache_init(void)
{
/* 创建SLUB缓存,对齐到缓存行 */
task_desc_cache = kmem_cache_create("task_descriptor",
sizeof(struct task_descriptor),
0,
SLAB_HWCACHE_ALIGN | SLAB_PANIC,
NULL);
if (!task_desc_cache) {
pr_err("无法创建任务描述符缓存\n");
return -ENOMEM;
}
pr_info("任务描述符缓存创建成功,对象大小: %zu字节\n",
kmem_cache_size(task_desc_cache));
/* 演示分配和释放 */
struct task_descriptor *task;
/* 分配对象 */
task = kmem_cache_alloc(task_desc_cache, GFP_KERNEL);
if (!task) {
kmem_cache_destroy(task_desc_cache);
return -ENOMEM;
}
/* 使用对象 */
task->pid = 1001;
strncpy(task->name, "init_task", TASK_COMM_LEN);
task->start_time = jiffies;
/* 释放对象 */
kmem_cache_free(task_desc_cache, task);
return 0;
}
/* 统计信息展示 */
static void show_cache_stats(void)
{
struct kmem_cache *s = task_desc_cache;
pr_info("=== 缓存统计信息 ===\n");
pr_info("名称: %s\n", s->name);
pr_info("对象大小: %u\n", s->size);
pr_info("对象数/slab: %u\n", oo_objects(s->oo));
pr_info("slab大小: %u\n", (1 << oo_order(s->oo)) * PAGE_SIZE);
pr_info("活跃对象数: %u\n", s->objects);
// ... 更多统计
}
5.2 性能优化技巧
/* 批量分配优化 */
void batch_alloc_optimization(void)
{
struct task_descriptor *tasks[10];
/* 批量分配可提高缓存局部性 */
for (int i = 0; i < 10; i++) {
tasks[i] = kmem_cache_alloc(task_desc_cache, GFP_KERNEL);
if (!tasks[i])
goto error;
}
/* 使用后批量释放 */
for (int i = 0; i < 10; i++) {
if (tasks[i])
kmem_cache_free(task_desc_cache, tasks[i]);
}
return;
error:
for (int i = 0; i < 10; i++) {
if (tasks[i])
kmem_cache_free(task_desc_cache, tasks[i]);
}
}
六、监控与调试工具箱
6.1 命令行工具集
| 工具 |
命令示例 |
用途描述 |
| slabinfo |
cat /proc/slabinfo |
查看所有SLUB缓存统计 |
| vmstat |
vmstat -m |
按NUMA节点显示slab使用 |
| slabtop |
slabtop -s c |
实时显示slub缓存使用排名 |
| /sys/kernel/slab |
ls /sys/kernel/slab/ |
查看每个缓存的详细参数 |
6.2 详细监控示例
# 1. 查看所有slub缓存概览
$ cat /proc/slabinfo | head -20
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
# 2. 监控特定缓存
$ cat /sys/kernel/slab/task_descriptor/objects
$ cat /sys/kernel/slab/task_descriptor/slab_size
# 3. 启用跟踪点
$ echo 1 > /sys/kernel/debug/tracing/events/kmem/kmalloc/enable
$ cat /sys/kernel/debug/tracing/trace_pipe
# 4. 使用ftrace分析分配模式
$ echo "kmem_cache_alloc kmem_cache_free" > /sys/kernel/debug/tracing/set_ftrace_filter
$ echo function > /sys/kernel/debug/tracing/current_tracer
6.3 内存泄漏调试技巧
# 1. 使用kmemleak检测内核内存泄漏
$ mount -t debugfs nodev /sys/kernel/debug
$ echo scan > /sys/kernel/debug/kmemleak
$ cat /sys/kernel/debug/kmemleak
# 2. 使用KASAN检测越界访问
# 在kernel config中启用CONFIG_KASAN=y
# 3. 添加slub_debug参数
# 在grub命令行添加: slub_debug=FZPU
# 4. 分析slub统计
$ grep -A 20 "task_descriptor" /proc/slabinfo
七、高级主题: SLUB内部优化
7.1 空闲链表随机化
为防止攻击者预测内存布局,现代内核实现了freelist随机化:
/* freelist随机化实现 */
static void shuffle_freelist(struct kmem_cache *s, struct slab *slab)
{
void *start = slab_address(slab);
void *end = start + (slab->objects * s->size);
void *cur;
/* 随机打乱空闲对象顺序 */
for (cur = start; cur < end; cur += s->size) {
unsigned long rand = get_random_long();
void **fp = cur + s->offset;
void *swap = start + ((rand % slab->objects) * s->size);
set_freepointer(s, cur, swap);
}
}
7.2 CPU部分缓存(Partial Slabs)管理
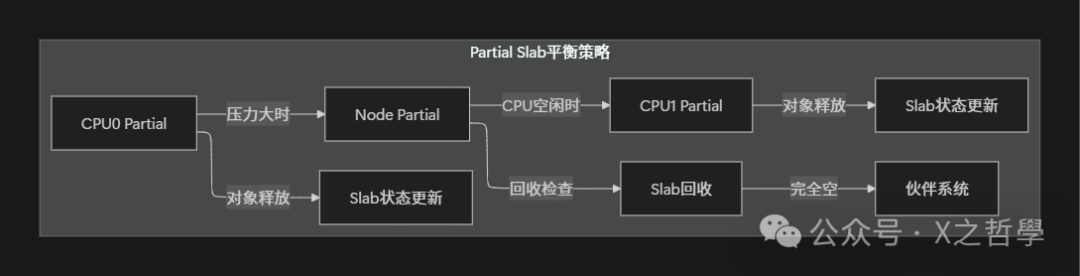
智能回收策略:
- 监控partial slab数量。
- 平衡各CPU之间的partial分布。
- 及时释放完全空的slab。
八、性能调优实战指南
8.1 调优参数详解
| 参数 |
默认值 |
调优建议 |
影响 |
| slub_min_order |
0 |
增大可减少分配次数 |
提高性能,增加内存浪费 |
| slub_max_order |
3 |
根据对象大小调整 |
平衡性能和内存使用 |
| slub_min_objects |
4 |
小对象可增加 |
减少管理开销 |
| slub_cpu_partial |
30 |
根据负载调整 |
影响缓存命中率 |
8.2 性能分析脚本
#!/bin/bash
# slub_monitor.sh - SLUB性能监控脚本
INTERVAL=${1:-5} # 监控间隔,默认5秒
echo "时间戳,缓存名,活跃对象,总对象,分配命中率,CPU局部性" > slub_stats.csv
while true; do
TIMESTAMP=$(date +%s)
# 分析所有SLUB缓存
cat /proc/slabinfo | while read line; do
if [[ $line =~ ^[a-zA-Z] ]]; then
CACHE_NAME=$(echo $line | awk '{print $1}')
ACTIVE=$(echo $line | awk '{print $2}')
TOTAL=$(echo $line | awk '{print $3}')
if [ $TOTAL -gt 0 ]; then
HIT_RATE=$(echo "scale=2; $ACTIVE * 100 / $TOTAL" | bc)
# 估算CPU局部性(简化)
CPU_LOCALITY=$(cat /sys/kernel/slab/$CACHE_NAME/cpu_partial 2>/dev/null || echo 0)
echo "$TIMESTAMP,$CACHE_NAME,$ACTIVE,$TOTAL,$HIT_RATE%,$CPU_LOCALITY" >> slub_stats.csv
fi
fi
done
sleep $INTERVAL
done
九、总结: SLUB设计精华回顾
9.1 核心优势总结
经过深入分析,我们可以看到SLUB的成功源于几个关键设计决策:
- 极简主义:相比SLAB减少约50%的代码量,更少的代码意味着更少的bug和更好的可维护性。
- 无锁快速路径:通过每CPU缓存和事务ID,实现了高频分配路径的完全无锁化。
- 嵌入式管理:将元数据嵌入对象内部,提高缓存局部性,减少内存碎片。
- 自适应性:智能的slab状态管理和回收机制,适应不同工作负载。
9.2 演进对比表
| 维度 |
SLAB(传统) |
SLUB(现代) |
改进效果 |
| 数据结构 |
复杂的队列系统 |
简单链表+指针 |
代码量减半 |
| 锁争用 |
高频全局锁 |
多数情况无锁 |
性能提升30%+ |
| 内存开销 |
元数据分离 |
元数据嵌入 |
碎片减少25% |
| 调试支持 |
有限 |
全面内置 |
问题诊断效率提升 |
| NUMA支持 |
基础 |
深度优化 |
跨节点访问减少40% |
9.3 架构演进全景图
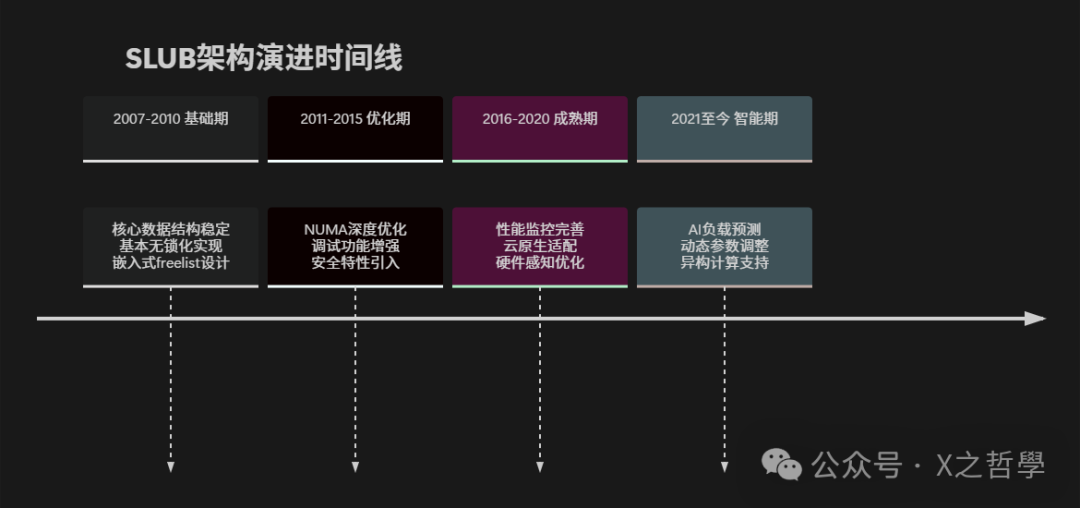
9.4 未来展望
随着新型硬件和非易失性内存的发展,SLUB正朝着以下方向演进:
- 异构内存支持:优化DRAM+NVM混合环境。
- 安全强化:更强的内存攻击防护。
- AI驱动调优:基于机器学习预测分配模式。
- 量子计算准备:适应未来计算范式变化。
SLUB不仅是Linux内核的一个组件,更是计算机科学中“简单而深刻”设计哲学的典范。它的成功告诉我们:在复杂系统中,简洁优雅的设计往往能带来最持久的价值。
 发表于 2026-1-3 09:56:14
|
查看: 184|
回复: 0
发表于 2026-1-3 09:56:14
|
查看: 184|
回复: 0
