1 Linux软中断概述
1.1 什么是软中断及其设计动机
在Linux内核中,软中断(Softirq)是一种重要的延迟处理机制。它完全由软件触发,虽然被称为"中断",但实际上是一种在内核空间中延迟执行的机制。软中断与硬件中断有着本质区别:硬中断由外部设备向CPU发出请求,需要立即处理;而软中断由内核在合适时机触发,用于处理那些不要求立即完成但需要尽快处理的任务。
Linux内核引入软中断系统的主要动机源于核心需求:硬件中断处理程序需要尽可能快速执行,以便重新启用中断并避免数据丢失。然而实际应用中存在大量相对复杂且耗时的处理逻辑。这就产生了矛盾——如果所有处理都在硬件中断上下文中完成,会导致中断被禁用时间过长,增加事件丢失风险。为解决这个矛盾,内核设计者将中断处理分为两部分:
- 上半部(Top Half):在中断上下文中执行,负责最紧急、必须立即完成的操作,如确认中断接收、复位硬件等。这部分执行时通常会禁用其他中断,因此需要极其快速
- 下半部(Bottom Half):将中断处理中非紧急的、耗时的操作推迟到中断上下文之外执行,这时硬件中断已被重新启用,因此不会影响新的中断请求
生活化比喻:想象医院急诊室的工作模式。当危重病人送达时(硬件中断),医生立即进行最紧急的抢救(上半部),稳定病人生命体征。一旦病人情况稳定,更详细的检查、手术安排和康复治疗(下半部)就可以在稍后时间进行,这样既不耽误其他急症病人的接待,也能为当前病人提供全面治疗。
1.2 软中断的重要性与应用场景
软中断在现代Linux内核中扮演着至关重要的角色,它是整个内核性能优化的关键机制之一。通过软中断系统,内核能够平衡响应速度与处理吞吐量,在保证硬件中断及时响应的同时,不丢失重要的后续处理任务。
软中断的应用场景非常广泛,主要包括以下几个核心领域:
- 网络数据处理:这是软中断最典型和重要的应用场景。无论是数据包的发送(NET_TX_SOFTIRQ)还是接收(NET_RX_SOFTIRQ),都严重依赖软中断机制。当网卡接收到数据包并引发硬件中断后,中断处理程序只进行最基本的确认,随后通过软中断完成后续的协议栈处理
- 定时器处理(TIMER_SOFTIRQ):内核定时器到期的回调函数不在硬件中断上下文中执行,而是通过软中断机制执行,这保证了定时器中断能够快速处理,不因多个定时器到期而阻塞
- 任务延迟处理(TASKLET_SOFTIRQ):Tasklet是基于软中断的一种更简单的延迟执行机制,特别适用于驱动程序开发者。与软中断不同,同类型的tasklet在多个CPU上不能并发执行,这减少了同步的复杂性
- 块设备操作(BLOCK_SOFTIRQ):块设备的I/O操作完成后的处理也通过软中断执行,使得块设备驱动程序能够快速响应硬件中断,而将耗时的I/O完成处理推迟到软中断中
- 调度器负载均衡(SCHED_SOFTIRQ):多CPU之间的进程负载均衡操作通过软中断触发,这样调度器能够在合适的时机重新分配CPU负载,优化系统性能
设计哲学:软中断体现了Linux内核设计中一个重要的理念——"机制与策略分离"。软中断本身是一个机制,它提供了延迟执行的能力;而各个子系统如何利用这一机制则属于策略决策。这种分离使得内核能够保持高度的灵活性和可扩展性。
2 软中断的代码框架与数据结构
2.1 核心数据结构解析
Linux软中断系统的实现依赖于几个关键的数据结构,理解这些结构是深入掌握软中断机制的基础。内核通过精心设计的数据结构来管理软中断的注册、触发和执行,同时确保多核环境下的高效和安全。
softirq_action结构体是软中断系统的核心,它代表一个软中断处理程序。其定义非常简单,体现了Unix设计哲学中的简洁性:
struct softirq_action {
void (*action)(struct softirq_action *);
};
这个结构只包含一个成员——action函数指针,它指向软中断的实际处理函数。当软中断被触发时,内核会调用这个函数。这种简约的设计反映了Linux内核的一个基本原则:数据结构应该专注于单一职责。softirq_action只负责描述软中断处理程序,而不涉及其状态管理。
为什么使用这种简单设计?过于复杂的数据结构会增加维护成本和引入bug的风险。通过保持softirq_action的简洁性,内核确保了软中断机制的可靠性和高效性。处理函数接受指向softirq_action自身的指针作为参数,这种设计允许同一个处理函数服务于多个软中断,增强了代码的复用性。
软中断的类型在内核中是静态定义的,通过枚举类型明确列出了所有支持的软中断。这种静态定义方式保证了软中断类型的确定性和高效性:
enum {
HI_SOFTIRQ = 0, /* 高优先级tasklet */
TIMER_SOFTIRQ, /* 定时器 */
NET_TX_SOFTIRQ, /* 网络数据发送 */
NET_RX_SOFTIRQ, /* 网络数据接收 */
BLOCK_SOFTIRQ, /* 块设备操作 */
BLOCK_IOPOLL_SOFTIRQ,/* 块设备I/O轮询 */
TASKLET_SOFTIRQ, /* 常规tasklet */
SCHED_SOFTIRQ, /* 进程调度 */
HRTIMER_SOFTIRQ, /* 高精度定时器 */
RCU_SOFTIRQ, /* RCU延迟清理 */
NR_SOFTIRQS /* 软中断总数 */
};
这个枚举定义了系统中所有可用的软中断类型,注意NR_SOFTIRQS并不是一个实际的软中断,而是用于表示软中断数量的标记。Linux内核不建议开发者添加新的软中断类型,因为这需要修改核心代码并经过严格的审核。大多数驱动程序应当使用基于TASKLET_SOFTIRQ或HI_SOFTIRQ的tasklet机制。
irq_cpustat_t结构体负责记录每个CPU的软中断状态信息,这是多核感知的关键数据结构:
typedef struct {
unsigned int __softirq_pending;
} ____cacheline_aligned irq_cpustat_t;
____cacheline_aligned是一个重要的优化,它确保每个CPU的irq_cpustat_t实例独占一个缓存行,防止伪共享(False Sharing)问题。伪共享会严重降低多核系统的性能。
__softirq_pending字段是一个位图,每一位代表一种软中断类型是否处于待决(pending)状态。例如,当网络数据包到达时,网卡的中断处理程序会设置NET_RX_SOFTIRQ对应的位,表示有网络接收软中断等待处理。
2.2 软中断类型详解
每种软中断类型都有其特定的用途和执行上下文,了解这些特性对于正确使用软中断至关重要。下面是主要软中断类型的详细说明:
- HI_SOFTIRQ和TASKLET_SOFTIRQ:这两种软中断专门用于处理tasklet。HI_SOFTIRQ具有更高的优先级,会先于TASKLET_SOFTIRQ执行。它们的存在体现了内核在通用性与专用性之间的平衡——软中断是通用机制,而tasklet是基于软中断的专用简化接口
- NET_TX_SOFTIRQ和NET_RX_SOFTIRQ:网络子系统是软中断的重度用户。这两个软中断处理网络数据包的发送和接收。它们的实现经过精心优化,以应对高吞吐量的网络流量。特别是NET_RX_SOFTIRQ,在现代服务器上可能会消耗相当多的CPU时间,这也是网络性能调优的重点关注对象
- TIMER_SOFTIRQ:负责处理定时器回调函数。当硬件定时器中断发生时,中断处理程序仅仅标记定时器到期,实际的回调函数执行则在TIMER_SOFTIRQ中进行。这种分离确保了定时器中断的快速处理,不会因为大量定时器同时到期而阻塞
- BLOCK_SOFTIRQ:块设备子系统使用此软中断处理I/O完成后的操作。当磁盘读写操作完成时,硬件中断处理程序非常简短,而繁重的I/O完成处理则在BLOCK_SOFTIRQ中执行
为了更直观地展示软中断核心数据结构之间的关系,以下是它们的关系图:
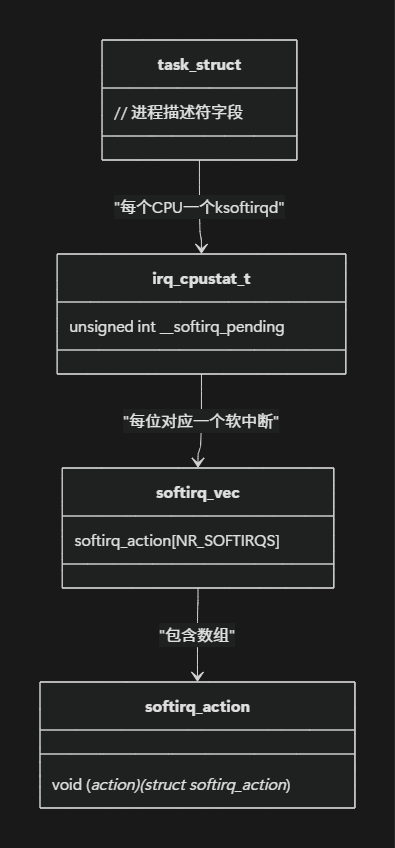
这个图表清晰地展示了软中断核心组件之间的关系:softirq_vec是一个全局数组,包含所有注册的软中断处理函数;irq_cpustat_t是每个CPU的数据结构,记录该CPU上哪些软中断处于待决状态;而task_struct则代表每个CPU上的ksoftirqd内核线程。
3 软中断的工作流程
3.1 软中断的完整生命周期
软中断从注册到执行完成涉及多个精密配合的环节,理解这一完整生命周期对于掌握软中断机制至关重要。软中断的生命周期可以分为三个主要阶段:注册初始化、触发待决和调度执行。每个阶段都有特定的API和内部机制支持,共同构成了软中断高效可靠的工作流程。
注册阶段发生在内核初始化过程中,各个子系统通过open_softirq()函数注册自己的软中断处理程序。这一过程通常在内核启动的早期完成,确保了系统的稳定性和确定性:
void open_softirq(int nr, void (*action)(struct softirq_action *)) {
softirq_vec[nr].action = action;
}
例如,网络子系统在初始化时会注册网络收发软中断:
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
这种集中式注册机制体现了内核设计的模块化原则——每个子系统只关注自己的处理逻辑,而软中断框架负责通用的管理和调度。
触发阶段是软中断生命周期的第二个环节。当某个子系统需要延迟执行任务时,它会调用raise_softirq()或raise_softirq_irqoff()函数来触发相应的软中断。这一操作通常在两种上下文中发生:硬件中断处理程序的退出过程中,或者内核的其他部分发现有待处理任务时。
raise_softirq()函数的实现展示了内核对于并发安全的细致考虑:
void raise_softirq(unsigned int nr) {
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
}
这个函数首先保存当前中断状态并禁用中断,然后实际触发软中断,最后恢复原来的中断状态。这种保护机制确保了在多核环境中对软中断待决位图的修改不会出现竞争条件。
3.2 软中断的触发与执行
软中断的触发和执行机制是理解其工作流程的关键。当raise_softirq_irqoff()函数被调用时,它会在当前CPU的软中断待决位图中设置对应的位,然后根据当前上下文决定如何唤醒软中断处理:
inline void raise_softirq_irqoff(unsigned int nr) {
__raise_softirq_pending(nr);
if (!in_interrupt())
wakeup_softirqd();
}
这里的判断条件!in_interrupt()非常关键——如果当前已经处于中断上下文中,则不需要特意唤醒ksoftirqd线程,因为软中断会在中断退出时自动得到处理。这种智能唤醒机制避免了不必要的线程切换开销。
执行阶段是软中断生命周期的最后一个环节,也是最为复杂的部分。软中断的执行有两个主要的入口点:中断退出路径和ksoftirqd内核线程。这种双重执行机制是软中断系统的核心创新,它在低延迟和公平性之间取得了精妙的平衡。
在中断处理程序退出时,内核会检查是否有待决的软中断,如果有则直接执行:
void irq_exit(void) {
// ...
sub_preempt_count(IRQ_EXIT_OFFSET);
if (!in_interrupt() && local_softirq_pending())
invoke_softirq();
// ...
}
在invoke_softirq()中,内核会调用do_softirq()或者直接调用__do_softirq()来执行待决的软中断。这是软中断处理的快速路径,能够保证较低的延迟。
然而,软中断处理可能因为各种原因被延迟,或者在一次执行中无法完成所有待决的软中断。为了防止软中断过度占用CPU而导致用户进程饥饿,内核引入了ksoftirqd机制。每个CPU都有一个专用的ksoftirqd内核线程,当软中断在中断上下文中无法及时处理,或者系统负载过高时,ksoftirqd会接手软中断的处理工作。
以下是软中断完整工作流程的示意图:
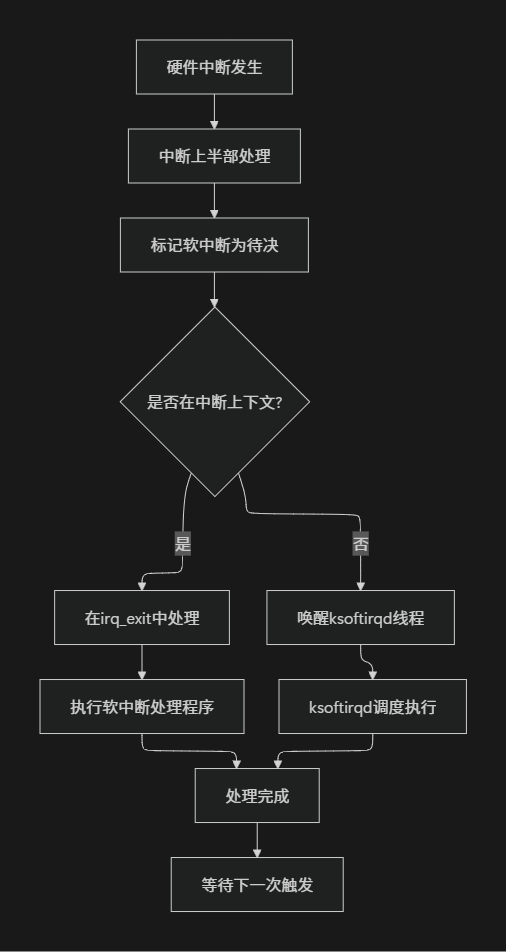
这个流程展示了软中断从触发到执行的完整路径,体现了Linux内核在性能优化方面的深思熟虑——通过快速路径保证低延迟,通过慢速路径保证公平性。
3.3 软中断的调度时机
软中断的调度时机对其性能特征有着决定性影响。内核精心选择了几个关键的调度点,在这些时间点检查并执行待决的软中断:
- 中断处理返回:这是最重要的软中断执行时机。当硬件中断处理程序完成后,在返回被中断的代码前,内核会检查是否有待决的软中断并执行它们。这种安排使得软中断能够几乎无延迟地执行
- 本地BH启用:当内核通过local_bh_enable()重新启用底半部处理时,会检查待决的软中断。这确保了之前被延迟的软中断能够及时得到处理
- 调度器决策:如果ksoftirqd线程被唤醒,调度器会在合适的时机将CPU分配给它,确保软中断最终能够完成,即使系统处于高负载状态
生活化比喻:将软中断的调度机制比作餐厅的订单处理系统。厨师在接到订单后(硬件中断),会立即开始烹饪最紧急的部分(上半部),然后将需要时间但不必立即完成的任务(如下午茶准备)标记为待处理(软中断触发)。餐厅经理(内核调度器)会在两种情况下处理这些待办任务:一是完成紧急订单后的空闲时间(中断返回),二是当待办任务积累较多时,指派专门的助手(ksoftirqd线程)来处理。这种安排既保证了紧急订单的快速响应,又确保了所有任务最终都能完成。
4 软中断的实际应用实例
4.1 基于Tasklet的简单驱动程序示例
Tasklet是建立在软中断之上的延迟执行机制,它简化了设备驱动程序开发者的工作。与直接使用软中断相比,Tasklet具有更简单的接口和更安全的并发语义——同一种Tasklet在多个CPU上不会并发执行,这大大减少了驱动程序开发者的同步负担。
下面我们通过一个简单的字符设备驱动程序示例,展示如何使用Tasklet实现延迟处理:
#include <linux/module.h>
#include <linux/init.h>
#include <linux/interrupt.h>
#include <linux/fs.h>
// 定义设备数据结构
struct my_device {
struct tasklet_struct my_tasklet;
int data;
} my_dev;
// Tasklet处理函数
static void my_tasklet_handler(unsigned long data)
{
struct my_device *dev = (struct my_device *)data;
printk(KERN_INFO "Tasklet executed on CPU %d, processing data: %d\n",
smp_processor_id(), dev->data);
// 这里可以执行更复杂的处理逻辑
dev->data *= 2;
}
// 设备读函数 - 模拟触发Tasklet
static ssize_t my_device_read(struct file *file, char __user *buf,
size_t count, loff_t *ppos)
{
// 更新数据
my_dev.data = 123;
printk(KERN_INFO "Triggering tasklet from CPU %d\n",
smp_processor_id());
// 调度Tasklet执行
tasklet_schedule(&my_dev.my_tasklet);
return count;
}
// 文件操作结构
static struct file_operations my_fops = {
.owner = THIS_MODULE,
.read = my_device_read,
};
// 模块初始化
static int __init my_init(void)
{
// 初始化Tasklet
tasklet_init(&my_dev.my_tasklet, my_tasklet_handler,
(unsigned long)&my_dev);
// 注册字符设备
register_chrdev(0, "my_device", &my_fops);
printk(KERN_INFO "My device module loaded\n");
return 0;
}
// 模块退出
static void __exit my_exit(void)
{
// 禁用并等待Tasklet完成
tasklet_kill(&my_dev.my_tasklet);
printk(KERN_INFO "My device module unloaded\n");
}
module_init(my_init);
module_exit(my_exit);
MODULE_LICENSE("GPL");
这个简单的驱动程序展示了Tasklet的典型用法:
- 初始化:在模块初始化时,通过tasklet_init()函数设置Tasklet处理函数和传递的参数
- 调度:当用户空间读取设备时,驱动程序调用tasklet_schedule()将Tasklet标记为待执行
- 执行:在内核选择合适的时机,Tasklet处理函数被调用,执行延迟操作
- 清理:在模块卸载时,使用tasklet_kill()确保Tasklet不会在模块卸载后继续执行
关键优势:使用Tasklet而非直接使用软中断的主要优点是简化了并发控制。驱动程序开发者不需要担心多个CPU同时执行同一种Tasklet,因为内核保证了同一Tasklet的串行化执行。这显著降低了设备驱动程序开发的复杂度。
4.2 网络收发中的软中断应用
网络子系统是软中断技术最经典和重要的应用场景。理解网络收发包中的软中断机制,对于网络性能分析和调优至关重要。网络收发使用两个专用的软中断:NET_RX_SOFTIRQ用于数据接收,NET_TX_SOFTIRQ用于数据发送。
以下是网络数据包接收过程中软中断参与的简化序列图:
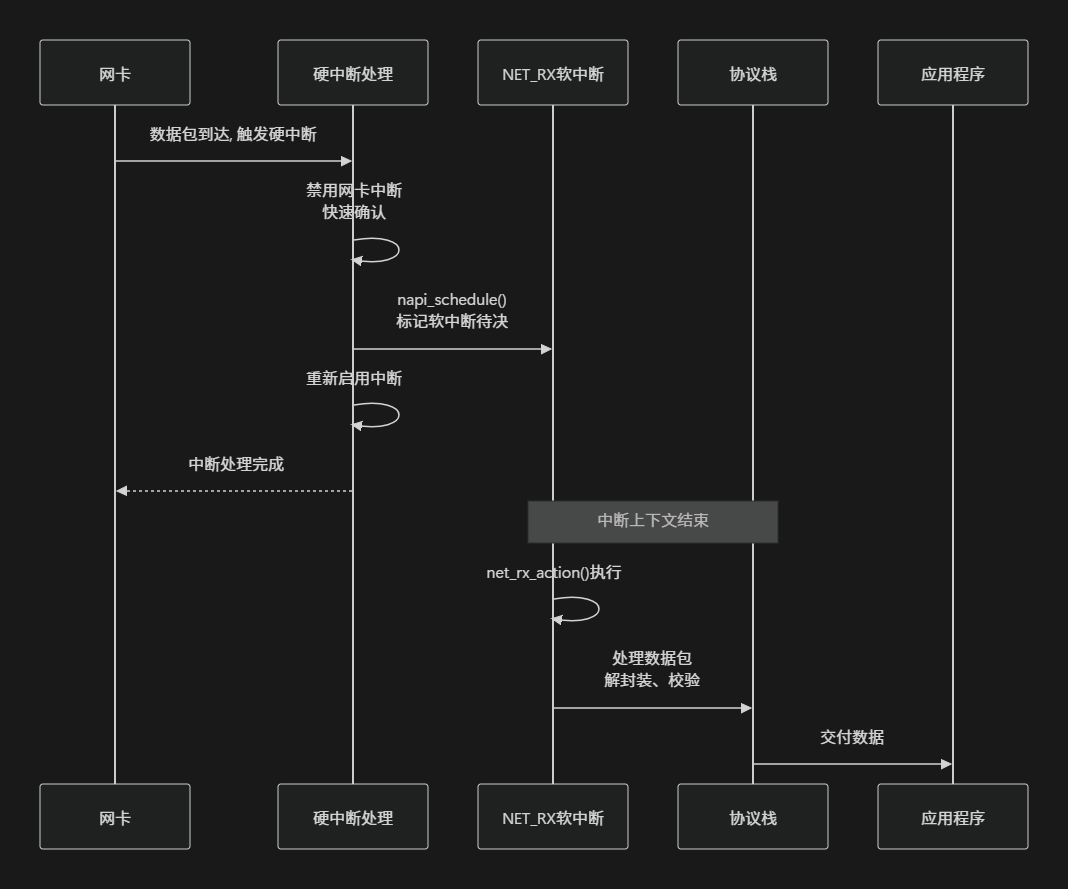
这个序列图清晰地展示了网络收包过程中硬中断和软中断的分工协作:
- 硬中断阶段:当网卡接收到数据包时,会触发硬件中断。中断处理程序执行最紧急的操作——禁用网卡中断(防止重复中断)、确认中断接收,然后通过napi_schedule()函数调度网络收包软中断。这个过程非常快速,确保了中断处理不会占用过多时间
- 软中断阶段:在中断处理后,
NET_RX_SOFTIRQ软中断被触发,执行net_rx_action()函数。这个函数包含完整的数据包处理逻辑:从网卡DMA区域读取数据包、进行协议解析(IP、TCP/UDP等)、最终将数据交付给相应的应用程序
性能考量:在网络流量很大的情况下,NET_RX_SOFTIRQ可能会消耗相当多的CPU时间。这可以通过top命令中的si(软中断)字段观察到。如果发现单个CPU的软中断处理成为瓶颈,可以考虑使用RPS(Receive Packet Steering)技术将软中断负载分散到多个CPU上。
网络数据包的发送过程类似,不过使用的是NET_TX_SOFTIRQ软中断。当应用程序发送数据时,内核并不立即将数据传递给网卡,而是先缓存起来,然后通过软异步处理实际的数据发送,这种延迟发送机制能够合并小数据包,提高网络利用率。
5 监控、调试工具和方法
5.1 常用监控工具详解
要深入了解软中断的行为和性能特征,Linux提供了多种强大的监控和调试工具。这些工具从不同维度展示软中断的活动情况,帮助开发者诊断性能问题和异常行为。
/proc/softirqs文件是最直接的软中断监控接口,它展示了系统中每个CPU上各种类型软中断的触发次数。查看这个文件可以获取软中断活动的全局视图:
$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 0 0 0 0
TIMER: 2831512516 1337085411 1103326083 1423923272
NET_TX: 15774435 779806 733217 749512
NET_RX: 1671622615 1257853535 2088429526 2674732223
BLOCK: 1800253852 1466177 1791366 634534
BLOCK_IOPOLL: 0 0 0 0
TASKLET: 25 0 0 0
SCHED: 2642378225 1711756029 629040543 682215771
HRTIMER: 2547911 2046898 1558136 1521176
RCU: 2056528783 4231862865 3545088730 844379888
分析这个输出时,应该关注几个关键点:
- 负载均衡:检查同一种软中断在不同CPU上的分布情况。如果发现某种软中断过度集中在某个CPU上(如上述输出中的NET_RX在CPU3上明显更高),可能会成为性能瓶颈。这时可以考虑使用中断平衡技术(如RPS、RFS)来改善负载分布
- 相对比例:观察不同类型软中断的相对比例。在正常运行的系统中,TIMER、NET_RX、NET_TX和SCHED通常会有较高的数值。如果某种特定类型的软中断异常活跃,可能指示相关子系统的问题或特殊工作负载
top命令提供了系统级软中断活动的实时视图。在top界面中,可以查看第三行的si字段,它表示系统在软中断上花费的CPU时间百分比:
$ top -n1 | head -n3
top - 18:14:05 up 86 days, 23:45, 2 users, load average: 5.01, 5.56, 6.26
Tasks: 969 total, 2 running, 733 sleeping, 0 stopped, 2 zombie
%Cpu(s): 13.9 us, 3.2 sy, 0.0 ni, 82.7 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
这里的si值为0.1%,表示当前有0.1%的CPU时间用于处理软中断。在网络密集型或块设备密集型工作负载下,这个值可能会显著升高。如果si持续保持高位,可能表明系统正在处理大量的软中断,需要进一步分析是哪些软中断类型导致的。
5.2 高级调试技术与性能优化
当初步监控发现软中断相关问题时,需要使用更高级的调试技术进行深入分析。这些技术可以帮助定位性能瓶颈和异常行为的根本原因。
动态调试是分析软中断行为的强大工具。可以通过内核的动态调试功能实时观察软中断的触发和执行情况:
# 启用软中断相关调试信息
echo 'file kernel/softirq.c +p' > /sys/kernel/debug/dynamic_debug/control
echo 'file net/core/dev.c +p' > /sys/kernel/debug/dynamic_debug/control
# 查看调试输出
dmesg -w
这种方法可以实时跟踪软中断的调度和执行流程,对于理解复杂系统中的软中断行为非常有帮助。
性能剖析工具如perf可以提供软中断的详细性能数据,帮助定位热点函数:
# 记录软中断相关性能事件
perf record -e softirq:softirq_entry -a sleep 10
# 分析性能数据
perf report
或者更直接地分析软中断处理函数的CPU时间:
# 记录系统所有函数性能数据
perf record -g -a sleep 10
# 生成火焰图数据
perf script | FlameGraph/stackcollapse-perf.pl | FlameGraph/flamegraph.pl > softirq.svg
优化策略:基于监控和调试结果,可以采取多种优化措施改善软中断相关性能:
- 中断平衡:对于网络中断,可以使用ethtool命令调整多队列网卡的中断亲和性,将中断处理分散到多个CPU上:
# 设置网卡eth0的RX队列0由CPU0处理
ethtool -X eth0 equal 2
# 或者手动设置队列到CPU的映射
ethtool -X eth0 queue 0 0 1 2 3
- 软中断线程化:在某些实时性要求高的场景下,可以考虑将软中断线程化,但这需要内核配置相应选项并可能增加延迟
- 调整软中断预算:内核通过net.core.netdev_budget参数控制一次软中断循环中处理的最大数据包数量,适当调整这个值可以平衡延迟和吞吐量:
# 查看当前预算值
sysctl net.core.netdev_budget
# 调整预算值(默认300)
sysctl -w net.core.netdev_budget=600
以下表格总结了常用的软中断监控工具和它们的适用场景:
| 工具/方法 |
提供信息 |
适用场景 |
优点 |
局限 |
| /proc/softirqs |
各CPU软中断计数 |
负载分析、瓶颈识别 |
全局视图、细粒度 |
历史数据缺失 |
| top命令 |
系统级软中断CPU占比 |
实时监控、快速评估 |
简单直观、系统视图 |
缺乏详细信息 |
| dynamic_debug |
软中断执行流程 |
问题调试、行为分析 |
详细跟踪、动态启用 |
输出量大、需过滤 |
| perf工具 |
性能热点、调用关系 |
性能优化、瓶颈分析 |
功能强大、可视化 |
需要专业知识 |
6 总结
6.1 软中断的设计哲学与实现精髓
Linux软中断机制体现了操作系统设计中的多个重要哲学思想,其中最核心的是分离关注点和平衡取舍。通过将中断处理分为紧急的上半部和延迟的下半部,软中断成功解决了硬件中断处理中快速响应与完整处理之间的矛盾。
软中断的实现展示了Linux内核设计的几个精髓原则:
- 机制与策略分离:软中断框架本身是一个通用机制,它不关心具体的处理逻辑,只提供延迟执行的基础设施。而各个子系统如何使用这一机制则属于策略决策。这种分离使得内核能够保持高度的灵活性和可扩展性
- 多核感知设计:从最初仅支持单处理器到全面支持SMP系统,软中断的实现始终考虑多核环境下的性能和行为。每个CPU独立的待决位图和处理线程,以及精心设计的锁策略,确保了在多核系统上的高效运行
- 性能与公平的平衡:通过快速路径(中断返回时直接处理)和慢速路径(ksoftirqd线程)的结合,软中断在低延迟处理和系统公平性之间取得了平衡。当软中断负载过高时,ksoftirqd会主动让出CPU,防止用户进程饥饿
6.2 软中断在实际系统中的意义
在现代Linux系统中,软中断已发展成为不可或缺的基础设施,支撑着多个关键子系统的正常运行。网络、存储、调度等核心功能都依赖于软中断提供的延迟处理能力。
对于系统开发者和运维人员而言,深入理解软中断机制具有重要实践意义:
- 性能调优:通过监控/proc/softirqs和top中的si指标,可以识别系统瓶颈并采取针对性优化措施,如调整中断亲和性、使用RPS/RFS等技术
- 问题诊断:异常的软中断模式往往是系统问题的早期指示。例如,突然增加的NET_RX软中断可能表明网络流量激增或某种网络攻击;而BLOCK软中断的异常则可能指示存储子系统的问题
- 架构设计:对于开发内核模块或驱动程序的开发者,理解软中断的特性和约束有助于设计更高效可靠的代码。知道何时使用tasklet、何时使用工作队列,以及如何正确地在中断上下文和进程上下文之间同步数据,是高质量内核编程的关键
通过本文从原理到实战的全面解析,相信读者已经对Linux软中断机制有了深入理解,能够在实际工作中更好地应用这一重要技术进行系统优化和问题排查。
 发表于 2025-11-27 02:29:00
|
查看: 183|
回复: 0
发表于 2025-11-27 02:29:00
|
查看: 183|
回复: 0
