你是否曾遇到这样的情况:明明表上已经创建了合适的索引,但使用 EXPLAIN 分析时,MySQL 优化器却出人意料地选择了全表扫描?这种看似“有路不走”的行为,其背后并非优化器犯了错,而是一位看不见的指挥家——基于一系列内置的成本常数,经过精密计算后做出的“理性”决策。
今天,我们将通过一个真实案例,深入探索 MySQL 优化器的成本计算逻辑,揭开查询优化背后那层神秘的面纱。
1 一个费解的SQL现象
1.1 表结构
首先,我们来看案例中涉及的表结构。
CREATE TABLE `mapping_filter_record` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`source_type` int(11) NOT NULL COMMENT '来源类型',
`source_id` varchar(64) NOT NULL COMMENT '来源方id',
-- ... 其他字段省略
PRIMARY KEY (`id`),
KEY `idx_source_type` (`source_type`, `update_time`) USING BTREE,
KEY `idx_source_id` (`source_id`, `source_type`, `state`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 290240042300201321 DEFAULT CHARSET = utf8mb4 COMMENT = '商品发布拦截记录表';
这张表的主键是 id,并且我们为 source_id 和 source_type 字段建立了联合索引 idx_source_id。
1.2 耗时较久的SQL
在实际业务中,出现了以下执行非常缓慢(超过10秒)的查询语句:
select *
from dbzz_ypofflinemart.mapping_filter_record
WHERE (source_type = 9401003 and source_id = '1814613774586351713')
order by id asc
LIMIT 1;
从查询条件看,它完全匹配了 idx_source_id 索引的前两列,理论上是索引查询的绝佳场景。
1.3 分析执行计划
使用 EXPLAIN 命令查看其执行计划:
explain
select *
from dbzz_ypofflinemart.mapping_filter_record
WHERE (source_type = 9401003 and source_id = '1814613774586351713')
order by id asc
LIMIT 1;
执行计划结果如下:
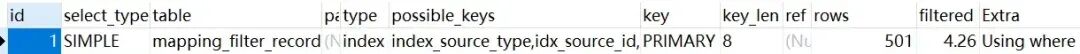
结果令人困惑:优化器没有使用我们预期的 idx_source_id 索引,而是选择了主键索引 (PRIMARY),访问类型为 index,这实质上是一种按索引顺序进行的全表扫描。
1.4 explain的进阶用法
传统的 EXPLAIN 只告诉我们“是什么”,而没有解释“为什么”。此时,EXPLAIN FORMAT=JSON 就派上了用场,它能输出包含成本评估在内的详细信息。
执行 命令1 (未指定索引):
explain format = json
select *
from dbzz_ypofflinemart.mapping_filter_record
WHERE (source_type = 9401003 and source_id = '1814613774586351713')
order by id asc
LIMIT 1;
得到的执行计划1中,query_cost(总查询成本)为 3865.20。
执行 命令2 (强制指定索引):
explain format = json
select *
from dbzz_ypofflinemart.mapping_filter_record
FORCE INDEX(idx_source_id)
WHERE (source_type = 9401003 and source_id = '1814613774586351713')
order by id asc
LIMIT 1;
得到的执行计划2中,query_cost 同样为 3865.20。
1.5 分析执行计划
对比两个执行计划的异同:
| 命令 |
query_cost |
using_filesort |
| 命令1 (使用PRIMARY) |
3865.20 |
false |
| 命令2 (使用idx_source_id) |
3865.20 |
true |
关键点在于:
- 成本相同:优化器计算出使用主键索引和使用
idx_source_id 索引的查询成本完全相同(3865.20)。
- 排序差异:使用主键索引 (
PRIMARY) 可以按索引顺序(id asc)读取数据,无需额外排序 (using_filesort: false)。而使用 idx_source_id 索引查出的记录,其 id 顺序是随机的,需要额外的 filesort 操作 (using_filesort: true)。
因此,在成本相同的情况下,优化器“聪明地”选择了无需额外排序的执行方案,即使用主键索引进行顺序扫描。
2 查询 SQL 语句执行流程
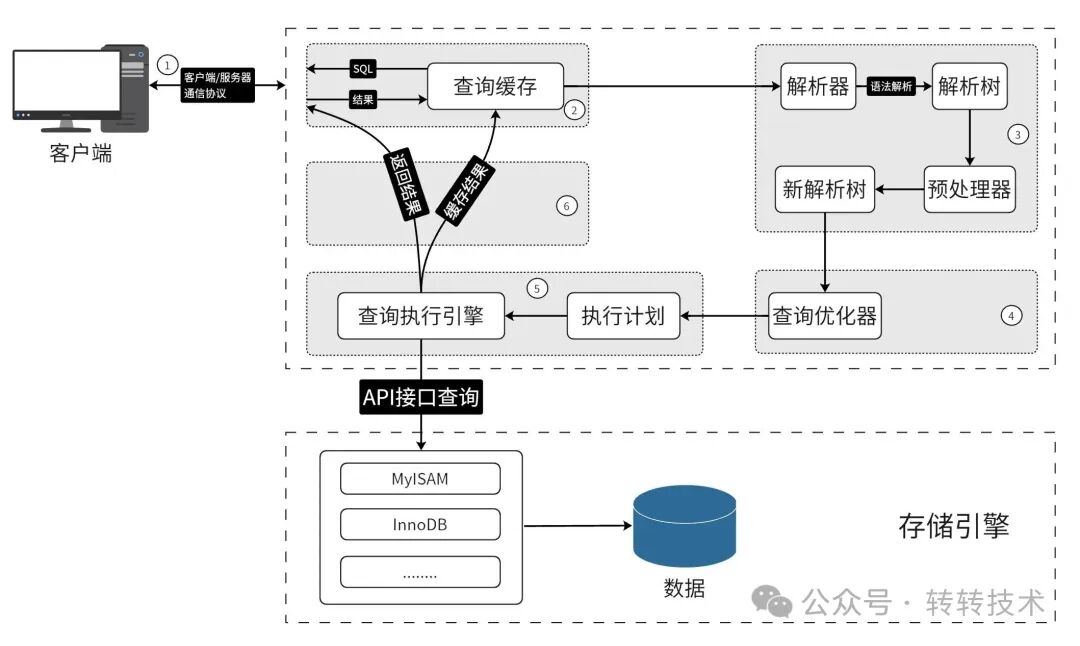
要理解优化器为何如此决策,我们需要了解其工作流程。
2.1 查询优化器
优化器是 MySQL 的大脑,其工作可以简化为四步:
- 解析 SQL:理解查询的意图。
- 生成方案:根据表结构、索引等信息,生成多种可能的执行路径。
- 成本计算:基于内置的成本模型和表的统计信息,估算每条路径的“代价”。
- 选择最优:选择估算成本最低的方案执行。
下图清晰地展示了这个流程:
2.2 执行成本
MySQL 将执行成本分为两大类:
- I/O 成本:将数据或索引从磁盘加载到内存的损耗。对于 InnoDB 存储引擎,一个页(通常16KB)就是一个I/O块。
- CPU 成本:读取记录、检查记录是否满足WHERE条件、对结果集进行排序等操作所消耗的CPU资源。
总执行成本 = I/O 成本 + CPU 成本
2.3 MySQL 5.7 版本的默认成本常数
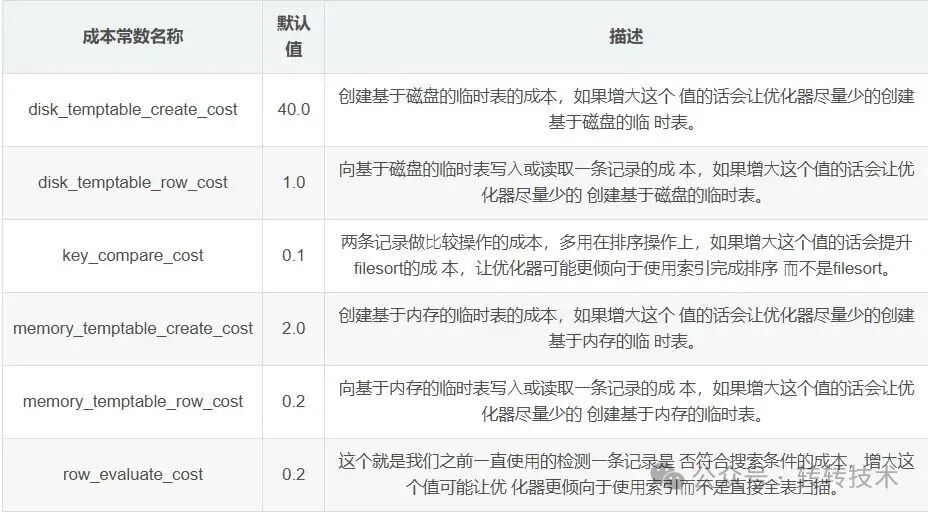
成本常数是优化器用来量化I/O和CPU操作代价的固定值。它们是优化器进行成本计算的基石。
Server层成本常数:
引擎层成本常数:
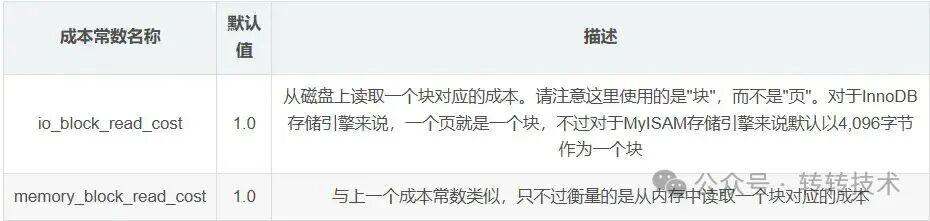
其中,row_evaluate_cost (默认0.2) 是评估一条记录是否符合搜索条件的CPU成本;io_block_read_cost (默认1.0) 是从磁盘读取一个块(页)的I/O成本。
3 执行成本分析
3.1 表统计信息
成本计算严重依赖于表的统计信息。我们可以通过以下命令查看:
show table status like 'mapping_filter_record';
| 关键信息如下: |
Rows |
Avg_row_length |
Data_length |
Index_length |
| 1,615,460 |
9396 |
~14.1GB |
~527MB |
3.2 命令2 (指定索引) 的执行成本分析
命令2的执行路径是经典的“回表查询”:
- 在
idx_source_id 索引树中定位到符合条件的记录,取得对应的主键 id。
- 根据这些
id 回到聚簇索引(主键索引)中查找完整的行数据。
这个过程如下图所示:
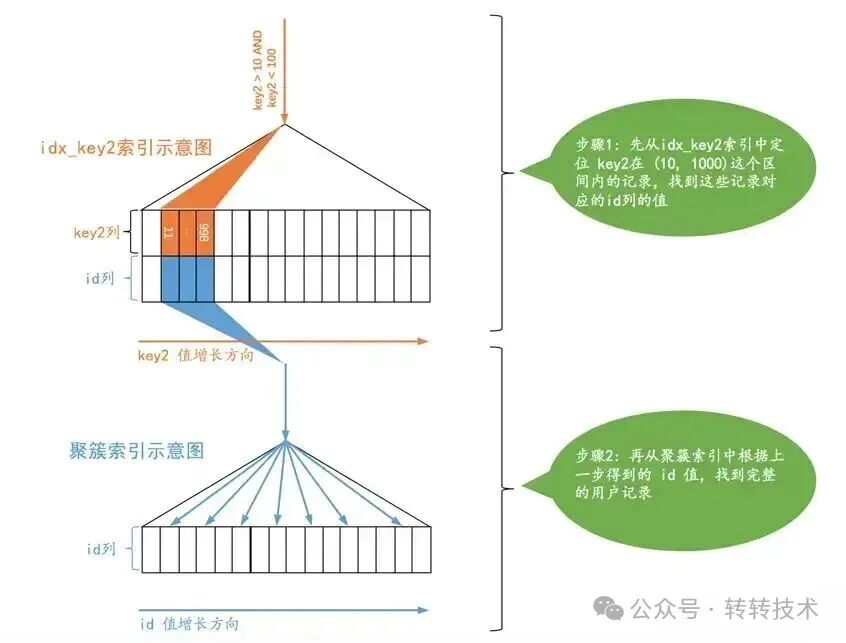
从执行计划2可知,通过 idx_source_id 索引预计需要扫描 3221 行。成本计算如下:
- 索引扫描成本:定位索引代价极小,可忽略。
- 回表I/O成本:3221行 × 1.0 (
io_block_read_cost) = 3221.0
- 回表CPU成本:3221行 × 0.2 (
row_evaluate_cost) = 644.2
- 总成本 ≈ 3221.0 + 644.2 = 3865.2
计算结果与执行计划中的 3865.20 完全吻合。
3.3 命令1 (未指定索引) 的执行成本分析
问题来了:全表扫描超过160万行,成本怎么可能和仅扫描3221行的回表查询一样呢?
观察执行计划1,我们发现了一个关键数字:rows_examined_per_scan (扫描行数) 是 501,而非全表的161万。
依据1:实验数据
通过改变 LIMIT 子句的值进行测试,得到以下现象: |
执行语句 |
使用的索引 |
扫描行数 |
实际执行时间 |
... LIMIT 1; |
PRIMARY |
501 |
19.4秒 |
... LIMIT 2; |
PRIMARY |
1003 |
20.2秒 |
... LIMIT 6; |
PRIMARY |
3009 |
20.24秒 |
... LIMIT 7; |
idx_source_id |
3221 |
0.026秒 |
依据2:数据分布估算
表中总数据 1,615,460 条,而符合 WHERE 条件的数据共 3,221 条。1,615,460 ÷ 3,221 ≈ 501。
推断与解释
优化器在这里做了一个关键假设:数据是均匀分布的。基于此,它推断“每顺序扫描大约501条主键索引记录,就能找到1条满足条件的数据”。由于查询只需要1条结果 (LIMIT 1),优化器认为只需要扫描约501行即可。
因此,它的成本计算基于 501 行,而非全表行数:
- 全表扫描I/O成本:501行 × 1.0 = 501.0
- 全表扫描CPU成本:501行 × 0.2 = 100.2
- 总成本 ≈ 501.0 + 100.2 = 601.2 (但这并非最终成本)
实际上,优化器在比较两种方案的成本时,对于 LIMIT 查询,它会取两种方案扫描行数的较小值作为成本计算依据。在本例中,它最终使用了 idx_source_id 方案的扫描行数 3221 作为成本计算基准,因此得出了与命令2相同的成本 3865.2。在成本相同的情况下,无需排序的主键扫描方案自然胜出。
注意:以上是基于 MySQL 5.7 版本特定场景下的行为分析,旨在揭示优化器的思考逻辑,并非所有版本的绝对行为准则。
4 优化
尽管优化器的选择有其数学模型支撑,但在我们的业务场景中,符合条件的数据并非均匀分布,而是大量集中在表的尾部。这导致“扫描501行找到数据”的乐观估计完全落空,实际执行时需要扫描近百万行,造成严重性能问题。
优化思路是“引导”优化器做出正确选择。本例采用子查询进行优化:
SELECT *
FROM mapping_filter_record
WHERE id = (
SELECT id
FROM mapping_filter_record
WHERE source_type = 9401003 AND source_id = '1814613774586351713'
ORDER BY id ASC
LIMIT 1
);
在这个写法中,内层子查询明确地通过高效索引 (idx_source_id) 快速找到目标 id,外层查询再通过主键精准定位。这有效避免了优化器因成本误判而选择全表扫描。
5 总结
这个案例深刻地揭示了以下几点:
- MySQL 优化器是基于成本的决策者,而非“智能”到能感知真实数据分布的上帝。
- 成本常数和统计信息是决策的核心依据,统计信息的准确性(如数据分布)直接影响优化效果。
- 理解成本模型是高级优化的钥匙,当优化器选择不符合预期时,成本分析是指引我们找到根源和解决方案的明灯。
通过对 MySQL 优化器工作原理的深入理解,我们才能更从容地设计索引、编写SQL,最终提升数据库的整体性能。你是否也在项目中遇到过其他令人费解的“索引失效”场景?欢迎在云栈社区与我们分享你的经验和见解。
 发表于 2026-1-6 01:03:22
|
查看: 156|
回复: 0
发表于 2026-1-6 01:03:22
|
查看: 156|
回复: 0
