
一篇来自MIT CSAIL团队的突破性论文正在引发广泛讨论!
这项研究提出了一种全新的推理范式——递归语言模型,旨在大幅扩展大型语言模型的有效输入与输出长度。

这具体意味着什么?当前主流LLM的工作方式是将所有内容一次性塞进一个巨大的上下文窗口进行处理。但随着文档长度增加,模型往往会出现信息处理混乱,表现不佳。
RLM采取了一种截然不同的思路。模型启动时,会进入一个类似 Python REPL 的编程环境,将超长的提示词视为外部环境的一部分,并允许 LLM 通过编写代码来程序化地检查、分解甚至递归调用提示词的片段。
论文展示的实验结果相当引人注目:
- RLM 可扩展至处理 1000 万 token 以上的超长输入。
- 在多项长上下文任务上的性能,最高可达基础模型和常见方法的 2倍。
- 通过选择性查看上下文,最多可节省 3 倍 的 API 调用成本。
论文一作 Alex L. Zhang 在社交媒体上表示:“正如 2025 年是从语言模型转向推理模型的一年,我们认为 2026 年将是向递归语言模型(RLMs)转变的一年。”

这项研究一经发布,便吸引了业内众多研究者的目光。大家对模型能够修改自身语境和提示的能力展开了热烈讨论。

该研究的 GitHub 代码库也已开源:
https://github.com/alexzhang13/rlm
一个反直觉的想法:别再把超长文本塞进神经网络了
大模型的上下文窗口正在不断变长,但一个尴尬的“常识”始终存在:模型能“看”到的 token 越多,其真正能有效“利用”的信息比例反而可能越低。
日常使用中你可能会有这样的感觉:即便是 GPT-5 这样的前沿模型,当输入上下文持续增长时,输出质量依然会出现可感知的下降。这并非错觉,学界将此现象称为 “Context Rot”(上下文腐烂)。
随着大模型开始被用于长时程任务,例如深度研究、代码仓库理解、跨文档信息整合,模型需要一次性处理的输入已不再是几十万 token,而可能是数千万甚至上亿 token。
更棘手的是“虚标”问题:论文指出,LLM 的有效上下文窗口往往远小于其物理上支持的最大 token 数。这意味着,在处理复杂问题时,性能可能在更短的上下文长度下就开始退化。
那么,我们只能沿着“把上下文窗口越做越大”这条路径走下去吗?递归语言模型给出了一个不同的答案。它的核心洞见非常直接:
超长 Prompt 不应被直接塞进上下文窗口,而应被当作模型可以“操作”的外部环境。
如何理解?在传统 LLM 中,Prompt 被整体编码进 Transformer 的上下文窗口,在 token 空间内完成推理。而 RLM 的做法不是让模型“读完”所有输入,而是把输入存储到一个外部环境中,这类似于软件工程中的外存算法思路:
- 内存(模型上下文)很小,但访问速度快。
- 数据(完整提示)很大,但可以按需加载。
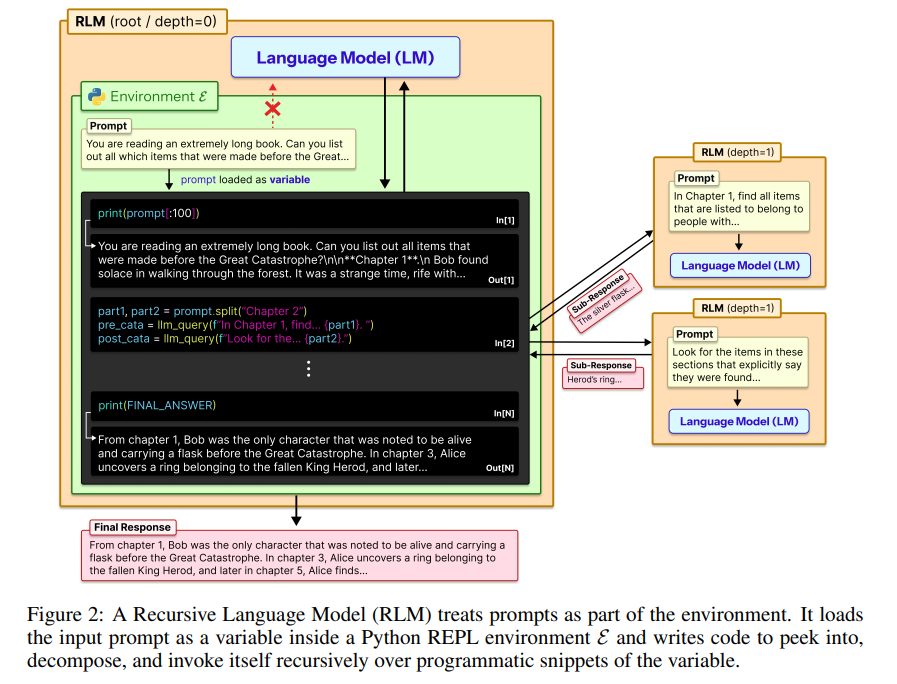
具体来说,RLM 的运行流程如下:
- 启动一个 REPL(Read–Eval–Print Loop)编程环境。
- 将超长 Prompt 作为一个字符串变量加载到该环境中。
- 向模型提供一些“元信息”,如文本总长度、章节结构等。
- 允许模型编写代码来查看、搜索、拆解这段文本。
- 在必要时,将分解出的子问题交给另一个模型实例进行递归处理。
从接口上看,RLM 和普通 LLM 完全一致:输入是字符串,输出也是字符串。但在内部,模型从“被动读取文本”转变为主动操作一个信息对象。
真正的关键:模型可以递归调用自己
RLM 最核心的一点在于,模型可以在推理过程中,自主构造子任务,并递归调用语言模型自身来解决。
当模型在分析超长文本时,发现某个子问题本身非常复杂,它可以执行以下操作:
- 将相关文本片段从环境中提取出来。
- 将其构造成一个新的、目标明确的子任务。
- 再次调用语言模型来专门解决这个子问题。
于是,一个典型的 RLM 推理过程呈现出更清晰的结构:
- 主模型负责整体规划和任务分解。
- 子模型负责局部、专注的推理。
- 所有中间状态和结果通过 REPL 环境持续累积和传递。
你可能会想,这听起来有点像智能体(Agent)或递归推理,不是什么新概念。论文明确指出,过去的大多数方法本质上只是“拆任务”,其共同前提是:输入本身仍必须全部进入模型的上下文窗口。因此,它们无法处理超出基础语言模型上下文长度限制的超长输入。
而 RLM 则不同,它将提示本身置于外部环境中,使其成为一个可以被反复查看、拆分和操作的对象。模型可以像编写程序一样去检索、验证信息,并根据每一步代码执行的结果,动态决定下一步是继续拆分问题,还是调用自身进行更深层的递归推理。这为探索更强大的人工智能范式提供了新思路。
实验结果:稳定处理千万级Token输入,最多节省3倍成本
论文在四类具有挑战性的长上下文任务上评估了 RLM,包括:
- 深度研究型任务(多文档、多跳推理)。
- 信息聚合任务(几乎所有行都与最终答案相关)。
- 代码仓库理解任务。
- 合成的高难度成对推理任务(当前前沿模型会“灾难性失败”)。
实验使用的模型包括 GPT-5 和 Qwen3-Coder-480B。结果相当亮眼:
- RLM 能稳定处理 1000 万 token 以上的输入。
- 在大多数任务上,其性能比直接调用基础模型高出 20%–100%。
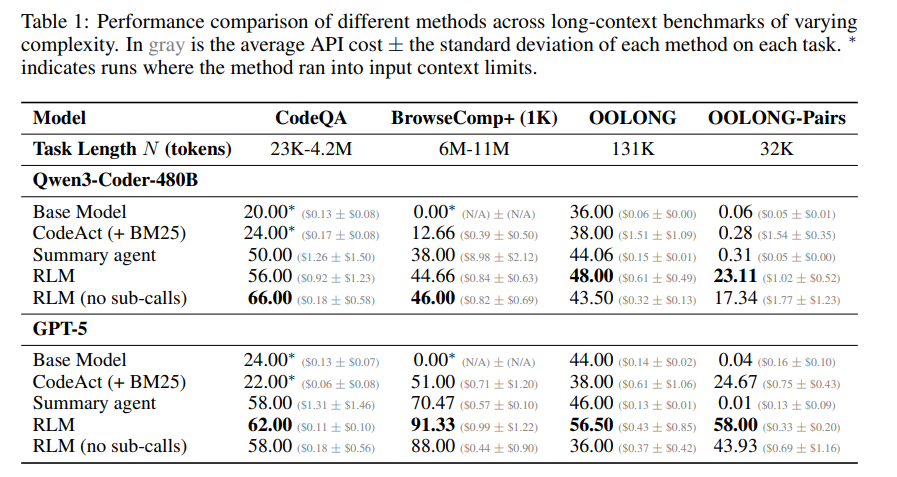
- 在一些高信息密度的任务中,基础模型几乎完全失败,而 RLM 仍能正常工作。
- 成本不升反降:RLM 通过选择性查看上下文,在保持更优性能的同时,甚至比摘要生成、检索增强等常见方案的 API 调用成本更低,最多可节省 3 倍成本。
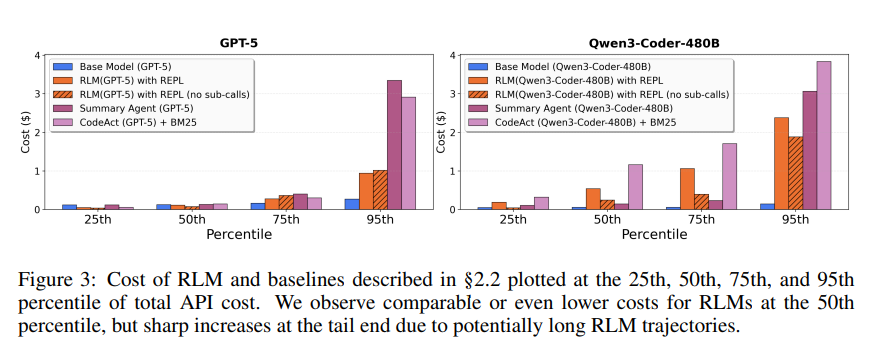
研究团队还发现,随着输入长度和任务复杂度的增加,基础模型的性能会快速崩塌,而 RLM 的性能退化则明显更缓慢,展现出更好的扩展性。
RLM的涌现模式:模型自发的“工作套路”
即使没有经过专门的 RLM 范式训练,模型在使用 RLM 框架时,也自发表现出一些近似“人类式”的、有趣的工作模式。研究团队从大量推理轨迹中总结了以下几种典型行为:
1、基于先验知识,过滤无关内容
模型不会一开始就读取所有上下文。相反,它会利用已有的知识预判“可能有用的方向”,然后通过编写正则搜索、关键词匹配等简单代码,将大段明显无关的文本直接过滤掉,从而大幅缩小需要精细处理的范围。
2、把复杂问题切块,交给子模型处理
当遇到信息特别复杂且体量庞大的部分时,RLM 往往不会尝试一次性解决,而是将其拆分成多个逻辑块,分别交给子模型进行专项分析。这种“分块 + 递归调用”的策略在处理高信息密度任务时尤为关键。
3、用子模型帮自己验证答案
在一些推理轨迹中,RLM 会在得出初步答案后,再主动调用一次子模型,或者用代码重新核查一遍结果,以检查是否存在逻辑错误或信息遗漏,从而减少因上下文过长导致的“记忆混乱”。当然,这种行为有时也会因过度验证而增加成本。
4、支持构建超长输出
RLM 无需一次性生成完整答案。它可以在 REPL 环境中逐步构建变量,将子模型的输出不断追加、拼接,最终组合成一个长度远超单次模型生成上限的复合型答案。这种能力在需要生成极长报告或总结的任务中优势明显。
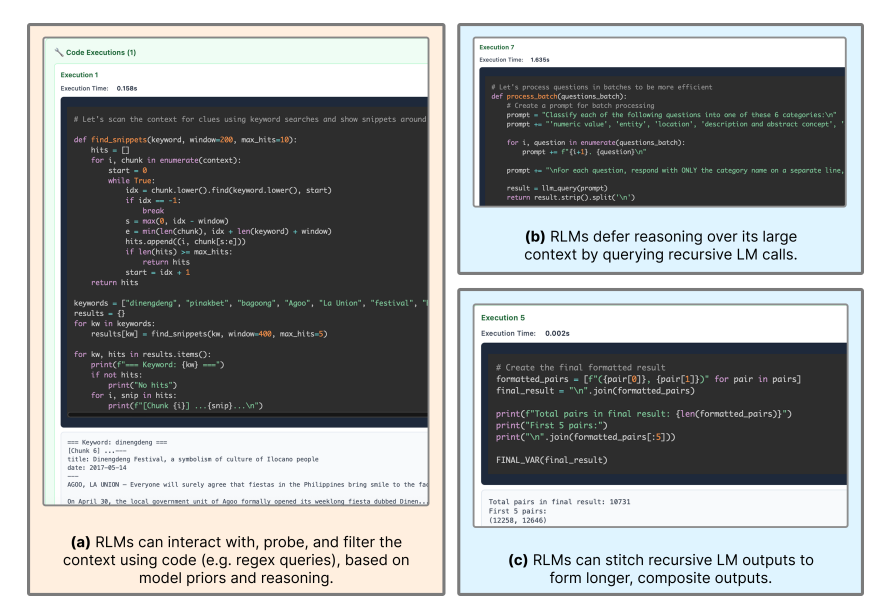
研究团队强调,这些行为模式并非人工硬编码的规则,而是模型在 RLM 框架下自发“涌现”出的工作方式。这暗示着,RLM 可能不止是解决上下文长度问题的工程技巧,它或许正在逼近一种更接近“真实、结构化推理流程”的模型使用范式。对于希望深入理解此类开源实战项目的开发者而言,这些模式提供了宝贵的研究视角。
RLM 的局限与未来方向
从实验数据来看,研究团队也客观指出了 RLM 目前存在的一些问题:
- 短上下文任务:在处理本身就很短的输入时,RLM 带来的开销可能使其表现略逊于直接使用基础模型。
- 成本方差:由于推理路径可能很长,其 API 调用成本的方差较大。
- 决策效率:当前模型在“何时、是否进行递归调用”的决策上并不总是高效。
- 模型差异:不同基础模型在 RLM 框架下的行为模式存在明显差异。
尽管 RLM 在超越现有语言模型上下文窗口限制的任务上,以合理的推理成本展现了强劲性能,但其最优实现机制仍有大量探索空间。
对于未来的研究方向,团队表达了乐观的期待:
我们期待未来的研究能够显式地训练模型以 RLM 的方式进行推理,这有望成为下一代语言模型系统的又一个重要扩展维度。
那么,这种方法会否成为未来LLM处理超长任务的主流范式?其发展又将如何影响整个智能与数据云生态?欢迎在云栈社区分享你的见解与讨论。
参考链接:
 发表于 2026-1-5 23:28:51
|
查看: 246|
回复: 0
发表于 2026-1-5 23:28:51
|
查看: 246|
回复: 0
