智能增长的瓶颈
回顾大模型爆发的三年多,AGI、算力、推理、Scaling 撞墙等关键词交织,构成了行业发展的主旋律。近日,潞晨科技创始人尤洋对智能增长进行了深度复盘,指出了当前的核心瓶颈与未来路径。

智能的现状
究竟什么是智能?目前业界并无明确定义。从图灵奖得主 Yann LeCun 与诺贝尔奖得主 Demis Hassabis 近期关于 AGI 的公开争论便能看出,即便顶尖专家也难以精准界定。
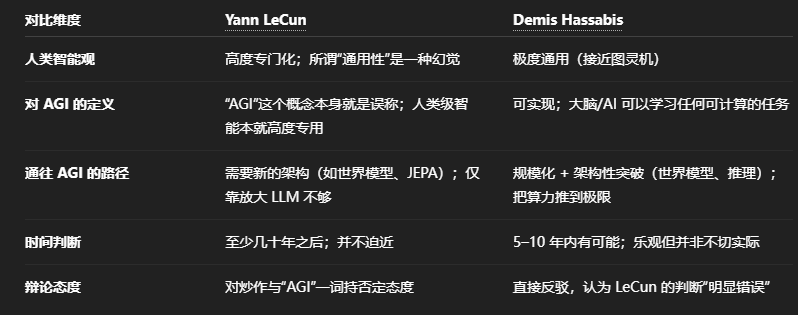
AGI 的标准本身是动态变化的。十几年前,人脸识别技术就足以让公众惊叹;若将今天的 ChatGPT 置于 2006 年,很多人或许会认为 AGI 已经实现。
笔者认为,智能的核心在于预测和创作能力。如果达成以下状态,我们便离 AGI 不远了:
- 在选择工作 Offer 时,完全听从 AI 的建议。
- 在购买足球彩票预测世界杯冠军时,完全采纳 AI 的意见。
- 遇到健康问题时,会完全采用 AI 制定的治疗方案。
- 无法分辨一部奥斯卡最佳电影是否由 AI 生成。
- 石油勘探团队用 AI 替代所有传统数值算法。
- AI 能指导初级工程师在 5 分钟内排除高铁疑难故障。
- AI 能研制出专杀癌细胞且不破坏健康细胞的药物。
- AI 能通过地下结构数据精准预测地震时间。
显然,我们尚未实现上述场景。未来能否突破,取决于能否克服智能发展的根本瓶颈。

智能发展的瓶颈
我们常听到智能增长遇阻、预训练红利耗尽的说法。要理解瓶颈,需先追溯智能从何而来。
过去十年,AI 大模型的技术本质是将电力能源通过计算过程转化为可复用的智能。技术优劣取决于转化效率。当前模型的智能主要源于预训练(尤其是自监督学习),微调或强化学习贡献相对有限。
为何如此?从经济账看:预训练消耗的算力与能源最为庞大。预训练、微调、强化学习本质上都是在计算梯度以更新参数。若有合适的海量数据与 Loss 函数,未来在预训练阶段融入监督微调(SFT)或特殊强化学习方法也未尝不可。
从智能增长视角,我们甚至无需严格区分这些阶段。它们的核心区别在于更新参数的规模与次数,计算本质都是通过梯度类似物来优化模型。
那么,能源从何而来?答案在于 GPU 与算力。英伟达的核心贡献在于其 GPU 设计路线:在同等物理空间内堆叠更多 HBM(高带宽内存)。HBM 虽带宽高,但仍是计算核心外的内存,存在访问延迟。为掩盖延迟,GPU 依赖超大 Batch Size 与大规模并行处理数据。因此,英伟达 GPU 本质上是一台并行计算机,它对算法与软件层的明确要求是:必须提供足够的 Batch Size 或并行度。
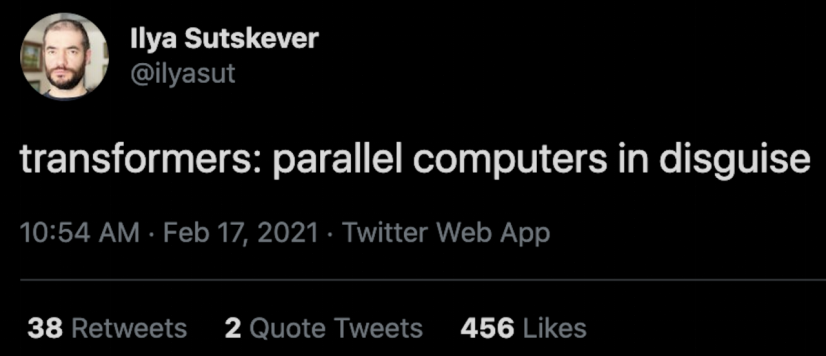
为满足这一要求,研究界提出了 RNN、Transformer、卷积序列模型等多种方案。最终,Transformer 脱颖而出,核心原因在于它本身也是一台并行计算机。正如 Ilya Sutskever 所言:“Transformers: parallel computers in disguise”(Transformer 是伪装成神经网络的并行计算机)。这一特性完美匹配了 GPU 的并行计算单元。
同时,OpenAI 实现的 Next-Token Prediction Loss 函数为模型提供了近乎无限的训练数据。理论上,BERT 的完形填空与 Next Sentence Prediction 也能提供大量数据,但实践中 Next-Token Prediction 效果更优。笔者推测,该函数最小化了人为干预,它并非人工设计,而是进化赋予人脑的自然逻辑。更重要的是,Next-Token Prediction 是对未来的预测,而 BERT 的完形填空是对历史信息的串联。预测未来远比解释过去困难,这恰恰体现了智能的核心。
以 Transformer 为核心的方案获得了双重优势:
- 模型每层参数量越多,并行度(Tensor Parallelism)越高。只要通信代价可控,便能利用更多算力。
- Transformer 的不同 Token 可同时计算。序列越长,并行度(Sequence Parallelism)越高,与 Data Parallelism 互补,进一步提升算力利用率。
就这样,从 GPT-1、BERT 到 GPT-3、ChatGPT、Gemini,智能被逐步提升至今日高度。那么,瓶颈何在?关键在于现有范式无法充分消化持续增长的算力。
假设一次模型训练消耗的浮点数计算次数从 10^n 增至 10^{n+3},我们是否能获得显著更好的模型?这里需澄清一个常见误区:很多时候,业界将“效率优化技术”与“智能提升技术”混淆了。
例如,若有一种新架构,仅用 20% 的参数量或计算量就能达到 GPT-5 类似效果,这更多关乎落地与商业化。而智能的终极问题是:使用同样的浮点数计算次数(而非 Token 量),能否训练出更好的模型。浮点数计算次数,才是衡量算力最本质的单位。

未来的方法探讨
在基础设施层面,核心硬指标并非单纯追求单颗芯片更强,而在于持续扩大绝对算力。即便单芯片算力未大幅提升,通过集群方式也能构建更大算力。关键是要平衡:集群带来的性能增长,必须高于芯片或服务器间通信开销的增长。
具体而言,需增长或至少维持住 “计算开销/通信开销” 这一比值。这是 AI 基础设施最核心的技术目标。实现它需要扩展性更好的并行计算技术,涵盖软件与硬件。
在更上层的算法与模型探索中,目标则是让 AI 模型在单位时间内“消化”更多能源,并将其转化为智能。笔者看好以下几个方向:
- 更高精度的计算能力。当前从 FP16 到 FP32、FP64,模型智能并未出现明显跃升,这本身就是一个瓶颈。更高精度应能带来更可靠的计算结果,这在传统科学计算中已得验证。
- 更高阶的优化器。据 Google 朋友透露,他们已在某些场景下用更高阶优化器替代类 Adam 优化器来训练模型。高阶优化器能在学习过程中提供更好指导,计算出更优梯度,这是提升模型智能的本质。
- 扩展性更好的模型架构或 Loss 函数。我们仍需寻找能更高效整合与利用算力的方法。需注意,优化效率不一定直接提升智能上限。例如 Mamba 架构重点在于提升吞吐,用更小模型获同等智能。但本文关注的是:在最优基础设施上,以最大可接受成本,能否训练出智能更高的模型。
- 更多的 Epoch 与更好的超参数。出于成本压力,当前我们对 AI 模型的优化远未深入,甚至未进行深度超参数搜索。这并非指盲目增加 Epoch,而是需要找到方法,让模型能有效“吸收”更多计算能源,并转化为更高智能。
一些技术如低精度训练、剪枝、量化、蒸馏等,对大规模 AI 落地至关重要,但它们与提升智能上限无关。笔者尊重这些技术的贡献,但它们不在本文探讨范围内。
智能增长归根结底是算力利用问题。假设算力无限,我们或许会发现比 Transformer 和 Next-Token Prediction 扩展性更好的简单结构。从 SVM、CNN、LSTM 到 BERT、GPT、MoE,我们始终在寻找能更高效利用算力且具备良好扩展性的方法,核心驱动力正是问题规模的持续扩大。
AI 时代前我们已实现天气预报,却仍未攻克地震预测,尽管二者同属地球数据研究。原因在于地下结构涉及变量规模呈指数级增长的复杂多模态数据,传统计算难以驾驭,而这正是未来 AI 技术的机遇所在。
因此,我们有信心未来会不断找到更高效的算力使用方式。过程或许充满挑战,但大趋势不可阻挡。
最后,借用 Richard Sutton 教授的论断:人工智能 70 年的研究留给我们最大的经验教训是,依托计算能力的通用方法才是最终的赢家,且具备压倒性的优势。
本文涉及的前沿讨论,可在云栈社区找到更多深度交流与资源分享。
 发表于 2026-1-3 11:21:28
|
查看: 244|
回复: 0
发表于 2026-1-3 11:21:28
|
查看: 244|
回复: 0
