本帖最后由 贝塔零点一 于 2026-3-12 16:58 编辑
本文基于 AliSQL 8.0 20251031 版本,介绍一系列优化策略,引入内存驻留的 Nodes Cache 加速向量搜索效率,并基于该缓存结构实现读写并发控制与读已提交(RC)级别事务隔离,保障向量操作的可靠性与性能,使向量能力满足生产级要求。
节点缓存 Nodes Cache
如下图所示,AliSQL 引入了向量数据的公共缓存(MHNSW Share)和事务缓存(MHNSW Trx),用于加速向量查询性能并保证向量更新的事务安全,实现资源隔离与性能优化的平衡。
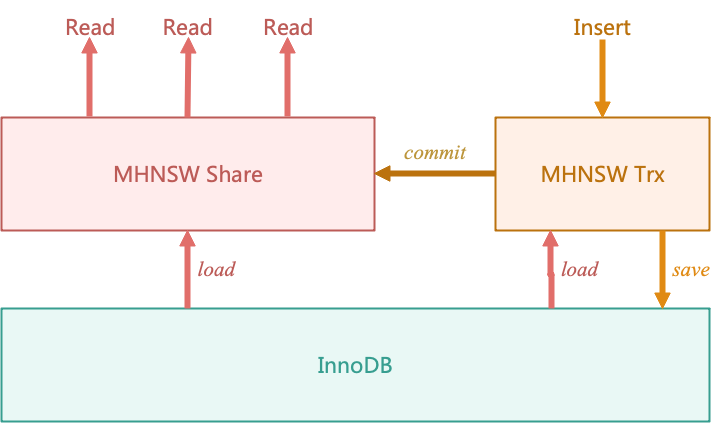
公共缓存和事务缓存供不同的操作访问,有不同的设计目标:
- 【公共缓存】MHNSW Share 供只读事务访问,挂载于辅助表的
TABLE_SHARE 上。其核心目标是通过共享缓存减少重复加载向量节点的开销,提升查询效率。
- 【事务缓存】MHNSW Trx 继承自 MHNSW Share,供读写事务使用,挂载于会话的
thd_set_ha_data。每个读写事务创建独立的 MHNSW Trx 实例,缓存其访问的节点包括其修改的节点,避免对公共缓存造成污染,仅在提交时去更新公共缓存。
事务隔离
AliSQL 目前支持向量读写的 RC(读已提交)隔离级别。通过区分读写事务和只读事务的访问缓存及提交流程实现:
- 【只读事务】 执行 HNSW 查询算法,优先访问公共缓存 MHNSW Share,只有当访问节点未在缓存内时,才从 InnoDB 引擎中加载符合 RC(读已提交)可见性的节点信息。当多个只读事务多次访问同一向量节点,只需要从 InnoDB 引擎加载一次节点信息,有效提高了向量的查询性能。
- 【读写事务】 进行插入时会构造会话级别的事务缓存 MHNSW Trx,插入过程可以分为多个阶段:
- 读操作:基于事务的可见性,从 InnoDB 加载需要的节点信息,在事务缓存中执行 HNSW 插入算法,确定新插入节点的在各个 layer 的邻居信息,以及这些邻居的邻居信息。
- 写操作:将新插入节点和更新了邻居信息的节点都保存到 InnoDB 引擎中。
- 提交或回滚
- 提交:更新公共缓存的版本号,并在公共缓存中淘汰这次写操作修改过的所有节点即过期节点,当其他只读事务访问这些被修改过的节点时,就需要从 InnoDB 引擎中重新加载最新的节点信息。
- 回滚:直接丢弃事务缓存,依赖 InnoDB 引擎的回滚机制恢复数据。
并发控制
AliSQL 在缓存内和缓存之间设计了合理的锁机制,目前支持读读、读写之间并发进行,暂时不支持同一张向量表的写写并发。并发控制机制在多线程访问中维持缓存状态的原子性与可见性,保障高并发场景下的数据一致性。
读读并发
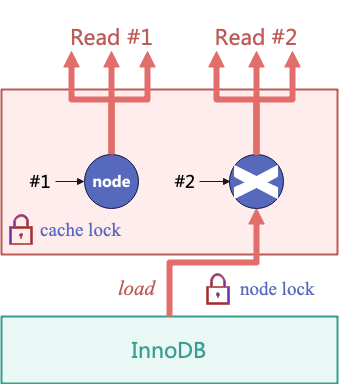
结合缓存互斥锁(cache_lock)和节点锁(lock_node)保证多个读请求之间的并发安全。如下图所示,只读请求访问一个节点时,首先根据节点的 id 在公共缓存中寻找这个节点。公共缓存是一个底层为 hash 表的节点缓存,hash 表的读写使用缓存互斥锁(cache_lock)保护。若节点不存在于公共缓存中,则创建一个空节点加入公共缓存。获取了节点的线程若发现节点为空,则需要从 InnoDB 引擎加载,使用节点锁(lock_node)保证只有一个线程去 InnoDB 引擎请求节点信息。
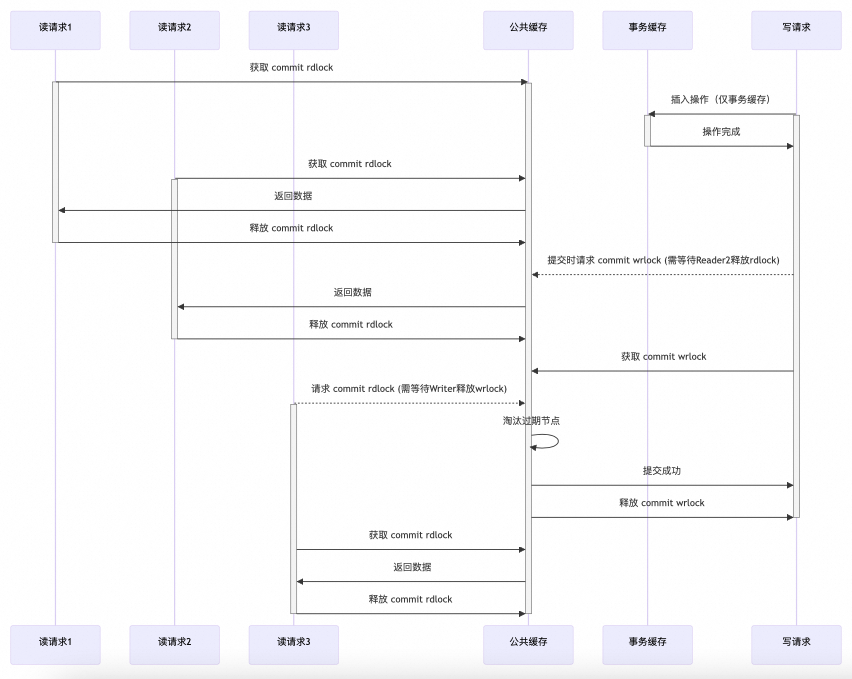
读写并发
使用提交读写锁(commit rwlock)实现读请求与写请求之间的并发安全。如下图所示,读请求全程持有提交读锁(commit rdlock),写请求在执行插入算法的过程中,仅操作线程创建的事务缓存,直到事务提交时,请求公共缓存的提交写锁(commit wrlock),淘汰公共缓存中的过期节点。所以总的来说,提交读写锁(commit rwlock)保障了读请求与写提交之间的读写并发安全。
向量计算优化
在向量数据库的高维数据检索场景中,向量距离的计算效率直接决定了查询性能。针对这一瓶颈,AliSQL 通过预计算策略与SIMD 指令集加速实现了显著的性能优化,兼顾了计算效率与缓存一致性。
预计算策略
在节点缓存加载阶段,系统会预先计算向量距离并缓存结果,从而避免对高频访问节点的重复计算。例如,对于频繁参与查询的节点,系统通过 FVectorNode 结构中的 version 字段进行版本控制:当节点数据未发生变化时,直接复用预计算结果;若数据更新导致版本变更,则触发重新计算。这种机制有效减少了无效计算,将高频节点的查询延迟降低了 40% 以上。
SIMD 指令集加速
在计算优化层面,AliSQL 利用现代 CPU 的 SIMD 指令集(如 AVX512)对向量距离计算进行加速。通过布隆过滤器,系统能够批量处理多个向量,将原本需要多次执行的标量运算转换为并行化的向量操作。这一优化显著减少了 CPU 指令周期的消耗。
实际测试表明,单个节点的向量距离计算性能提升超 75%。在 1000 万级规模的向量数据集中,SIMD 优化使查询吞吐量提升了 3 倍以上,充分验证了硬件加速在大规模数据处理中的价值。
预计算策略与 SIMD 加速并非孤立存在,而是形成了互补关系:预计算通过缓存机制降低高频查询的延迟,而 SIMD 加速则优化了单次计算的执行效率。两者的结合提升了向量操作的整体效率。
总结
通过公共缓存和事务缓存的协同设计,AliSQL 实现了向量索引的高效缓存与事务隔离,保障了高并发场景下的数据一致性与查询性能。目前支持向量数据的读读并发、读写并发,可覆盖主流的向量操作场景,锁策略则保障了并发安全。最后,通过预计算策略和 SIMD 加速提高向量计算并发度和速度,进一步提高了向量操作的整体效率。
本文介绍了 AliSQL 向量索引支持事务性与并发控制的原理,但写写并发能力的缺陷导致向量索引的构建无法并发,表级别的 nodes cache 不能很好地进行整个实例的所有向量索引的内存管理。想了解更多前沿数据库技术实践,欢迎访问云栈社区进行交流与探讨。 |  发表于 2026-1-6 00:16:01
|
查看: 217|
回复: 0
发表于 2026-1-6 00:16:01
|
查看: 217|
回复: 0
