今天我们来深入探讨InnoDB存储引擎中三种精细化的行级锁:记录锁、间隙锁和临键锁。理解这些锁机制,是掌握MySQL高并发和事务隔离级别的关键。在云栈社区的技术论坛中,这也是一个常见且深入的讨论主题。
MySQL的InnoDB引擎最吸引人的特性之一便是其细粒度的行锁机制,而这些锁是实现在索引记录上的。因此,要彻底理解锁,必须先了解InnoDB的索引结构。
一、InnoDB的索引基础
InnoDB的索引主要分为两类:聚集索引(Clustered Index)与普通索引(Secondary Index)。
每个InnoDB表都必然有一个聚集索引:
- 如果表定义了主键(PK),则PK就是聚集索引;
- 如果表没有定义PK,则第一个非空的唯一索引(unique)列是聚集索引;
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引。
为了方便说明,后文都将以主键(PK)为例进行阐述。
索引的结构是B+树,这里我们不深入B+树的细节,仅列出几个关键结论:
- 在B+树索引结构中,非叶子节点存储键值(key),叶子节点存储数据(value)。
- 聚集索引的叶子节点直接存储完整的行记录(row)。这也是InnoDB与MyISAM的一个重要区别:InnoDB的索引和数据是存储在一起的,而MyISAM的索引和数据文件是分离的。
- 普通索引的叶子节点存储的是对应记录的主键(PK)值。这意味着,通过普通索引查询时,InnoDB需要扫描两遍索引树:第一遍在普通索引上找到主键值,第二遍用这个主键值回到聚集索引中找到完整的行记录。
举个例子,假设有InnoDB表:
t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
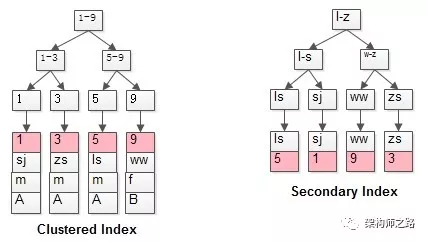
从上图可以看到:
- 左边的聚簇索引(以id为键),其叶子节点存储了所有的行记录数据。
- 右边的二级索引(以name为键),其叶子节点仅存储了对应记录的主键id值。
当我们执行查询 select * from t where name=‘shenjian’; 时:
- 首先在
name的普通索引树上找到 name=‘shenjian’ 的索引项,得到其PK值为 1。
- 然后在
id的聚集索引树上,使用 PK=1 找到完整的行记录 (1, shenjian, m, A)。
下文将基于这个索引知识,详细介绍InnoDB的三种行锁。为了方便讲述,如无特殊说明,后文默认的事务隔离级别为可重复读(Repeated Read, RR)。
二、记录锁 (Record Locks)
记录锁,顾名思义,它封锁索引记录。
例如:
select * from t where id=1 for update;
这条语句会在 id=1 这条索引记录上加一把排他锁(X锁),以阻止其他事务对 id=1 的这一行记录进行插入、更新或删除。
需要注意的是:select * from t where id=1;(不带 for update)属于快照读(SnapShot Read),它利用多版本并发控制(MVCC)机制读取数据,并不加锁。
三、间隙锁 (Gap Locks)
间隙锁,它封锁的是索引记录之间的间隔,或者第一条索引记录之前的范围,又或者最后一条索引记录之后的范围。其主要目的是为了防止其他事务在间隔中插入数据,从而在可重复读隔离级别下避免“幻读”现象。
依然使用上面的例子,表 t 中的数据为 (1, 3, 5, 9)。
执行如下SQL:
select * from t
where id between 8 and 15
for update;
这个查询条件 id between 8 and 15,在当前数据集中并不存在满足条件的记录(id=9 在区间内,但不符合 between 8 and 15 吗?不,9 在 8 和 15 之间,是符合条件的。这里原作者举例可能意在说明一个不存在的区间,我们根据逻辑修正一下)。实际上,由于 id=9 已存在,这个 for update 语句除了会给 id=9 的记录加上记录锁,还会在 (5, 9) 和 (9, +∞) 这两个区间加上间隙锁。这样做的核心是:阻止其他事务插入 id 值在 (5, 9) 或 (9, +∞) 区间内的新记录,例如插入 id=10。
为什么要阻止 id=10 的记录插入?假设事务A执行了上面的范围查询并加锁,如果此时事务B成功插入了 id=10 的记录并提交,那么事务A再次执行相同的 select ... for update 语句,就会发现结果集中多出了一条 id=10 的记录,这就是“幻读”。
如果把事务的隔离级别降级为读提交(Read Committed, RC),间隙锁则会自动失效,因为RC隔离级别允许幻读。
四、临键锁 (Next-Key Locks)
临键锁,是记录锁与间隙锁的组合。它的封锁范围既包含索引记录本身,也包含该索引记录之前的区间。更具体地说,临键锁会封锁索引记录本身,以及该记录之前的间隙。
官方文档的解释是:如果一个会话对索引中的记录R持有共享锁或排他锁,那么另一个会话不能立刻在按索引顺序紧邻R之前的间隙中插入新的索引记录。
依然是上面的例子,表 t 中的数据为 (1, 3, 5, 9)。
在id这个主键索引上,潜在的临键锁区间(左开右闭)为:
(-∞, 1]
(1, 3]
(3, 5]
(5, 9]
(9, +∞]
注意,这里的 +∞ 在InnoDB中用一个“上确界”记录来表示。
临键锁是InnoDB在可重复读(RR) 隔离级别下默认的行锁算法。它的主要目的同样是防止幻读(Phantom Read)。如果把事务隔离级别降级为RC,临键锁也会失效。
五、总结
- 索引存储方式:InnoDB的索引与行记录存储在一起(聚集索引),这与MyISAM(索引与数据分离)有根本不同。普通索引的叶子节点存储主键值,因此通过普通索引查询需要回表(查询两遍索引树)。
- 记录锁:锁定具体的索引记录。
- 间隙锁:锁定索引记录之间的间隔,防止在间隔中插入新数据,是可重复读隔离级别防止幻读的重要手段之一。
- 临键锁:记录锁与间隙锁的组合,锁定一个索引记录及其之前的间隙,是InnoDB在RR级别下的默认锁算法,用于彻底防止幻读。
理解这些锁机制,尤其是它们与InnoDB的索引结构以及事务隔离级别的关联,对于设计和优化高并发数据库应用至关重要。更复杂、有趣的锁冲突案例,往往都基于这些基础概念之上。
 发表于 2026-1-6 08:38:31
|
查看: 244|
回复: 0
发表于 2026-1-6 08:38:31
|
查看: 244|
回复: 0
