前言
经过之前几节内容,我们的架构已经演变为 nginx->envoy->backend,并且envoy作为sidecar,与nginx在同一个pod中协同工作。但目前存在一个问题:nginx需要将流量转发到envoy,这必须修改nginx本身的配置文件。
upstream backend_ups {
server 127.0.0.1:10000; # 原配置 backend_service:10000
}
server {
listen 80;
listen [::]:80;
server_name localhost;
location /test {
proxy_pass http://backend_ups;
}
}
从两个层面来看,这种做法存在不足:
- 部署层不应该依赖于业务层的配置:理想状态下,这两者应当解耦。
- 底层转发应对业务层无侵入:业务层(这里是nginx)无需关心流量是如何被转发的,其配置和代码不应为此做出改变。
基于以上原则,本文将探讨如何在不修改业务层nginx任何配置的情况下,通过底层手段让envoy劫持业务流量。
原始的、未修改的nginx配置文件如下:
upstream backend_ups {
server backend-service:10000;
}
server {
listen 80;
listen [::]:80;
server_name localhost;
location /test {
proxy_pass http://backend_ups;
}
}
环境准备
如果一直跟随本系列实践的同学,可以重置一下测试环境。
修改域名映射
第一种思路是利用 hostAliases,将原本指向后端服务 backend-service 的域名解析,改为指向本地的 127.0.0.1,从而让nginx的请求直接发往本地的envoy。
修改nginx的Pod编排文件,添加如下内容:
...
hostAliases:
- hostnames:
- backend-service
ip: 127.0.0.1
# 注意:hostAliases和containers是同一级别
containers:
...
...
这种方法简单直接,但有两个明显的限制条件:
- 端口必须一致:如果后端服务(backend)的端口与envoy代理监听的端口不同,此方法无效。在本例中,两者恰好都是10000端口。
- 域名不能冲突:域名映射在Pod级别生效,对Pod内所有容器都起作用。这意味着nginx配置中使用的上游主机名,不能与envoy配置中要转发到的目标主机名相同。本例中,nginx转发到
backend-service,而envoy转发到 backend-headless-service,恰好不同。
由此可见,通过host映射劫持流量虽然最简单,但限制颇多,一旦上述任一条件不满足,就无法使用。
使用iptables
当简单方法行不通时,我们就需要请出网络层的“瑞士军刀”——iptables。它能够更精细地控制数据包的流向。
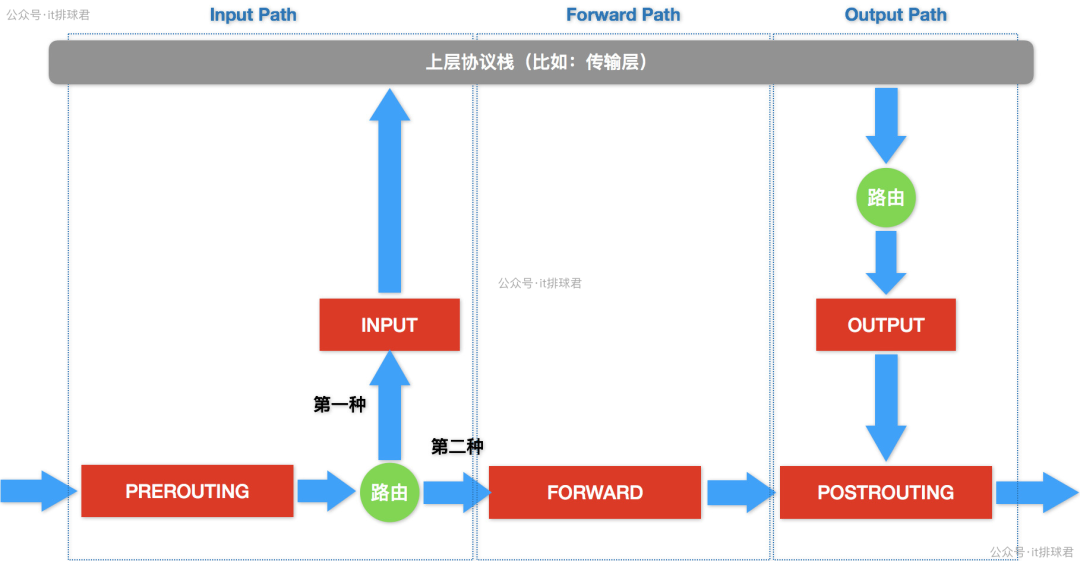
上图清晰地展示了数据包在iptables不同链(Chain)中的流转路径,是我们后续规则制定的理论基础。
劫持所有的出流量
我们的目标是:将所有从nginx容器发出、目的地为 backend-service:10000 的流量,劫持并重定向到本Pod内envoy容器监听的 127.0.0.1:10000。
由于本例中envoy和后端服务监听的都是10000端口,需要特殊处理以避免循环重定向(打环)。规则制定分为两步:
- 核心劫持规则:将目标端口为10000且目标IP不是127.0.0.1的TCP流量,重定向到本地的10000端口。
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000
-
放行envoy流量:为了避免envoy发出的、已经处理过的流量再次被劫持,我们需要识别并放行envoy发出的流量。可以通过进程的UID(用户ID)来识别。
# 首先,查询envoy容器内envoy用户的UID
kubectl exec -it nginx-test-557df7457b-dr7sf -c envoy -- id envoy
# 输出示例:uid=101(envoy) gid=101(envoy) groups=101(envoy)
# 然后,添加规则:UID为101的进程发出的所有流量直接返回(不匹配后续规则)
iptables -t nat -A OUTPUT -m owner --uid-owner 101 -j RETURN
注意规则顺序:RETURN规则必须放在REDIRECT规则之前。最终的规则集如下:
iptables -t nat -A OUTPUT -m owner --uid-owner 101 -j RETURN
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000
应用后,可以使用 iptables -L -n -t nat 查看规则是否生效。
上述方案展示了通过iptables在Kubernetes Pod内进行流量劫持的核心思想,这正是许多Service Mesh(如Istio)数据平面实现透明流量拦截的底层机制之一。
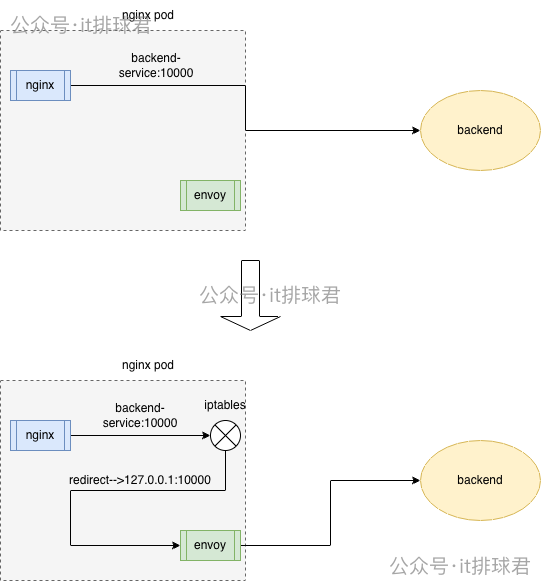
架构对比示意图:左图展示了Nginx Pod直接连接后端服务;右图展示了通过iptables规则,将Nginx发出的流量透明劫持到同Pod的Envoy Sidecar,再由Envoy进行后续转发。
但并非所有容器镜像都包含iptables命令。为了方便调试,我们可以使用nsenter进入容器的网络命名空间执行命令。
利用nsenter进入container网络命名空间
- 查找nginx容器ID:
sudo crictl ps | grep nginx-test
- 查找该容器对应的主机进程PID:
sudo crictl inspect <容器ID> | grep -i pid
# 找到 "pid": <PID数字> 这样的输出
- 进入容器的网络命名空间:
sudo nsenter -n --target <上一步查到的PID>
- 进入后,即可执行上述
iptables命令。
验证是否能够劫持流量
执行测试命令 curl <nginx-service-ip:port>/test,并查看nginx日志。如果日志显示请求到达nginx但envoy日志为空,说明流量未被成功转发到envoy。
问题排查
检查发现,nginx日志有记录但envoy无记录,意味着所有出流量都被 --uid-owner 101 的 RETURN 规则放行了。检查nginx的运行用户:
kubectl exec -it nginx-test-557df7457b-dr7sf -c nginx-test -- id nginx
# 输出示例:uid=101(nginx) gid=101(nginx) groups=101(nginx)
问题根源:envoy用户和nginx用户的UID都是101,导致iptables规则错误地放行了nginx的流量。
解决方案:
在调试阶段,我们采用第一种临时方案。这里可能有人会问,为什么同一个Pod内容器可以有相同的UID?因为每个容器默认拥有独立的PID namespace,UID在各自namespace内是独立的。当然,Kubernetes也支持通过 shareProcessNamespace: true 让Pod内容器共享PID namespace。
最终结果
调整envoy的UID并重新应用iptables规则后,再次测试。此时观察envoy日志,可以看到类似如下的记录,证明流量已被成功劫持并经由envoy转发至后端:
[2025-12-26T03:35:12.708Z] "GET /test HTTP/1.0" 200 40 1 856d3200-abb3-486f-8e4c-8441f20bdbb0 "curl/7.81.0" "-" 10.244.0.114:10000 app_service -
使用initContainers自动化配置
手动配置iptables规则不具备可操作性,我们需要一个自动化的工程方案。利用Kubernetes的initContainers,可以在主业务容器启动前,优先执行配置任务。
以下是一个示例配置,该初始化容器会安装iptables并设置规则:
initContainers:
- args:
- |
apk add --no-cache iptables
iptables -t nat -A OUTPUT -m owner --uid-owner 1234 -j RETURN
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000
command:
- /bin/sh
- -c
image: alpine:3.23
imagePullPolicy: Always
name: iptables-init
resources: {}
securityContext:
privileged: true # 需要特权模式来修改iptables规则
优化建议:每次启动都安装iptables不够优雅。更好的做法是构建一个包含iptables的专用基础镜像,供initContainer使用。
拦截入口流量
上文演示的是拦截出口流量(OUTPUT链)。如果需求是拦截入口流量(例如,将所有进入Pod 80端口的流量劫持到envoy的10000端口),原理相通,只需在 PREROUTING 链上添加规则。
# 将所有进入80端口的TCP流量重定向到10000端口
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 10000
# 依然要放行envoy自身的流量,防止打环
iptables -t nat -A OUTPUT -m owner --uid-owner 1234 -j RETURN
小结
本文详细阐述了如何利用iptables在Kubernetes Pod内实现透明的流量劫持,使业务层(Nginx)无需任何修改,其流量便能被导流至Envoy Sidecar。这成功地将部署层(流量治理)与业务层解耦。
值得注意的是,诸如Istio这类服务网格的底层,正是采用了类似的iptables机制来实现数据平面的透明流量拦截。当然,我们距离“手搓”一个完整的服务网格还有很远,本系列的重点在于逐步理解服务治理面临的问题及相应的解决方案。
然而,这种方法也引入了新的问题:流量需要在内核态(iptables)和用户态(envoy进程)之间多次拷贝和上下文切换,路径变为:Nginx -> iptables -> Envoy -> iptables。在高并发场景下,这会消耗可观的系统资源。如何进行优化?这将是后续更深层次的话题。
后记:关于共享PID Namespace
关于之前提到的UID冲突问题,如果强制设置 shareProcessNamespace: true 让Pod内容器共享PID namespace,会发生什么?
在Pod配置中启用共享:
containers: # 注意是containers级别的字段
...
shareProcessNamespace: true
进入容器查看进程:
kubectl exec -it nginx-test-54f5b78d57-x4kmj -c envoy bash
root@nginx-test-54f5b78d57-x4kmj:/# ps -ef
UID PID PPID C STIME TTY TIME CMD
65535 1 0 0 03:09 ? 00:00:00 /pause
root 7 0 0 03:09 ? 00:00:00 nginx: master process nginx -g daemon off;
envoy 27 0 0 03:09 ? 00:00:00 envoy -c /etc/envoy/envoy.yaml
envoy 33 7 0 03:09 ? 00:00:00 nginx: worker process
envoy 34 7 0 03:09 ? 00:00:00 nginx: worker process
可以看到,所有进程处于同一个PID命名空间下。由于UID相同(101),从envoy容器的视角看,nginx的worker进程的用户显示为envoy。这降低了命名空间的隔离性,并可能导致信号处理混乱(例如,哪个容器内的1号进程接收K8s的终止信号?),增加了复杂性。因此,是否共享PID namespace需要经过审慎评估。
希望本文的实践与探讨,能帮助你更深入地理解云原生环境下的网络流量管控。更多关于系统架构、容器化和运维的深度讨论,欢迎在云栈社区交流分享。
 发表于 2026-1-3 12:39:30
|
查看: 272|
回复: 0
发表于 2026-1-3 12:39:30
|
查看: 272|
回复: 0
