一、为什么研究这个问题?
在系统设计学习中,一个常见的困境是:日常工作比较零散,难以接触到宏观的系统层面,但面试和高级职位又非常看重系统设计能力。如何开始学习并实践系统级的优化设计?
一个有效的途径是:阅读顶级学术会议的前沿论文。论文公开了业界最顶尖团队如何解决最棘手性能问题的完整思路与设计方案。
正如阿姆达尔定律所揭示的:只优化系统的一部分效果有限,整体性能总被最慢的环节限制,必须进行全面、协同的升级才能实现系统性突破。全栈优化不是简单叠加模块,而是重新设计各层交互,以实现整体大于部分之和。
一篇来自VLDB 2023的论文《What Modern NVMe Storage Can Do, And How To Exploit It: High-Performance I/O for High-Performance Storage Engines》正是这样一个绝佳的研究案例。
该论文由慕尼黑工业大学的Viktor Leis、Tobias Ziegler等学者撰写,他们长期深耕于数据库系统、存储引擎以及NVMe/PCIe性能优化领域,其代表性的LeanStore系列工作聚焦于在NVMe SSD上实现高效的I/O与极致的系统可扩展性。这篇论文的核心,正是探讨在现代NVMe SSD硬件上,如何通过I/O路径与存储引擎的协同设计,充分释放设备的高并发、低延迟与高带宽能力。
二、论文解决了哪些核心问题?
论文清晰地定义了六个核心问题(Q1-Q6)并给出了经过实验验证的答案,这为我们理解高性能存储系统设计提供了清晰的路线图。
| 问题编号 |
研究问题 |
核心解答与发现 |
| Q1 |
NVMe阵列能否达到硬件标称的性能? |
可以,甚至能超越。 实验证实,8块NVMe SSD组成的阵列能够实现1250万次/秒的随机读取IOPS,超过了单个硬盘标称性能的简单叠加。 |
| Q2 |
应该使用哪种I/O API?是否需要内核旁路(如SPDK)? |
1. 所有异步接口(libaio, io_uring, SPDK)都能实现高吞吐。 2. 内核旁路(SPDK)在CPU效率上具有绝对优势,但io_uring在轮询模式下也能接近其性能。对于追求极致效率的场景,SPDK是最佳选择。 |
| Q3 |
存储引擎应使用多大的页大小,才能在获得高性能的同时最小化I/O放大? |
4 KB是最佳权衡点。 这是NVMe SSD随机读取性能的“甜点”,能同时优化IOPS、带宽和延迟。小于4KB会因硬件限制导致性能下降,大于4KB则会造成严重的I/O放大。 |
| Q4 |
如何管理实现高SSD吞吐所需的高并发度? |
必须采用用户态协作式多任务(轻量级线程)。 传统“一个查询一个内核线程”的模型会导致数千线程的过度订阅和巨大开销。论文通过用户态任务调度,使少量工作线程能高效管理海量并发的I/O请求。 |
| Q5 |
如何让存储引擎足够快,以管理每秒数千万的IOPS? |
内存外(Out-of-Memory)的代码路径必须进行深度优化和并行化。 这包括:采用分区锁消除热点、优化淘汰算法(如引入乐观父指针)、移除内存分配、以及微调热代码路径,确保CPU不会成为瓶颈。 |
| Q6 |
I/O应由专用的I/O线程执行,还是由每个工作线程执行? |
应由工作线程直接执行(All-to-All模型)。 论文否定了专用I/O线程或SSD绑定的模型,采用对称设计:每个工作线程拥有通往所有SSD的独立I/O通道,无需线程间通信。这简化了设计,并实现了最佳的可扩展性。 |
三、深入解析:从问题到架构与实现
3.1 为什么CPU会成为新的瓶颈?
长久以来,I/O一直被认为是系统的慢速部件。因此,在多数系统中,I/O路径的优化往往不如内存部分充分。然而,一旦系统能够调度数百万乃至数千万的IOPS时,处理这些I/O请求的CPU开销就变得不可忽视,CPU反而常常成为新的性能瓶颈。
想象一个高速收费站:
- 旧系统(机械硬盘):车流稀疏 → 收费站空闲
- 新系统(NVMe SSD):车流如潮 → 收费站拥堵
具体开销包括:
- 每个I/O请求需要约1000-5000 CPU周期
- 用户态与内核态之间的上下文切换
- 中断处理开销
- 内存拷贝操作
- 锁竞争与同步
全局锁问题:在早期的设计中,可能使用一个全局锁来保护I/O操作和缓冲区管理。当I/O延迟在毫秒级时,锁的开销占比很小。但当NVMe SSD将I/O延迟降至微秒级,系统每秒处理千万级请求时,全局锁的争用会急剧上升,从微不足道的开销演变为严重的性能瓶颈。
页面淘汰算法:页面淘汰是关键的后台任务。如果页面替换算法太慢,导致系统耗尽空闲页面,整个系统就会停滞。管理每秒数千万次IOPS的工作负载,要求淘汰算法也必须能以极高的速率(每秒数千万页)运行,这对CPU计算和数据结构设计提出了严峻挑战。
3.2 如何解决:将CPU瓶颈转回I/O瓶颈
论文的核心思想是重新设计系统架构,通过极致的CPU效率来驱动I/O硬件达到其性能极限。其解决方案可以概括为三个关键图表所揭示的层次:问题定义 → 整体架构 → 关键实现。
| 特性 |
图7(问题定义) |
图8(架构方案) |
图10(实现模型) |
| 核心内容 |
定义性能目标与矛盾:高并发I/O需求 vs. 有限CPU核心。 |
提出系统级解决方案:用协作式多任务集成I/O处理,消除专用I/O线程。 |
选择最优I/O连接模型:全对全模型,实现无锁、直接的硬件访问。 |
| I/O处理角色 |
指出I/O必须达到高并发(>1000未完成请求) 才能利用SSD性能。 |
规定I/O是工作线程的核心职责之一,与任务执行、页面淘汰集成。 |
规定I/O通过工作线程专属的I/O通道直接进行,无需线程间协调。 |
| 关键贡献 |
揭示了传统同步I/O/多线程架构的根本性不足(线程过度订阅)。 |
提供了管理海量I/O请求的CPU高效方法(用户空间任务,极低切换开销)。 |
提供了与SSD硬件通信的最高效路径(全对全模型,消除通信开销)。 |
| 关系 |
为什么需要新设计(传统方法无法满足并行性要求)。 |
整体上如何做(用协作式多任务架构管理I/O)。 |
具体如何做(用全对All I/O模型实现高效硬件交互)。 |
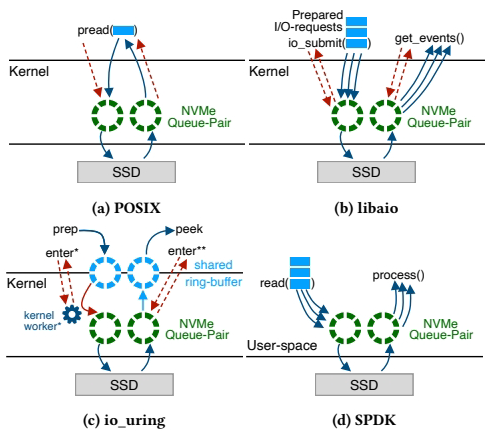
因此,传统方式与论文方式的根本区别在于:
- 传统方式:每个查询使用一个OS线程,采用同步阻塞I/O(如
pread)。线程在I/O时被阻塞,需要数千个线程来产生足够并发I/O,导致极端过度订阅和巨大的上下文切换开销。
- 论文方式:少量工作线程运行异步非阻塞I/O。每个线程管理大量用户空间任务,任务在I/O时主动让出CPU;线程通过专属I/O通道直接、异步地向所有SSD提交和轮询I/O。这实现了用少量CPU核心高效管理海量并发I/O,最终达到硬件极限性能。
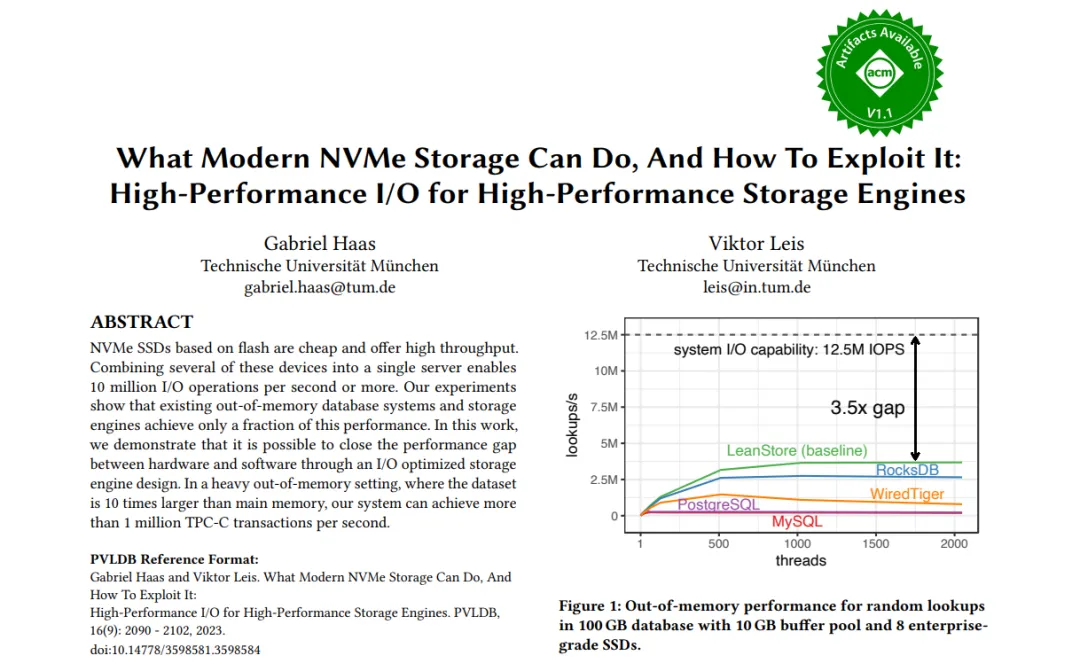
图7:设计概览(揭示并行性矛盾)
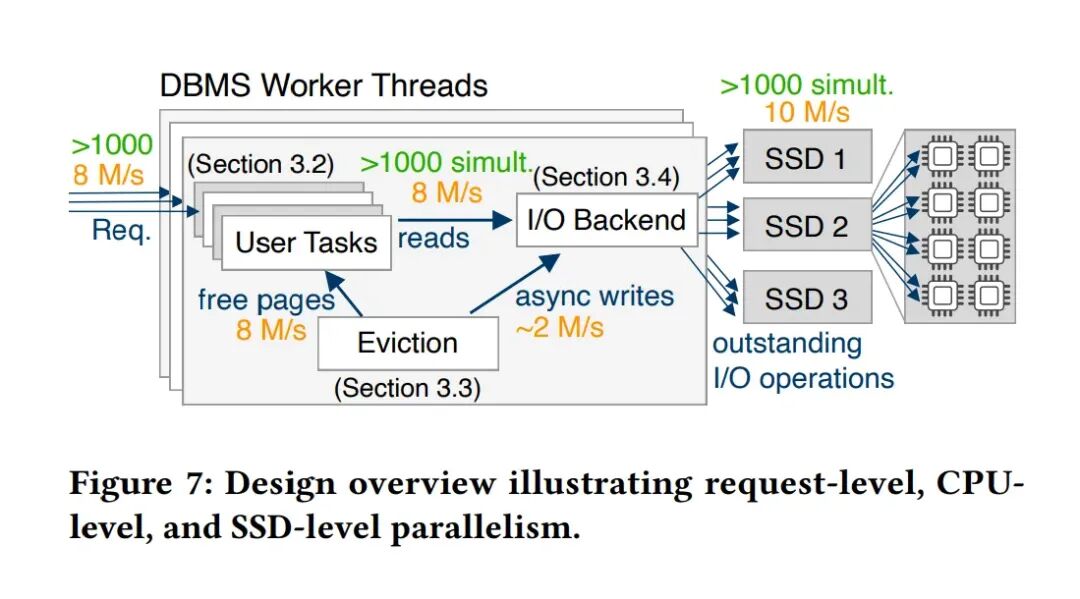
Figure 7的核心是阐明一个高性能存储引擎必须同时有效管理三种并行性:
- 请求级并行性:系统需要同时处理大量并发的用户查询。在内存外场景下,每个查询都可能触发多个I/O,系统必须能管理成千上万个并发I/O请求以保持高吞吐。
- CPU级并行性:现代服务器拥有数十至数百个CPU核心。软件必须有效利用所有核心。传统“一个查询一线程”模型需要数千线程来保持SSD繁忙,导致极端过度订阅和巨大的上下文切换开销。
- SSD级并行性:为充分利用NVMe SSD内部并行性,需要保持超过1000个未完成的I/O请求(高队列深度)才能使SSD阵列保持繁忙。
根本矛盾:硬件(SSD)需要极高并发度,但传统软件模型(同步阻塞I/O+OS线程)为满足此并发度,需要创建远超CPU核心数的线程,导致CPU时间浪费在上下文切换而非实际工作上。
图8:整体架构(协作式多任务解决方案)
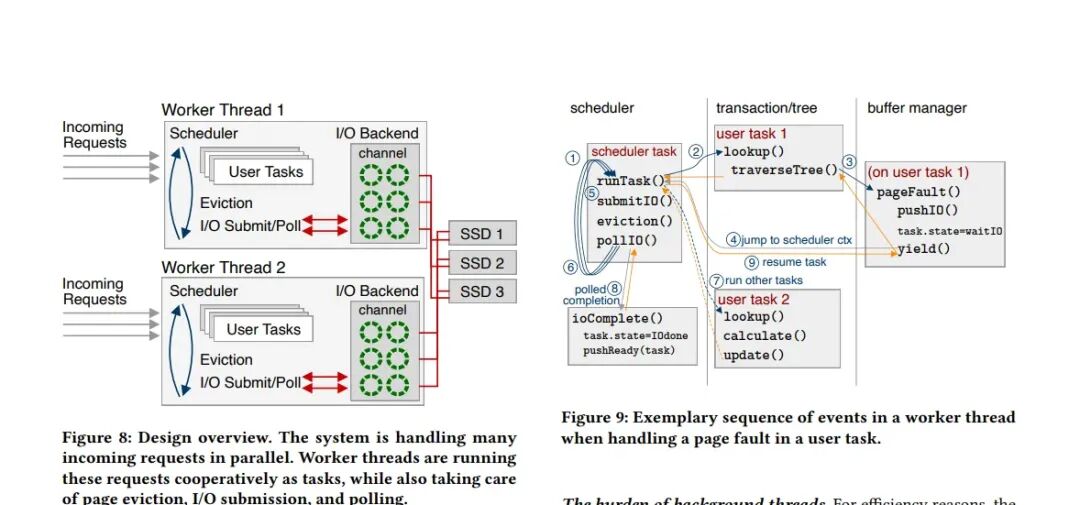
图8展示了解决图7矛盾的整体架构:用户空间协作式多任务处理。
- 工作线程:系统启动与CPU核心数相等的工作线程。每个工作线程内部运行一个轻量级调度器,管理海量用户空间任务(协程)。这些线程身兼多职:执行用户查询、处理页面淘汰、提交I/O、轮询I/O完成。
- 协作式执行流程:
- 用户任务(如B树查找)遇到页错误。
- 调用异步I/O接口提交请求,任务状态设为“等待I/O”,然后主动让出(yield) CPU给调度器。
- 调度器转而执行其他就绪任务,或执行页面淘汰等系统任务,或轮询I/O完成事件。
- I/O完成后,回调函数将任务状态设为“I/O完成”,并放入就绪队列。
- 调度器在后续调度中恢复该任务执行。
- 优势:任务切换成本极低(~20周期),避免了OS线程上下文切换的数千周期开销。用少量核心即可管理海量并发请求,并将后台任务(如淘汰)集成到同一调度框架,简化了系统设计。
图10:I/O模型比较(全对全连接实现)
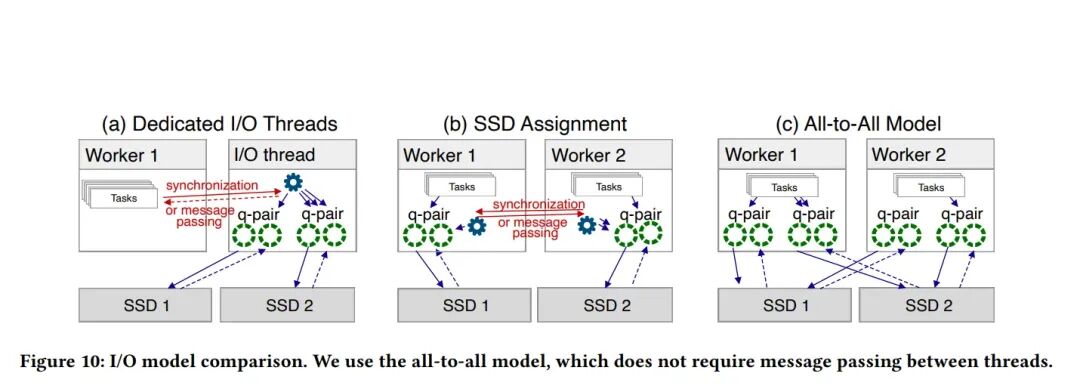
图10解决了“工作线程如何高效连接SSD硬件”这一具体问题,对比了三种模型,并选择了全对全模型(All-to-All)。
- (a) 专用I/O线程模型:工作线程需通过消息传递将I/O请求交给专用I/O线程处理。问题:I/O线程成为瓶颈,线程间通信开销大。
- (b) SSD分配模型:每个SSD被分配给特定线程,访问其他SSD需线程间通信。问题:引入了跨线程通信复杂性。
- (c) 全对全模型(论文采用):每个工作线程都能直接访问所有SSD,拥有自己到每个SSD的独立I/O通道(如NVMe队列对)。无需任何线程间消息传递或同步。
全对全模型的I/O流程:
- 工作线程中的任务通过本线程的专属I/O通道直接提交异步I/O请求到目标SSD。
- 工作线程定期轮询本线程的I/O通道的完成队列。
- I/O完成后,通道回调通知该工作线程,后者更新任务状态。
全对全模型优势:
- 无消息传递:彻底消除线程间协调开销。
- 对称性:所有工作线程结构一致,职责相同。
- 高效可扩展:无通信开销,线性扩展到所有CPU核心。
- 简单健壮:编程模型更清晰。
总结:三图关系
- 图7(挑战):说明了“我们需要处理海量并行请求、有限CPU核心和需要上千个并发I/O”这个难题。
- 图8(架构):给出了答案:“让每个CPU核心上的工作线程通过协作式任务处理所有事情(查询、淘汰、I/O)”。
- 图10(实现):解决了图8方案的关键子问题:“如何让每个工作线程高效访问所有SSD?”答案是:“采用全对全I/O模型,让每个线程拥有到所有SSD的直接通道,避免线程间通信。”
图8与图10是互补关系。图8的“工作线程负责一切”的架构,必然要求图10的“全对全”I/O模型作为高效实现的基础。
四、效果验证
通过上述一系列针对线程模型、I/O路径和存储引擎的协同优化,论文实现的存储引擎(LeanStore)在性能上取得了显著突破。
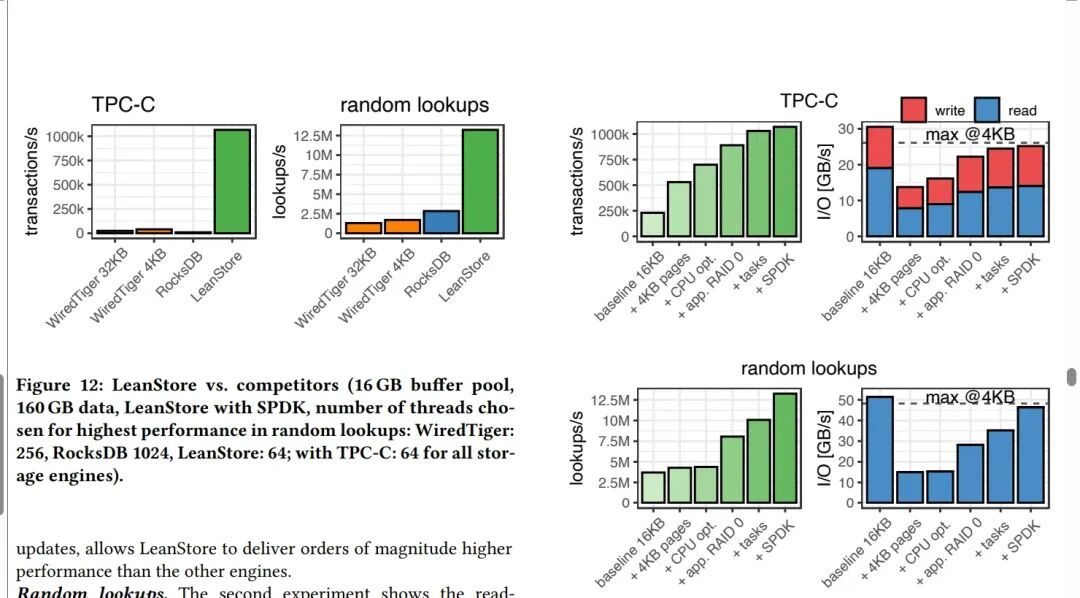
实验结果表明,在高并发场景下,尤其是在数据集远大于内存(Out-of-Memory)的设置中,优化后的系统能够充分发挥现代NVMe SSD阵列的硬件潜力,实现每秒超过百万次的TPC-C事务处理,远超其他现有存储引擎。
这项研究深刻揭示,面对现代高速存储硬件,数据库系统与存储引擎的设计必须进行范式转移。从粗粒度的OS线程调度转向精细化的用户态协作式任务调度,从同步阻塞I/O转向异步非阻塞I/O,并从集中式或分区式的I/O管理转向对称的全对全直接访问,是释放硬件性能、构建下一代高性能系统设计的关键。
对于希望深入理解高性能系统设计和底层优化的开发者来说,这篇论文提供了一个绝佳的蓝图。其思想不仅适用于数据库存储引擎,对文件系统、缓存系统等任何需要极致I/O性能的场景都有极高的参考价值。在云栈社区,你可以找到更多关于系统架构、性能优化和前沿技术的深度讨论与资源分享。
 发表于 2026-1-6 03:33:50
|
查看: 185|
回复: 0
发表于 2026-1-6 03:33:50
|
查看: 185|
回复: 0
