DeepSeek 在2025年底发布了一篇题为《mHC: Manifold-Constrained Hyper-Connections》的论文,提出了一种新的神经网络架构设计。这对于正在学习 Transformer 架构的我来说非常及时,补充了我对残差连接理解的不足。
该论文提出的架构,旨在替代传统的残差连接。
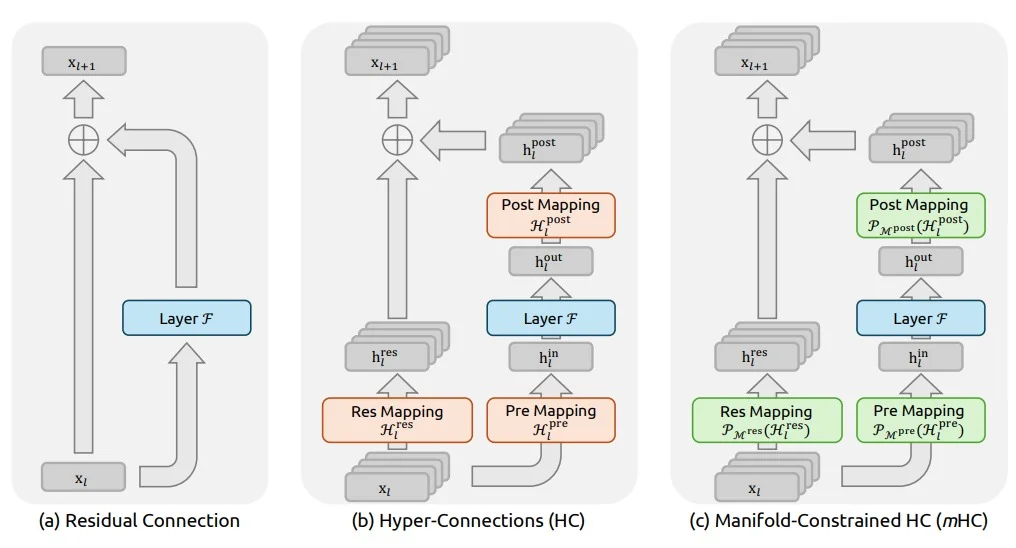
mHC 是对 HC 的改良
首先,mHC(Manifold-Constrained Hyper-Connections)是对 HC(Hyper-Connections)的改良。从一个标准 Transformer 架构的大语言模型(LLM)的推理过程来看,从数学上讲,就是原始词向量输入,叠加前文所有信息,在模型内部经过层层计算,词向量会不断变形。
在注意力机制环节,向量根据上下文内容变形。例如,在句子“他爸爸喝了酒,打了他,他……”中,最后一个“他”字的原始词向量,经过注意力计算后,可能变成一个蕴含了“一个被醉酒的爸爸殴打、可能受伤或愤怒的人”等信息的向量。
这个向量经由标准残差连接的计算,被附加到原始词向量上,形成一个携带了上下文信息的向量,随后送入 FFN(前馈神经网络)进行处理。
FFN 是一个庞大的矩阵,通常认为信息在这里会得到更广泛和深度的处理,并过滤掉信号微弱的特征。这是一个典型的升维再降维过程,升维旨在将信号展开,也可称为稀疏化。
沿用之前的例子,在 FFN 这里,这个包含了“饮酒、暴力、亲子关系”等信息的向量,可能会激活更多的世界知识,例如“父权”、“父子裂痕”等,同时排除一些可能性极低的信息,比如“沏茶帮父亲醒酒”……
这些信息继续通过标准残差连接,附加到上一轮计算得出的向量上。
然后,这个向量被送入下一层,开始新一轮的“注意力机制 + FFN”计算。模型有多少层,这个循环就要进行多少次。
而 HC(超连接),其设计初衷是替代标准的残差连接。标准的残差连接只是简单地将新旧向量相加,向量的维度(长度)保持不变。HC 则将这个简单的加法运算,升级为更复杂的计算。
向量本身的维度会大幅拓宽(例如变为原来的4倍)。那么多出来的维度空间如何填充?我们稍后详述。简单来说,这是一种新旧信息的“混合搅拌”。传统残差连接简单相加的方式可能过于机械,无法充分利用信息。
但实践证明,采用 HC 的架构在训练时非常不稳定。这可能是因为 HC 对信号的放大作用过强。由于残差连接在每一层都会发生,这意味着每次经过注意力或 FFN 计算后,这种“内部信号的搅动”会多次发生。
而 DeepSeek 提出的 mHC,在保持 HC 对向量“扩维”(即拥有比传统架构更大的信息传递容量)优点的同时,对信息增强的幅度施加了限制。具体做法是,将 HC 中残差连接的矩阵约束为一个双随机矩阵(矩阵元素非负,且每行每列的和均为1)。
这意味着,信息容量得以保留,但信号不会随着层层计算而无限制地增强。
当然,前面讨论的是一个已经训练好的模型可能会因 HC 架构而过度放大某些特征。实际上,这样的模型可能根本无法被有效训练出来,因为其信号增强或衰减的趋势过于剧烈,导致训练过程难以调整,异常棘手。
因此,mHC 的作用可以概括为:保留拓宽的特征传递容量,但防止其特征强度失控。
此外,DeepSeek 的研究不限于算法上的改进,他们还进行了工程优化,提升了训练速度并改善了显存利用效率。
为什么要用 HC?
于是,下一个问题自然浮现:为什么要用 HC?
如果说 mHC 是为了解决模型可塑性与稳定性之间的权衡(论文原文:Trade-off between Plasticity and Stability),那么我们需要回到一个更根本的问题:为什么要改变标准的残差连接,转而使用 HC?
一个更个人化的疑问是:为什么需要通过残差连接来解决可塑性问题?直觉上,注意力机制和 FFN 的计算本身就能起到类似效果,它们不断激活各种特征,然后筛除不重要的,保留重要的…… 特别是 FFN,作为一个巨大的神经网络,理应很难“放过”那些该被激活的特征。
一个立刻能想到的答案是:HC 可能提升了模型的性价比。这也是 DeepSeek 一贯的技术路线:以更低的成本训练出高性能模型。
实际上,HC 这一步的计算虽然比标准残差连接复杂,但本质上依然相当简单,因为它几乎完全是线性的矩阵变换。
如前所述,标准残差连接是直接将新旧向量相加。而 HC 则先将旧向量和新向量分开处理:
旧向量的处理方式是被复制成多份(例如4份),每份乘以不同的权重系数,进行等比例的线性变换,然后堆叠起来,形成一个 4 * C 的宽矩阵(即“宽残差流”)。
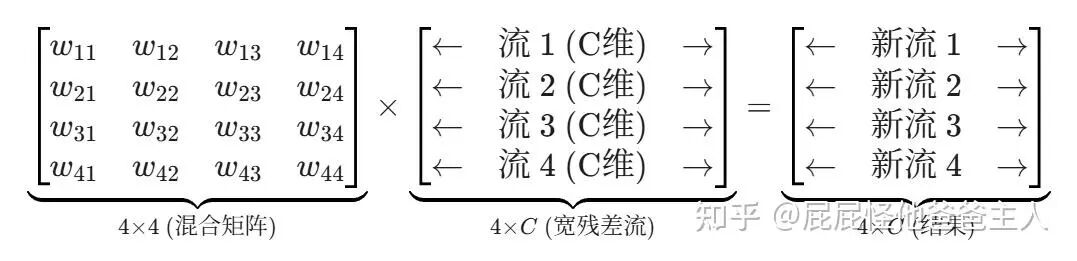
然后,这个宽矩阵会与一个 4 * 4 的权重矩阵相乘,相当于将多份旧特征进行混合,得到一个初步结果。
同时,上一步计算产生的新向量,也可以理解为被“分发”到多份中,通过另一组权重系数计算后,加入到已被混合的旧特征里。
因此,HC 计算出的宽向量可以表示为:(旧向量经特征搅拌) + (新向量经分发) = HC 输出的宽向量。
这个结果就是更新后的宽向量。当它需要被送入下一层的 FFN 或 Attention 进行具体计算时,会先通过一组权重进行加权求和(即“变窄”),提取出最核心的 C 维信息送入计算单元。计算完成后,结果再次被“变宽”,如此循环往复。
可以设想这样一种场景:向量在经过第一层后获得了“父权”特征,经过第二层后获得了“窝里横”特征,而向量本身一直携带着“喝酒”特征。从第二层出来后,“父权”特征主要被分发到流1,“窝里横”特征主要被分发到流2。
通过 HC 的混合与随后的“变窄”操作,这两个新特征与旧特征被汇聚到同一个信息流中,形成了“喝酒+父权+窝里横”的复合语境,这为第三层 FFN 能够激活“撒酒疯”这一特征做好了铺垫。
但理论上,标准残差连接也能携带这些信息,为何还要用 HC 呢?
因为 HC 具备了额外的“调理”或“去噪”能力。HC 相当于在注意力机制和 FFN 处理之后,将信息放置在一个“更大的工作台”上进行一轮附加加工。如前所述,这个“更大工作台”上的加工本质上是不同信息流之间的线性变换(乘法和加法),而标准残差连接只有加法。
加法只能做叠加,而乘法让模型在 HC 这一步也拥有了筛选和重新配比的能力。(可以类比调音台的工作原理)

到这里,我们会发现——HC(特别是 mHC)在功能上很像另一种注意力机制。
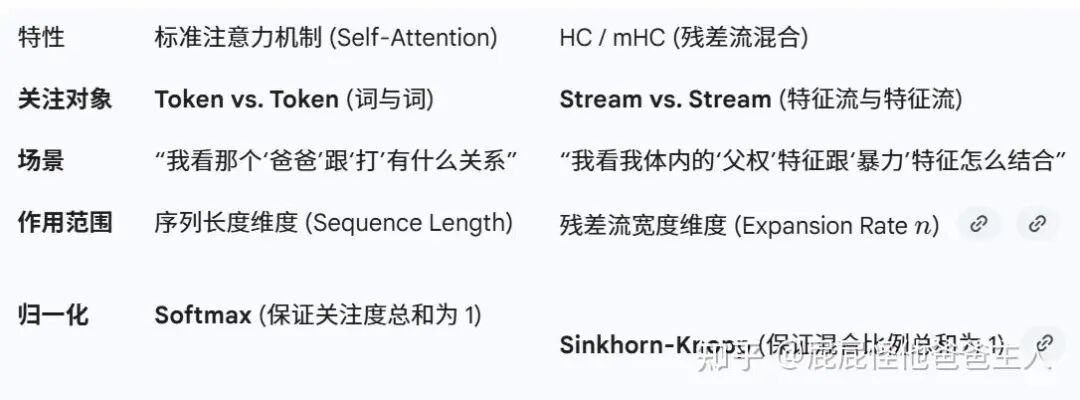
DeepSeek 的 mHC 甚至强化了这种相似性:原始的 HC 是无约束的,而 mHC 加上了双随机约束(行和与列和均为1)。这与注意力机制中通过 Softmax 进行归一化有异曲同工之妙。
不过,与常规的注意力模块不同,HC/mHC 不在序列长度维度做全连接计算,只在残差流的宽度维度进行信息交换。也就是说,同一个流内部的信息不直接混合,不同流之间才进行信息调度。因此,它既起到了类似注意力的调度作用,计算开销又相对较小。
虽然每次可能只有4条流在交换信息,但模型有几十甚至上百层,这种层层叠加带来的组合复杂度是指数级增长的。关键在于,它增加的计算量非常微小。
因此,论文指出了 HC 的核心价值:
“With this design, HC effectively decouples the information capacity of the residual stream from the layer's input dimension, which is strongly correlated with the model's computational complexity (FLOPs).”
(通过这种设计,HC 有效地将残差流的信息容量与层的输入维度解耦,而输入维度与模型的计算复杂度(FLOPs)强相关。)
这意味着,残差流的信息容量可以与计算复杂度分离。信息通道可以变得很宽,以承载更清晰、更解耦的信息,却不会导致计算成本显著上升。这属于计算机基础中架构与性能权衡的经典问题。拓宽残差流不仅是为了携带更多信息,更是为了优化信息的组织方式,这背后涉及深刻的基础 & 综合性设计原则。
论文中的对照实验结果
- 对照组 (Baseline):一个标准的 DeepSeek-V3 架构模型(270亿参数);残差流宽度:C (2560维)。
- 实验组 (mHC):在上述基线模型基础上,引入 mHC;残差流宽度:拓宽为 4C;其他所有配置(FFN宽度、层数、注意力头数等)保持完全一致。
实验结果:
- mHC 模型的训练损失(Loss)显著更低,在下游任务(如数学MATH、代码、逻辑推理BBH)上的得分显著更高。
- mHC 模型的性能曲线始终位于基线模型之上。这表明,为了达到相同的智能水平(相同的 Loss 值),mHC 模型所需的训练计算量更少。
虽然论文没有明确说“可以因此减小 FFN 的规模”,但实验强烈暗示:如果只需要达到基线模型的性能水平,完全可以使用一个参数更少(例如 FFN 更小)、但配备了 mHC 的模型来实现。这正是人工智能领域追求更高效率的体现。这种在模型架构层面的创新与优化,正是技术社区持续关注和探讨的焦点,我们可以在云栈社区找到更多相关的深度讨论与资源共享。
本文基于公开论文《mHC: Manifold-Constrained Hyper-Connections》及授权解读进行整理。
 发表于 2026-1-6 00:38:26
|
查看: 216|
回复: 0
发表于 2026-1-6 00:38:26
|
查看: 216|
回复: 0
