一、研究背景与核心问题
1.1 大语言模型(LLMs)在金融领域的潜力
大语言模型(LLMs)已在法律、医疗、客户服务等多个领域展现出强大的文本理解与生成能力。然而,在财富管理与系统性投资领域,关于其实际应用价值的实证研究仍较为有限。鉴于金融市场中大量信息以非结构化文本形式存在——如新闻报道、公司公告和管理层讨论——LLMs具备天然优势:能够实时解析复杂语义,提取潜在价格敏感信号,并为投资决策提供增量洞察。
近年来,学术研究逐渐揭示,传统因子收益(尤其是动量效应)与公司特定信息的逐步市场消化密切相关。投资者对新信息的反应往往存在滞后,导致价格在事件后持续漂移。这一过程创造了可预测的超额收益机会。因此,若能更精准地识别哪些新闻支持或挑战现有价格趋势,便可能提升因子策略的信息效率。这正体现了 人工智能 在解析海量非结构化数据方面的独特价值。
1.2 动量效应与信息滞后理论
经典资产定价文献已广泛验证动量效应的存在:过去表现强劲的股票在未来短期内倾向于继续跑赢(Jegadeesh 和 Titman, 1993)。进一步研究表明,这种现象部分源于投资者对基本面新闻的反应不足(Bernard 和 Thomas, 1989;Hong 和 Stein, 1999)。例如,盈利公告后的价格漂移表明,市场对新信息的吸收是渐进而非即时的。
在此背景下,公司特定新闻成为驱动动量延续或反转的关键因素。若新闻确认并强化当前趋势,价格可能继续上行;若新闻质疑趋势合理性,则可能引发反转。因此,能否有效解读新闻内容,成为提升动量策略表现的核心挑战。
1.3 核心研究问题
大语言模型能否通过解析公司特定新闻,增强横截面动量投资策略的表现?
为回答这一问题,本文构建了一个融合高频市场数据与实时新闻文本的实证框架,利用提示工程引导ChatGPT 4.0 mini模型生成预测性评分,并将其融入标准动量策略中,评估其对风险调整后收益的实际贡献。
二、研究设计与方法论框架
2.1 数据构建
本研究整合了四类关键信息源,构建一个高频、可操作的投资分析环境:
- 日度股票收益数据
- 覆盖标普500成分股,时间跨度从2019年至2025年
- 用于计算标准横截面动量信号,构成基准策略的表现参照
- 高频个股新闻数据库
- 来源:Stock News API
- 频率:分钟级时间戳,确保新闻与市场反应精确对齐
- 聚焦企业层面披露(如财报、并购、管理层变动),排除宏观新闻干扰
- 支持动态捕捉新闻事件对短期价格趋势的影响
- LLM交互机制(提示工程)
- 使用 OpenAI 的 ChatGPT 4.0 mini(预训练模型,未进行微调)
- 提示设计核心:明确告知模型“该股票即将进入动量组合”,将分析置于前瞻性投资决策语境中
- 指令目标:判断新闻是否支持近期正回报的持续性,生成0~1之间的信心评分
- 策略设计:横截面动量策略
- 经典动量信号:每月按过去12个月收益(剔除最近一个月)排序
- 构建多头组合,买入前两个十分位股票(Top 20%)
- 引入LLM评分优化选股与权重分配,形成增强型策略
该框架旨在测试:LLM对新闻语义的实时理解,是否能补充传统动量指标,提升组合的经济价值。
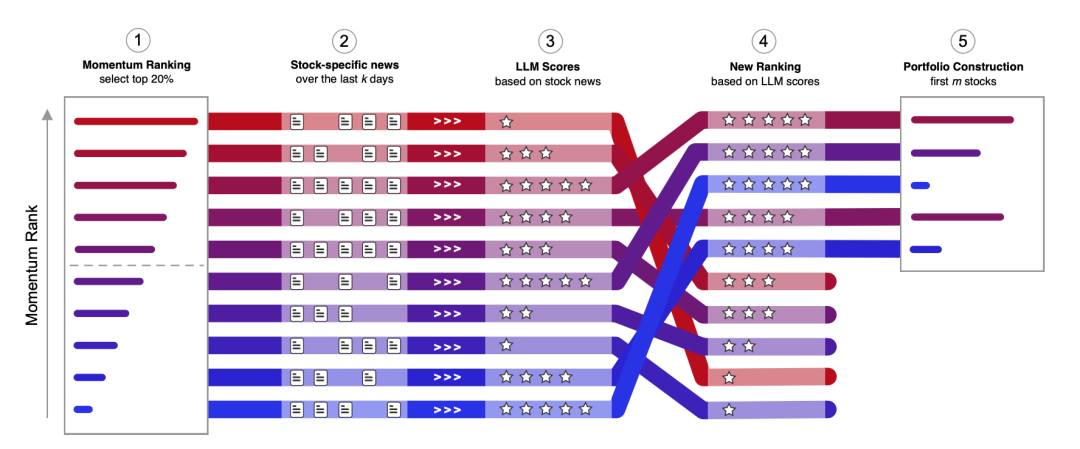
三、LLM增强动量组合构建流程
3.1 策略执行步骤
每月底执行以下流程:
- 识别候选股票池
选取过去12个月收益排名前两个十分位的标普500成分股(共约100只),作为基准动量组合候选。
- 收集新闻数据
对每只候选股,提取其在上一个k个交易日(t−k)至当前日(t)15:45之间的所有新闻文章。k为待优化参数。
- 调用LLM生成评分
将新闻列表输入ChatGPT,使用定制提示获取评分。每条新闻包含标题、摘要与发布时间,使模型可评估时效性与相关性。
- LLM输出与标准化
模型输出0~1之间的评分,代表其判断该股票未来短期表现延续的可能性。该评分经截面标准化至−1~+1区间。
- 排序与选券
按LLM评分降序排列候选股,相同评分者以原始动量排序,最终选取前m只股票构成增强组合(m为超参数)。
- 权重调整机制
第i只股票的最终权重由以下公式确定:
ω_i^enhanced = ω_i^base × (1 + η × score_i)ω_i^base:基准权重(等权或市值加权)η:权重乘数(控制倾斜强度)- 所有权重最终标准化至总和为1
该机制使LLM同时影响股票选择与资本配置,实现从信号到组合的端到端增强。
四、实证分析与样本划分
4.1 样本划分与评估逻辑
为保障结果稳健性并避免过拟合,总样本(1382个交易日)划分为两个子样本:

- 验证集:2019年10月 – 2023年12月(约4年,1070个观测值)
- 测试集:2024年1月 – 2025年3月(15个月,312个观测值)
- 用于无样本外评估
- 关键优势:完全位于ChatGPT 4.0 mini训练数据截止时间(2023年10月)之后
- 排除信息泄露可能,真实反映模型泛化能力
⚠️ 注:本研究未使用独立“训练集”,因模型为预训练静态黑箱,不进行参数更新。
4.2 超参数优化
采用网格搜索法测试共512种参数组合,涵盖:
- 再平衡频率(月度 / 周度)
- 新闻回溯窗口(1天 / 5天)
- 前瞻窗口(1天 / 21天)
- 提示类型(基础 / 高级)
- 入选股票数(25 / 50 / 75 / 100)
- 权重约束(是否设单股上限15%)
- 初始权重(等权 / 市值加权)
- 权重乘数η(1.25 / 2.5 / 3.75 / 5)
目标函数定义为:maximize: Sharpe Ratio - 0.5 × Turnover
最优参数集在验证集上确定后,固定应用于测试集,模拟真实投资环境。
五、关键实证结果
5.1 最优参数配置(基于验证集)
| 参数 |
最优值 |
| 再平衡频率 |
月度 |
| 新闻回溯窗口 |
1天 |
| 前瞻窗口 |
21天 |
| 提示类型 |
基础提示 |
| 入选股票数 |
50只 |
| 权重约束 |
是(单股≤15%) |
| 初始权重 |
市值加权 |
| 权重乘数η |
5 |
核心发现:最优策略体现“简洁、集中、低频、高倾斜”原则——即采用简单提示、聚焦少数高置信股票、月度再平衡,并显著放大LLM评分的资本配置权重。
5.2 策略绩效对比(年化,扣除2bps交易成本)
| 指标 |
全样本基准 |
LLM增强 |
样本外基准 |
LLM增强(样本外) |
| 夏普比率 |
0.57 |
0.69 |
0.79 |
1.06 |
| 索提诺比率 |
0.54 |
0.69 |
0.93 |
1.28 |
| 年化收益 |
15% |
18% |
24% |
30% |
| 波动率 |
26% |
24% |
24% |
22% |
| 最大回撤 |
-33% |
-31% |
-19% |
-17% |
| 换手率 |
62% |
90% |
48% |
80% |
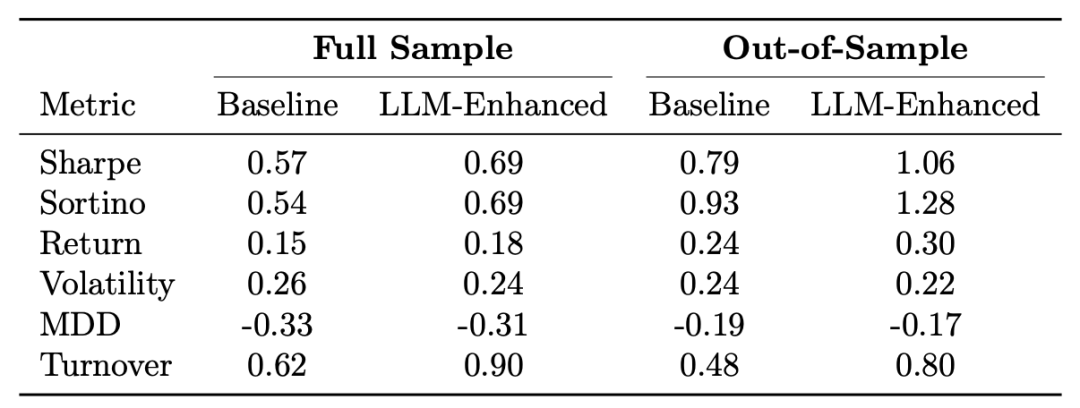
✅ 所有结果已扣除2个基点(bps)交易成本,表明更高换手率带来的摩擦被更强信号抵消。
✅ 样本外表现更优,且模型无法访问未来信息,证实收益源于实时新闻理解能力而非记忆效应。
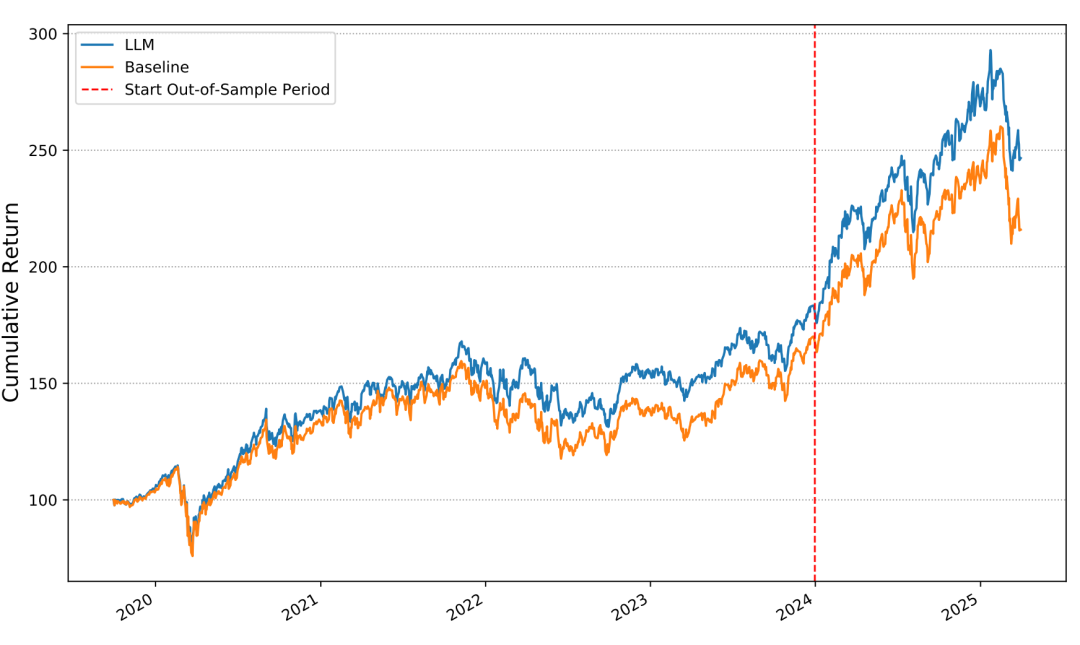
结论:LLM增强策略在样本内外均显著优于基准,尤其在样本外期间,夏普比率提升34%,年化收益提升6个百分点。
5.3 参数扰动分析(敏感性测试)
通过“其他条件不变”方法测试关键参数影响:
- 月度再平衡显著优于周度(1.1 vs 0.7):高频再平衡增加交易成本,未带来足够信号增益
- 1天回溯窗口最优:最新新闻最具预测力,延长至5天仅小幅改善
- 基础提示优于高级提示(1.1 vs 0.95):简洁指令已足够激发有效推理
- 权重乘数越高,表现越好:η=5时夏普达峰值,表明LLM评分差异具有经济意义
- 组合越集中,表现越优:25只股票时夏普达1.3,随规模扩大而下降
- 市值加权优于等权:大公司新闻更丰富,模型输入质量更高
🔍 深层含义:LLM的信息优势最显著体现在高新闻敏感性、高信念度的少数股票上,而非广泛覆盖的横截面信号。
六、研究贡献与理论意义
6.1 学术贡献
- 首次系统评估提示工程驱动的LLM在横截面动量策略中的经济价值
- 提供实证证据表明:LLM可作为实时新闻解释器,有效捕捉信息滞后带来的可预测性
- 揭示LLM信号在信息密集区(如大市值公司、高频新闻发布者)更具优势
- 证明模型具备真实泛化能力,其表现不依赖于预训练数据的记忆
6.2 实践意义
- LLM可为传统因子策略提供可操作的增量信息来源,提升风险调整后收益
- 策略具备良好可扩展性,适用于机构级系统性投资流程
- 提示工程是一种低成本、高灵活性的信号增强工具,无需复杂模型训练
- “集中+高倾斜”组合设计为高信念信号提供了放大机制
七、局限性与未来研究方向
7.1 研究局限
- 样本外期较短(仅15个月),需长期追踪以验证稳定性
- 研究局限于美国大盘股市场(标普500),推广性待检验
- 依赖单一预训练模型(ChatGPT 4.0 mini),未探索模型异质性
- 部分回归alpha在10%水平显著,需更多数据验证统计可靠性
7.2 未来研究方向
- 探索LLM微调或领域适配(domain adaptation)以提升金融语境理解
- 整合多源另类数据(如社交媒体、财报电话会议、供应链新闻)
- 扩展至多因子组合(如价值、质量、低波动)与跨资产类别应用
- 长期绩效追踪与策略稳定性评估
- 比较不同LLM(如GPT-4、Claude、Gemini)在金融任务中的表现差异。这类模型比较与选择策略,也是 智能 & 数据 & 云 领域持续探讨的话题。
八、结论
本研究系统评估了大语言模型在系统性投资中的应用潜力,聚焦于其是否可通过解析公司新闻增强横截面动量策略。基于标普500成分股与高频新闻数据,采用提示工程引导ChatGPT 4.0 mini生成预测评分,并构建LLM增强动量组合。
主要发现如下:
- LLM显著提升动量策略表现:在样本内外均实现更高夏普比率(1.06)、索提诺比率(1.28)与年化收益(30%),且结果在扣除2bps交易成本后仍稳健。
- 收益源于实时新闻理解:测试期完全在模型训练数据截止之后,排除信息泄露可能,证实模型具备真实泛化能力。
- 最优策略体现“简洁、集中、低频、高倾斜”原则:基础提示、月度再平衡、50只股票、高权重乘数配置表现最佳。
- LLM价值在高新闻敏感股票上最突出:集中组合表现更优,表明模型擅长识别信息驱动的机会。
✅ 最终结论:大语言模型不仅是实验性工具,更是现代投资流程中可实践、可扩展的增量价值来源。它能够有效识别公司新闻中的语义信号,为因子驱动策略注入实时、动态的信息优势。这种将前沿AI能力与经典金融理论结合的探索,正是 云栈社区 技术讨论所鼓励的方向。
参考文献:
ChatGPT in Systematic Investing - Enhancing Risk-Adjusted Returns with LLMs
 发表于 2026-1-6 17:36:23
|
查看: 207|
回复: 0
发表于 2026-1-6 17:36:23
|
查看: 207|
回复: 0
