L8.院士
5643
0
741
本文介绍了 Zalando 如何通过引入路由服务器(RouteSRV)帮助 Skipper Ingress 应对高速增长的流量,以更有效管理控制平面并确保集群稳定运行的实践。原文:Scaling Beyond Limits: Harnessing Route Server for a Stable Cluster [1]。
在 Zalando,我们曾面临严峻挑战:传统的入口控制器有可能使 Kubernetes 集群不堪重负。我们需要一种能够应对流量指数级增长、并实现高效扩展的解决方案。本文将详细介绍我们如何引入一个路由服务器,以更有效地管理控制平面流量,从而确保整个集群稳定运行的实践经验。
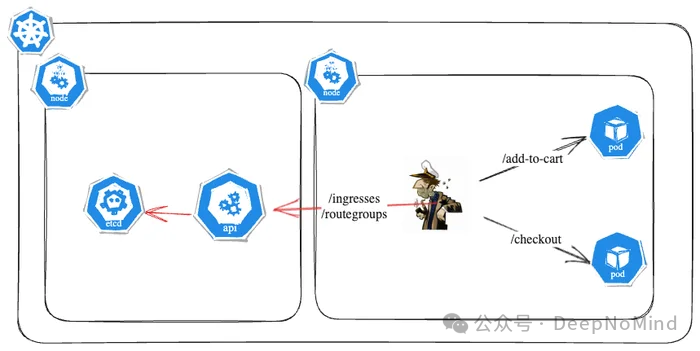
我们使用 Skipper [2](一个 HTTP 反向代理)来实现 Kubernetes Ingress [3] 和 RouteGroups [4] 的控制平面与数据平面。
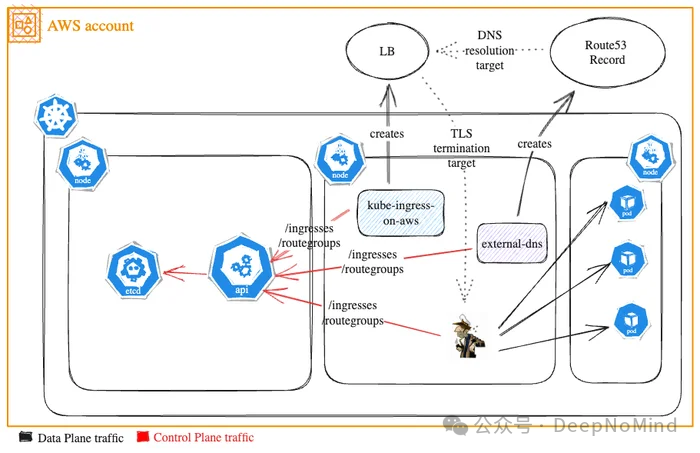
具体来说,创建一个 Ingress 或 RouteGroup 资源会触发以下流程:
Ingress
RouteGroup
为了让你更直观地了解我们的部署环境规模,以下是一些关键数据:
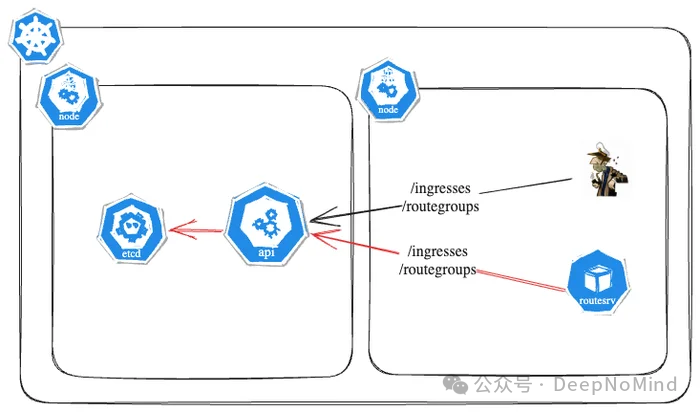
最初,每个 Skipper 实例都直接从 Kubernetes API 获取 Ingress 和 RouteGroups 信息。这种方式在早期运行良好,但随着业务增长,Skipper 实例的数量迅速膨胀,达到每个集群约 180 个,开始超出后端 etcd 基础设施的承载能力。
这种过重的负载直接导致了严重的 Kubernetes API CPU 限流问题,从而引发了关键的控制平面稳定性风险。主要表现为两种后果:集群失去了有效调度新 Pod 的能力,同时现有 Pod 的管理操作也开始出现故障。这些问题直接威胁到了整个 Kubernetes 基础设施的整体稳定性和可靠性。
在引入路由服务器之前,每个 Skipper 都需要独立完成以下四项工作:
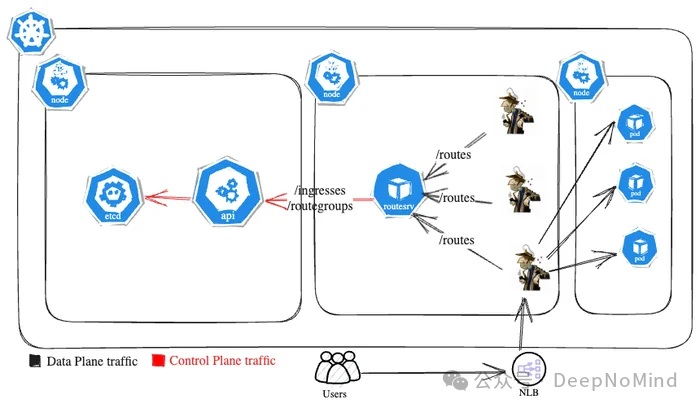
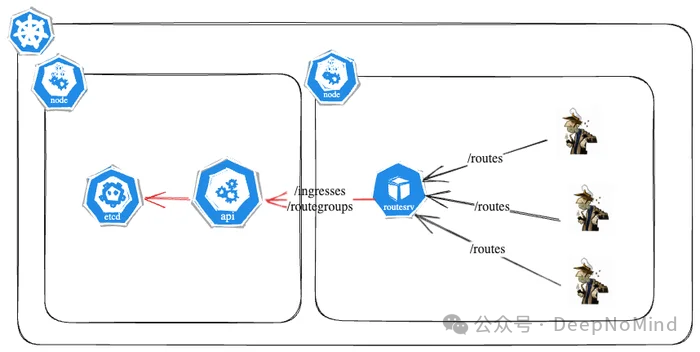
为了解决上述痛点,我们引入了路由服务器(Route Server) [9] 作为自定义的代理层。它的核心作用是更高效地处理控制平面流量,在 Skipper 与 Kubernetes API 服务器之间,充当一个带有 HTTP ETag 缓存层 [10] 的智能代理。
现在,路由服务器统一负责执行轮询和解析操作,极大减轻了每个 Skipper 实例的计算负担,同时实现了清晰的职责分离。
路由服务器的工作流程如下:它每隔 3 秒向 Kubernetes API 发送一次请求,以获取最新的 Ingress 和 RouteGroup 列表。然后,它会根据这些信息生成统一的路由表,并计算出一个对应的 ETag 值。
当 Skipper 向路由服务器请求更新时,会在请求头中附带自己当前持有的 ETag。如果这个 ETag 与路由服务器当前计算出的 ETag 相匹配,就意味着路由信息没有发生变化。此时,路由服务器会以一个轻量的 HTTP 304 (Not Modified) 状态码 [11] 进行响应,避免了不必要的数据传输。反之,如果 ETag 不同,路由服务器就会将全新的路由表发送给 Skipper,Skipper 随后更新其本地配置和 ETag。
尽管路由服务器极大地提高了系统效率,但我们也必须考虑其可能出现的故障场景。当路由服务器不可用时,主要有两种情况:
对于第一种情况,如果启用了 -wait-first-route-load 标志 [12],Skipper 容器将无法启动。在第二种情况下,Skipper 会降级为继续使用最后已知的有效路由表。这是一种在服务可用性和数据强一致性之间做出的权衡。
-wait-first-route-load
在这两种情况下,运维团队都会收到告警。我们需要根据情况决策:是修复路由服务器,还是临时禁用它,让 Skipper 回退到直接访问 Kubernetes API 的旧模式。目前,我们尚未实现自动回退机制。
集成路由服务器后的最终架构与数据流向如下图所示:
部署路由服务器绝非易事。哪怕出现一个微小错误,也可能导致 Kubernetes API 与所有 Skipper 实例的连接中断,从而直接影响线上服务的可用性,甚至冲击销售业绩和商品交易总额(GMV)。因此,我们必须极其谨慎,并遵循一套完善的渐进式部署策略。
我们的计划是以可控的方式逐步推进:首先在测试集群中部署,生产集群则被划分为不同的优先级层级。路由服务器将逐层部署,每完成一层的部署,都会进行严格的监控和观察,确认无误后再进行下一层。
为了实现这一精细化的部署控制,我们为路由服务器设计了三种不同的运行模式,并通过配置项 [13] 进行切换:
默认模式为 false,意味着路由服务器被禁用,Skipper 仍使用原有的、直接访问 Kubernetes API 的控制平面通信方式。
false
在该模式下,路由服务器会与 Skipper 并行工作。它会从 Kubernetes API 获取 Ingress 和 RouteGroup,并进行预处理,生成自己的路由表。此模式主要用于测试、调试,也是我们分阶段上线策略的核心。
关键操作在于对比验证:我们同时获取 Skipper 自己生成的路由表和路由服务器生成的路由表,并进行逐项比对,以确保路由服务器的处理逻辑完全正确,没有任何路由差异。要知道,任何细微的路由表偏差都可能导致服务中断,这就是为什么我们必须如此谨慎。
# 使用一个极大的 limit 参数获取所有 Skipper 实例的路由 curl -i http://127.0.0.1:9911/routes\?limit\=10000000000000\&nopretty > skipper_routes.eskip # 获取路由服务器的所有路由(我们决定不使用分页以减少请求数,因为Skipper是目前唯一的消费者) curl -i http://127.0.0.1:9090/routes > routesrv_routes.eskip # 使用 git diff 对比两个文件,确保内容完全一致 git diff --no-index -- skipper_routes.eskip routesrv_routes.eskip
这是用于生产环境的最终模式。在该模式下,路由服务器正式成为 Skipper 与 Kubernetes API 之间的唯一代理。Skipper 的所有控制平面请求都发送给路由服务器,由路由服务器转发至 Kubernetes API。路由服务器会缓存响应,并利用 ETag 机制高效地返回给 Skipper。
在经过全面的负载测试和预处理模式下的长期验证后,我们以高度可控的方式将路由服务器推向了生产环境:
在方案选型时,我们曾考虑使用 Kubernetes Informer [14] 来监听 Kubernetes API 的资源变化,这是一种在 K8s 生态中常见的模式。然而,经过分析,我们认为这种方法本质上仍需要 Kubernetes API 向所有订阅的 Skipper 实例广播变更事件,这很可能导致我们最初遇到的相同问题——流量洪峰。问题的核心在于突发流量可能超出 HPA(水平自动伸缩)对 Kubernetes API 和 etcd 的扩展速度。
通过引入路由服务器,我们取得了显著的成果:
参考资料 [1] Scaling Beyond Limits: Harnessing Route Server for a Stable Cluster: https://engineering.zalando.com/posts/2025/02/scaling-beyond-limits-harnessing-route-server-for-a-stable-cluster.html [2] Skipper: https://opensource.zalando.com/skipper [3] Kubernetes Ingress: https://kubernetes.io/docs/concepts/services-networking/ingress [4] RouteGroups: https://opensource.zalando.com/skipper/kubernetes/routegroup-crd [5] 带有 TLS 终止功能的 AWS LB: https://engineering.zalando.com/posts/2025/02/scaling-beyond-limits-harnessing-route-server-for-a-stable-cluster.html#fn:1 [6] kube-ingress-aws-controller: https://github.com/zalando-incubator/kube-ingress-aws-controller [7] external-dns: https://github.com/kubernetes-sigs/external-dns [8] Eskip: https://engineering.zalando.com/posts/2025/02/scaling-beyond-limits-harnessing-route-server-for-a-stable-cluster.html#fn:2 [9] 路由服务器: https://pkg.go.dev/github.com/zalando/skipper/routesrv [10] HTTP ETag 缓存层: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/ETag [11] HTTP 304 (Not Modified) 状态码: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/304 [12] -wait-first-route-load 标志: https://github.com/zalando-incubator/kubernetes-on-aws/blob/4f2e04e3e056ba6c647d85e64fd842ada44deff3/cluster/manifests/skipper/deployment.yaml#L171 [13] 配置项: https://github.com/zalando-incubator/kubernetes-on-aws/blob/32658df25ee29049d5495cf422f85ab536b599bb/cluster/config-defaults.yaml#L223 [14] Kubernetes Informer: https://pkg.go.dev/k8s.io/client-go/informers
本文分享了 Zalando 在超大规模 Kubernetes 集群中优化 Ingress 控制平面的实战经验。更多关于云原生架构和系统设计的深度讨论,欢迎访问云栈社区进行交流。
收藏0回复 显示全部楼层 举报
发表回复 回帖后跳转到最后一页
手机版|小黑屋|网站地图|云栈社区 ( 苏ICP备2022046150号-2 )
GMT+8, 2026-7-12 09:57 , Processed in 0.740457 second(s), 42 queries , Gzip On.
Powered by Discuz! X3.5
© 2025-2026 云栈社区.
 发表于 2026-1-6 04:09:51
|
查看: 273|
回复: 0
发表于 2026-1-6 04:09:51
|
查看: 273|
回复: 0