在嵌入式开发中,如何清晰、高效地管理复杂的状态流转是一个常见挑战。此前我们介绍状态机框架时,提到 Zephyr 项目中的 SMF(State Machine Framework)可以被独立抽取使用。这引起了不少开发者的兴趣:如何将它从 Zephyr RTOS 中“抠”出来,用在裸机或其他非 Zephyr 项目中?本文将手把手带你完成这一过程,并实现一个具体的命令解析器实例。
1. Zephyr SMF 概述
Zephyr 状态机框架是一个与应用程序无关的框架,它让开发者可以轻松地将状态机集成到自己的应用中。其核心代码量极少,依赖简单,非常适合独立抽取移植到各种资源受限的嵌入式环境。
Zephyr SMF 的优势
- API 极简:核心函数仅需
smf_set_initial、smf_run_state、smf_set_state 三个。
- 零依赖:不依赖任何 RTOS 特性,由纯 C 标准实现。
- 资源占用小:代码段约 2KB,每个状态机实例的 RAM 占用通常小于 100 字节。
2. SMF 核心文件分析
2.1 只需三个文件
从 Zephyr 仓库中,我们只需要抽取以下三个核心文件:
zephyr_smf/
├── smf.h # 头文件(约220行)
├── smf.c # 实现文件(约430行)
└── smf_port.h # 移植适配层(需自行创建)
2.2 依赖关系与移植要点
SMF 的原始依赖非常克制,主要集中在 Zephyr 内核的日志和工具宏上。我们需要做的移植工作主要包括:
- 移除 Zephyr 日志系统:将
LOG_ERR 等宏替换为标准 printf 或你自己的日志函数。
- 处理配置宏:将
CONFIG_SMF_ANCESTOR_SUPPORT 等 Zephyr Kconfig 宏,替换为自定义宏或直接定义。
- 提供工具宏:实现或替换
<zephyr/sys/util.h> 中的少量工具宏,如 ARRAY_SIZE。
3. 实战:构建基于 SMF 的命令解析器
下面,我们将通过一个完整的工程实例,演示如何抽取并使用 Zephyr SMF,实现一个能够解析 CMD 或 CMD:PARAM 格式的文本命令解析器。
3.1 Zephyr SMF 抽取步骤
步骤1:创建项目目录结构
mkdir cmd_parser_demo && cd cmd_parser_demo
mkdir -p smf src
步骤2:复制 SMF 核心文件
从你的 Zephyr 源码仓库中复制文件(请将 $ZEPHYR_BASE 替换为你的实际路径):
cp $ZEPHYR_BASE/lib/smf/smf.c smf/
cp $ZEPHYR_BASE/include/zephyr/smf.h smf/
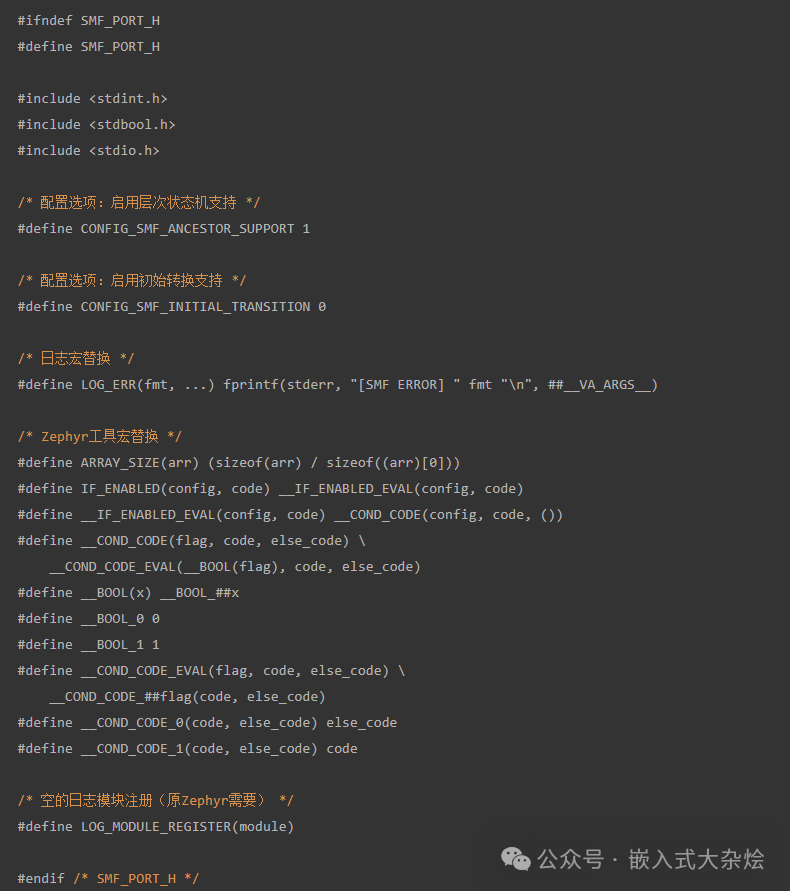
步骤3:创建移植适配层 smf_port.h
这是最关键的一步,用于抹平平台差异。你需要创建一个 smf/smf_port.h 文件。
步骤4:修改 SMF 源文件以适配新环境
编辑 smf/smf.c,在文件开头修改 include 路径:
#include “smf_port.h“ // 添加这一行,提供宏定义
#include “smf.h“ // 原有的include改为相对路径
// 删除或注释掉原始的Zephyr路径:#include <zephyr/smf.h>
// 删除或注释掉:#include <zephyr/logging/log.h>
编辑 smf/smf.h,移除 Zephyr 特定的头文件,并包含我们的移植层:
// 删除:#include <zephyr/sys/util.h>
// 删除:#include <zephyr/kernel.h>
#include “smf_port.h“ // 添加这一行
至此,Zephyr SMF 的抽取和移植工作就完成了。这个轻量级的开源项目 Zephyr 的状态机框架现在可以独立运行于你的项目中。
3.2 定义状态机上下文与流程
接下来,我们利用已移植的 SMF 来实现命令解析器。首先定义上下文结构体 parser_ctx_t。

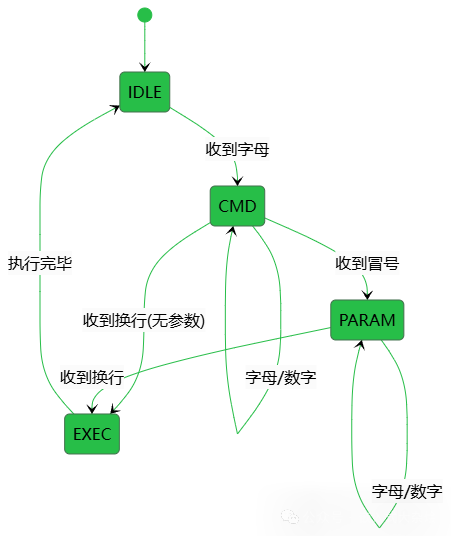
状态机工作流程分析
以解析命令 GET:temp\n 为例,状态机将按以下流程工作:
- IDLE状态 → 收到
G → 进入 CMD 状态,开始收集命令。
- CMD状态 → 收到
E、T → 继续收集命令字符。
- CMD状态 → 收到
: → 进入 PARAM 状态,开始收集参数。
- PARAM状态 → 收到
t、e、m、p → 继续收集参数字符。
- PARAM状态 → 收到
\n → 进入 EXEC 状态。
- EXEC状态 → 执行命令 → 返回 IDLE 状态,等待下一条命令。
3.3 实现状态机逻辑
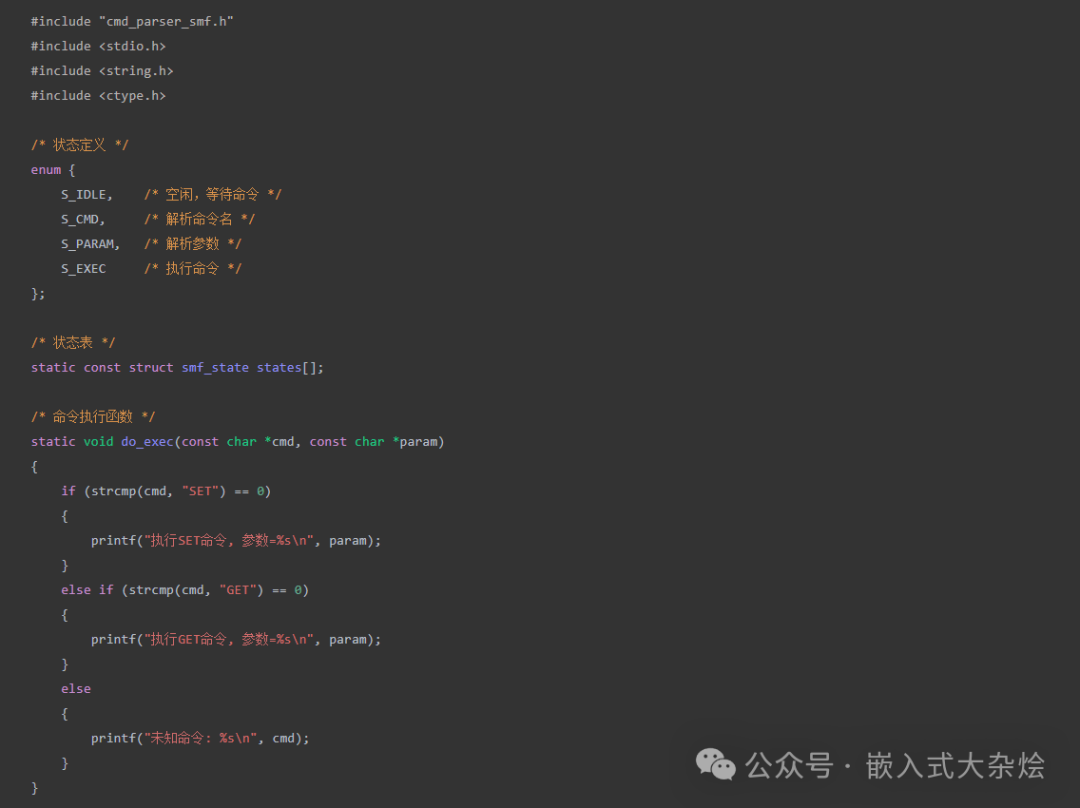
创建 src/cmd_parser_smf.c 文件,实现各个状态的具体行为。状态机框架设计的关键在于为每个状态定义入口(entry)、运行(run)和退出(exit)动作。
首先定义状态枚举和命令执行函数:
然后实现各个状态的处理函数。IDLE 状态负责初始化并等待命令起始字符:
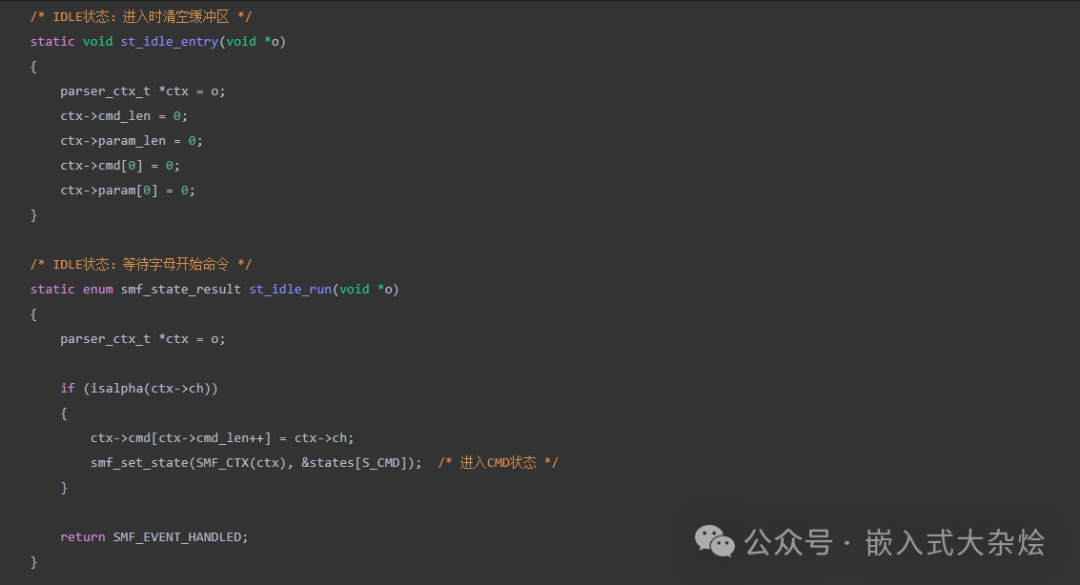
CMD 状态负责解析命令名,并处理冒号、换行等结束符:
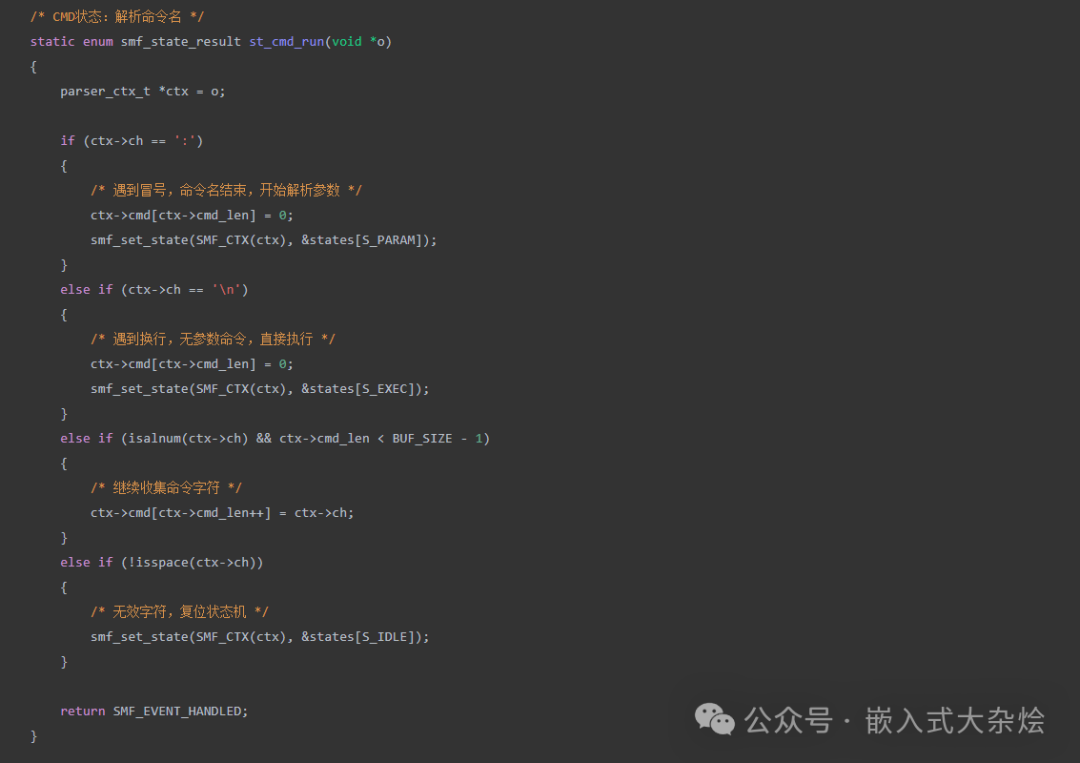
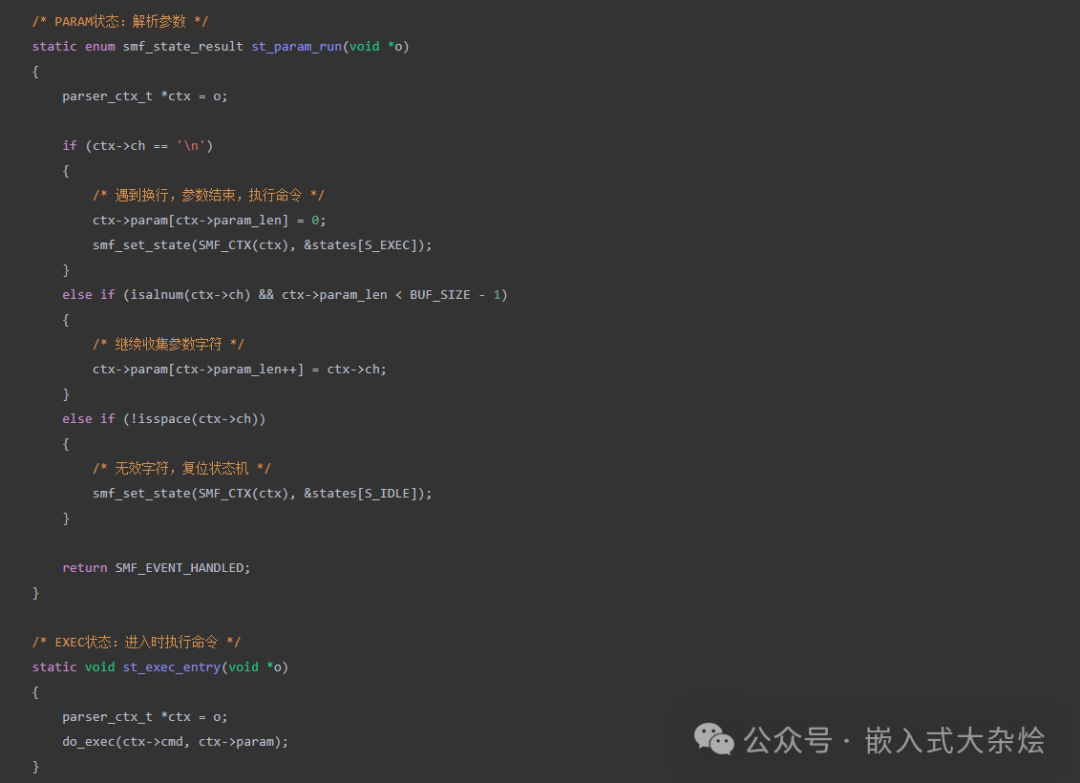
PARAM 状态负责收集参数,EXEC 状态则执行具体的命令逻辑:
最后,将所有的状态组织成状态表,并实现状态机的初始化和驱动函数:
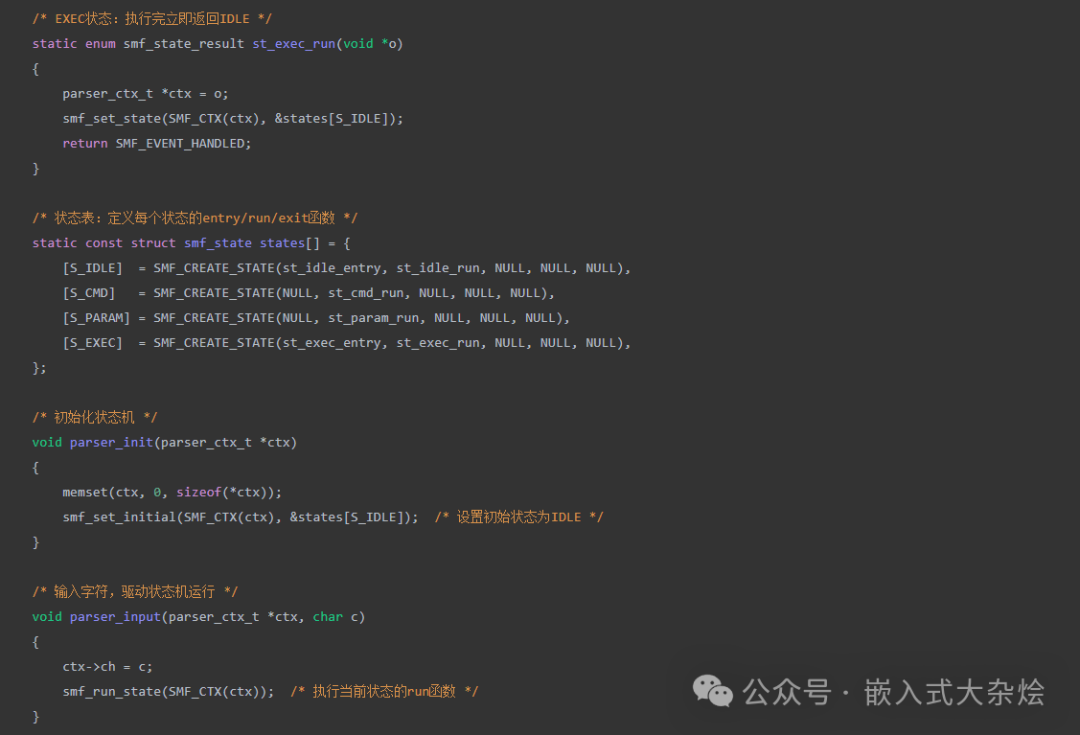
核心要点:
- 状态定义:使用
SMF_CREATE_STATE 宏清晰地定义每个状态的 entry/run/exit 函数。
- 状态转换:在 run 函数中,通过
smf_set_state() 函数来触发状态切换。
- 事件驱动:外部通过
parser_input() 输入字符事件,内部调用 smf_run_state() 来驱动当前状态处理事件。
3.4 编写测试程序
创建 src/main.c 文件,用于测试我们实现的状态机解析器。

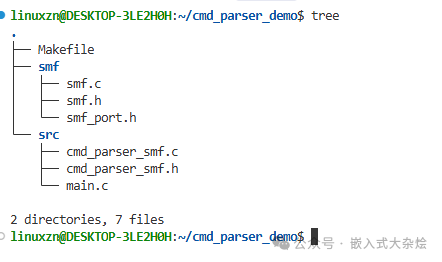
完成以上步骤后,你的项目目录结构应如下所示:
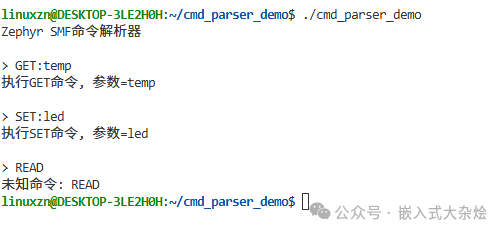
编译并运行程序,可以看到状态机正确地解析了不同的命令格式:
总结
通过本文的实战演练,我们可以看到,将 Zephyr SMF 从 RTOS 中抽取出来并应用到独立项目中,过程比想象中更为简单。其价值在于,它为我们提供了一种标准化的状态机框架实现,相比手动编写 switch-case 或函数指针表的状态机,SMF 带来了显著优势:
- 结构清晰:状态定义、转换规则一目了然,大幅提升了代码的可读性与可维护性。
- 易于扩展:新增状态只需在状态数组中添加一项,并实现对应的处理函数,符合开闭原则。
- 利于调试:状态切换有明确的函数调用栈,便于跟踪状态流转路径和定位问题。
Q&A
Q1:抽取出来的 SMF 可以用于商业项目吗?有 License 限制吗?
可以。Zephyr SMF 采用 Apache-2.0 开源许可证,这是一个非常宽松的协议。它允许商业使用、修改和分发,且不要求你开源自己的应用程序代码,你只需要在分发时保留原始的版权声明和许可证文本即可。
希望这篇从理论到实践的文章,能帮助你掌握这个轻量高效的状态机框架,并成功将其应用到你的下一个嵌入式项目中。如果你对更多底层技术实现和框架设计感兴趣,欢迎到 云栈社区 的 后端 & 架构 板块,与更多开发者交流探讨。
 发表于 2026-1-3 11:33:39
|
查看: 458|
回复: 0
发表于 2026-1-3 11:33:39
|
查看: 458|
回复: 0
