随着大语言模型技术的飞速演进,AI 正在重塑软件开发的范式。对于广大 Java 开发者而言,如何高效地将 AI 能力集成到现有应用中,是一个亟待解决的问题。Spring AI 1.0 的发布,为这一问题带来了 Spring 风格的优雅解答。本文将手把手带你实战,基于 Spring AI 1.0 与国产高性能模型 DeepSeek,从零构建一个功能完备的企业级智能客服系统,涵盖架构设计、核心编码与部署全流程。
一、Spring AI 1.0 核心概览
1.1 框架定位与价值
Spring AI 是一个专为 AI 工程化应用设计的框架,它完美继承了 Spring 生态的核心优势:可移植性、模块化与可扩展性。它的出现,旨在为Java开发者提供一个统一、简洁的 API 层,以屏蔽不同 AI 模型提供商之间的差异。
1.2 核心组件构成
理解 Spring AI 的组件模型是高效使用它的前提,其主要由以下几部分构成:
- ChatClient: 与大型语言模型进行对话的核心接口。
- PromptTemplate: 用于管理和构建提示词模板,支持变量替换。
- Function Calling: 让 LLM 能够安全、结构化地调用外部服务或工具。
- VectorStore: 向量存储的抽象层,方便实现 RAG 架构。
- EmbeddingModel: 文本向量化接口,将文本转换为数值向量。
1.3 技术栈选型
本项目采用经过生产验证的现代技术栈,确保系统的稳定性与可扩展性:
- 后端框架: Spring Boot 3.2
- AI 框架: Spring AI 1.0
- 大语言模型: DeepSeek API
- 数据存储: MySQL 8.0(关系数据), Redis(缓存会话)
- 实时通信: WebSocket
- 向量检索: PostgreSQL (pgvector) 或专用向量数据库
二、系统架构设计
2.1 整体分层架构
我们采用经典的分层架构设计,确保各层职责清晰,便于维护和扩展。
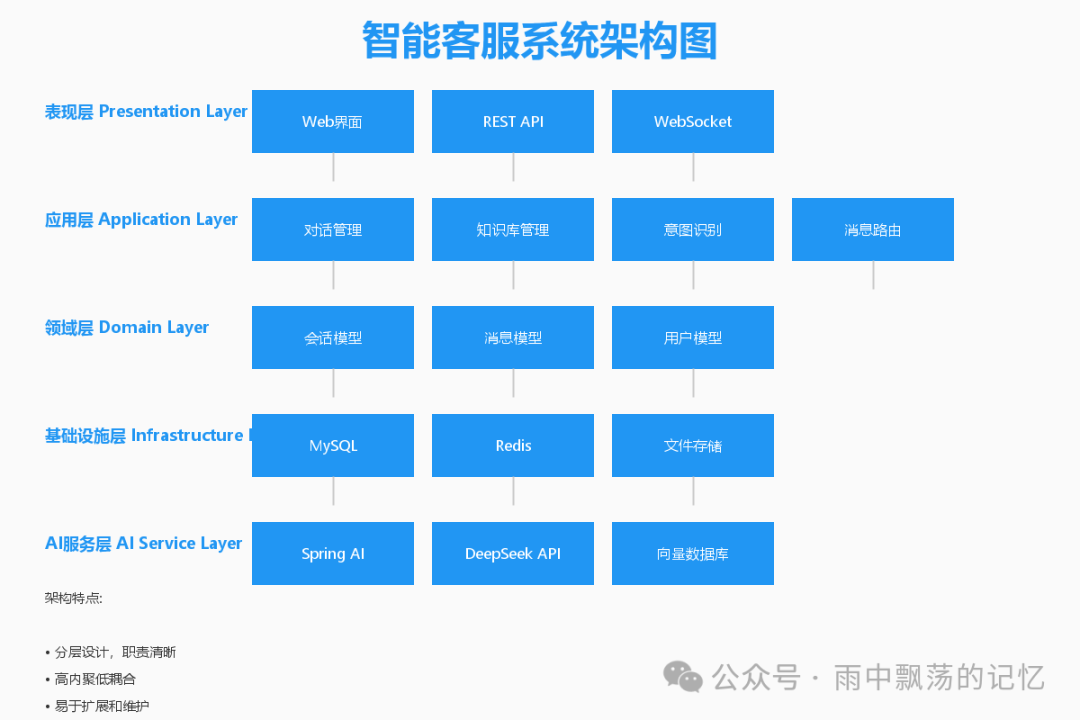
- 表现层: 提供 Web 聊天界面、RESTful API 及 WebSocket 端点。
- 应用层: 封装核心业务逻辑,如对话管理、意图识别与消息路由。
- 领域层: 定义核心业务实体,如会话、消息、用户模型。
- 基础设施层: 集成外部服务,包括数据库、缓存和文件存储。
- AI 服务层: 集成 Spring AI 与 DeepSeek,是智能能力的核心。
2.2 核心交互流程
用户与系统的每一次交互,都遵循一个清晰、高效的处理链条。
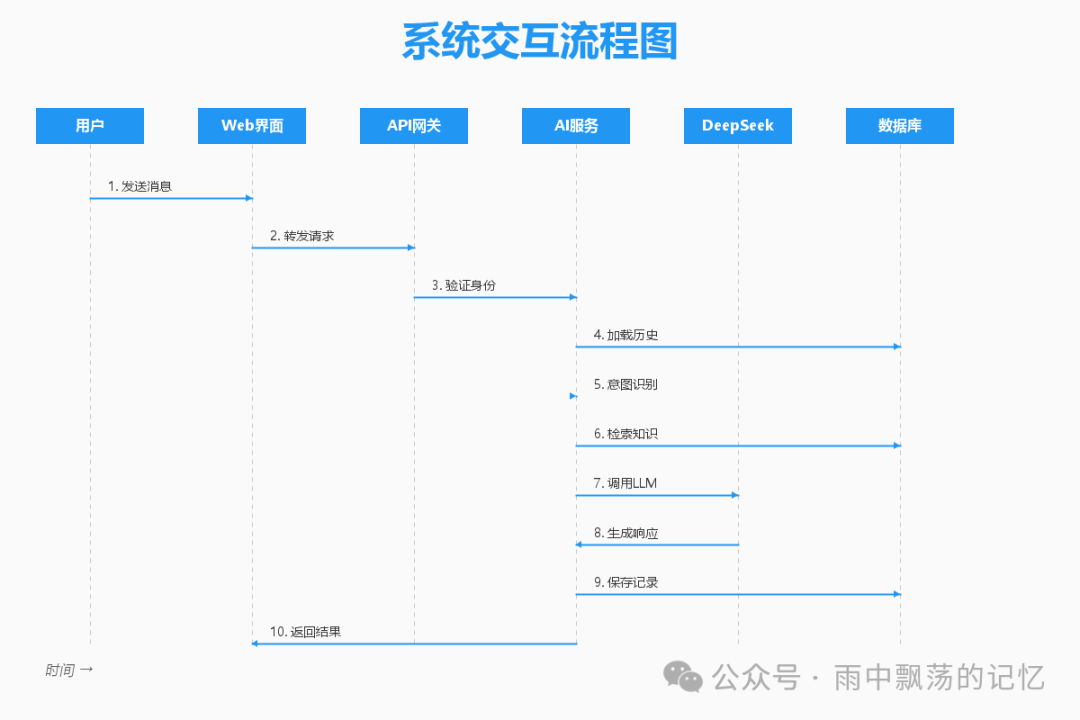
- 请求接收: 用户通过前端发送消息,经由 WebSocket 或 HTTP API 进入系统。
- 会话管理: 系统验证身份,并加载该用户的近期对话历史,维持上下文连贯性。
- 意图识别: 对用户输入进行初步分析,判断问题类型(如查询、操作、闲聊)。
- 策略执行:
- 简单问答:直接检索知识库获取标准答案。
- 复杂问题:通过 RAG 技术,从向量知识库检索相关片段,与问题一并提交给 LLM。
- 特定操作:触发函数调用,执行如“查询订单”等具体业务逻辑。
- 响应生成: DeepSeek 模型根据提示词和上下文生成回答。
- 流式返回: 通过 WebSocket 将响应内容实时、分段地推送给前端。
- 持久化: 完整保存本次对话的用户消息与 AI 响应,用于分析和模型优化。
三、数据存储设计
3.1 核心表结构
一个健壮的数据模型是系统稳定运行的基石。以下是经过精简的核心表设计。

- conversations(会话表)
- 存储用户会话的元信息,如唯一会话 ID、所属用户、状态和创建时间。
- 用于管理多轮对话的生命周期。
- messages(消息表)
- 记录所有对话的详细内容,通过
conversation_id 关联到会话。
- 通过
role 字段区分用户消息 (USER) 和 AI 助手消息 (ASSISTANT)。
- 可扩展字段记录 Token 消耗、响应耗时等,用于成本与性能监控。
- knowledge_base(知识库表)
- 存储企业的结构化与非结构化知识文档。
- 包含
title, content, category, tags 等字段用于分类管理。
kb_vector 字段是关键,用于存储文档内容的向量表示,支持高效的语义检索。
- user_feedback(用户反馈表)
- 收集用户对 AI 回复的直接评价(如点赞/点踩)和文本反馈。
- 这些数据是迭代优化提示词和评估模型效果的重要依据。
3.2 性能优化设计
为应对高并发查询,需要在以下字段建立索引:
messages(conversation_id, created_at): 加速按会话获取历史消息。knowledge_base(category, tags): 加速按分类或标签过滤知识文档。- 向量检索性能依赖于向量数据库的索引(如 HNSW 索引),这通常在向量库层面配置。
四、核心代码实现
4.1 项目初始化与配置
首先,创建一个 Spring Boot 项目并在 pom.xml 中添加关键依赖。
<dependencies>
<!-- Spring Boot Web & WebSocket -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
<!-- Spring AI (使用OpenAI兼容的Starter,因DeepSeek API兼容此格式) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
<!-- 数据持久化 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
</dependencies>
接着,在 application.yml 中配置 DeepSeek API 及其他服务。
spring:
ai:
openai:
api-key: ${DEEPSEEK_API_KEY} # 从环境变量读取
base-url: https://api.deepseek.com/v1
chat:
options:
model: deepseek-chat
temperature: 0.7
max-tokens: 2000
datasource:
url: jdbc:mysql://localhost:3306/ai_customer_service
username: root
password: ${DB_PASSWORD}
data:
redis:
host: localhost
port: 6379
4.2 实现AI对话服务
这是系统的中枢,负责协调知识检索、提示词构建和模型调用。
@Service
@Slf4j
public class ChatService {
private final ChatClient chatClient;
private final KnowledgeBaseService knowledgeBaseService;
private final MessageRepository messageRepository;
@Autowired
public ChatService(ChatClient.Builder chatClientBuilder,
KnowledgeBaseService knowledgeBaseService,
MessageRepository messageRepository) {
this.chatClient = chatClientBuilder.build();
this.knowledgeBaseService = knowledgeBaseService;
this.messageRepository = messageRepository;
}
/**
* 处理用户消息并流式返回AI响应
*/
public Flux<String> chat(String sessionId, String userMessage) {
log.info("会话[{}]收到用户消息: {}", sessionId, userMessage);
// 1. 保存用户消息
saveMessage(sessionId, "USER", userMessage);
// 2. 检索相关知识
String context = knowledgeBaseService.searchRelevantContent(userMessage);
// 3. 构建增强提示词
String prompt = buildPrompt(userMessage, context);
// 4. 调用AI并流式返回
return chatClient.prompt()
.user(prompt)
.stream()
.content()
.doOnNext(chunk -> log.debug("响应流片段: {}", chunk))
.doOnComplete(() -> {
// 响应流结束后,可将完整响应保存一次,这里简化为流式处理
log.info("会话[{}]响应流结束", sessionId);
});
}
/**
* 构建RAG提示词模板
*/
private String buildPrompt(String userMessage, String context) {
return String.format("""
你是一个专业、友好的客服助手。
请参考以下相关知识来回答用户的问题:
----------
%s
----------
用户的问题是:%s
请根据知识给出准确、清晰的回答。如果知识不相关或不足以回答问题,请礼貌告知并尝试提供一般性建议。
回答请使用中文,并保持语气亲切、专业。
""", context, userMessage);
}
private void saveMessage(String sessionId, String role, String content) {
Message message = new Message();
message.setSessionId(sessionId);
message.setRole(role);
message.setContent(content);
message.setCreatedAt(LocalDateTime.now());
messageRepository.save(message);
}
}
4.3 实现函数调用能力
Spring AI 的函数调用功能能让 AI 助手“动手操作”业务系统,极大扩展了应用场景。
@Component
public class CustomerServiceFunctions {
private final OrderService orderService;
/**
* 查询订单状态 - 将被AI调用的函数
*/
@FunctionInfo(description = "根据订单号查询订单的最新状态", name = "queryOrderStatus")
public String queryOrderStatus(
@FunctionParam(description = "用户的订单号码") String orderNumber) {
log.info("函数调用: 查询订单状态,订单号={}", orderNumber);
return orderService.getOrderStatus(orderNumber)
.map(status -> String.format("订单【%s】的当前状态是:%s。", orderNumber, status))
.orElse("抱歉,未找到订单号 " + orderNumber + " 的相关信息。");
}
/**
* 查询用户余额
*/
@FunctionInfo(description = "查询指定用户的账户余额", name = "queryUserBalance")
public String queryUserBalance(
@FunctionParam(description = "用户的唯一标识ID") String userId) {
log.info("函数调用: 查询用户余额,用户ID={}", userId);
// 模拟业务调用
return String.format("用户 %s 的当前账户余额为 1,234.56 元。", userId);
}
}
在对话服务中启用这些函数:
public Flux<String> chatWithFunctions(String sessionId, String userMessage) {
return chatClient.prompt()
.user(userMessage)
.functions("queryOrderStatus", "queryUserBalance") // 注册可用函数
.stream()
.content();
}
4.4 知识库与向量检索实现
这是实现 RAG 的关键,让模型能基于私有知识作答。
@Service
@Slf4j
public class KnowledgeBaseService {
private final EmbeddingModel embeddingModel;
private final VectorStore vectorStore;
/**
* 搜索与查询最相关的知识文档
*/
public String searchRelevantContent(String query) {
// 1. 将查询语句转换为向量
List<Double> queryEmbedding = embeddingModel.embed(query);
// 2. 在向量数据库中执行相似性搜索
List<Document> relevantDocs = vectorStore.similaritySearch(
SearchRequest.query(queryEmbedding)
.withTopK(3) // 返回最相似的3条
.withSimilarityThreshold(0.7) // 设置相似度阈值
);
// 3. 将检索到的文档内容组合成上下文
if (relevantDocs.isEmpty()) {
return "暂无直接相关的知识文档。";
}
return relevantDocs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n---\n"));
}
/**
* 向知识库添加新文档
*/
public void addDocument(String title, String content) {
List<Double> vector = embeddingModel.embed(content);
Document doc = new Document(content);
doc.getMetadata().put("title", title);
doc.getMetadata().put("embedding", vector);
vectorStore.add(List.of(doc));
log.info("已成功添加文档到知识库: {}", title);
}
}
4.5 WebSocket实时通信
为了实现打字机式的流式响应体验,我们使用 WebSocket。
@Configuration
@EnableWebSocket
public class WebSocketConfig implements WebSocketConfigurer {
@Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
registry.addHandler(new ChatWebSocketHandler(), "/ws/chat")
.setAllowedOrigins("*");
}
}
@Component
public class ChatWebSocketHandler extends TextWebSocketHandler {
@Autowired
private ChatService chatService;
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) throws Exception {
String payload = message.getPayload();
// 解析前端发送的JSON: {sessionId: "xxx", message: "用户问题"}
ChatRequest request = objectMapper.readValue(payload, ChatRequest.class);
// 调用AI服务,并将流式响应逐个片段推送给前端
chatService.chat(request.getSessionId(), request.getMessage())
.subscribe(chunk -> {
session.sendMessage(new TextMessage(chunk));
});
}
}
五、前端界面示例
一个简洁直观的前端界面能极大提升用户体验。
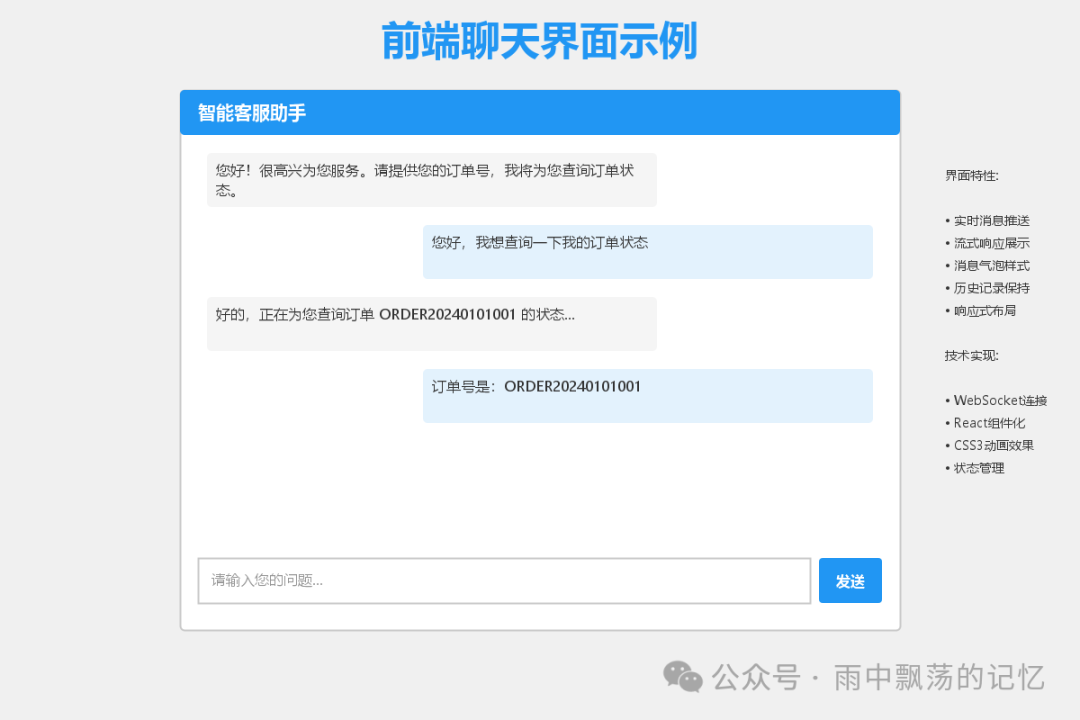
以下是一个极简的 HTML/JS 实现,展示核心逻辑:
<!DOCTYPE html>
<html>
<head>
<title>智能客服助手</title>
<style>
/* 样式代码同上,已优化可读性 */
.chat-container { max-width: 800px; margin: auto; height: 600px; border: 1px solid #ddd; display: flex; flex-direction: column; }
.chat-messages { flex: 1; overflow-y: auto; padding: 20px; }
.message { margin-bottom: 15px; padding: 10px; border-radius: 8px; max-width: 80%; }
.user-message { background-color: #e3f2fd; align-self: flex-end; }
.ai-message { background-color: #f5f5f5; align-self: flex-start; }
.chat-input { display: flex; padding: 20px; border-top: 1px solid #ddd; }
#userInput { flex: 1; padding: 10px; font-size: 16px; border: 1px solid #ddd; border-radius: 4px; }
#sendBtn { margin-left: 10px; padding: 10px 20px; background-color: #2196F3; color: white; border: none; border-radius: 4px; cursor: pointer; }
</style>
</head>
<body>
<div class="chat-container">
<div class="chat-messages" id="messageContainer"></div>
<div class="chat-input">
<input type="text" id="userInput" placeholder="请输入您的问题..." />
<button id="sendBtn" onclick="sendMessage()">发送</button>
</div>
</div>
<script>
const ws = new WebSocket('ws://' + window.location.host + '/ws/chat');
let currentSessionId = 'session_' + Date.now(); // 生成一个会话ID
ws.onmessage = function(event) {
appendMessage('AI', event.data);
};
function sendMessage() {
const input = document.getElementById('userInput');
const message = input.value.trim();
if (!message) return;
appendMessage('USER', message);
// 发送JSON格式请求
ws.send(JSON.stringify({
sessionId: currentSessionId,
message: message
}));
input.value = '';
}
function appendMessage(role, content) {
const container = document.getElementById('messageContainer');
const msgDiv = document.createElement('div');
msgDiv.className = `message ${role.toLowerCase()}-message`;
msgDiv.textContent = (role === 'AI' ? '助手: ' : '我: ') + content;
container.appendChild(msgDiv);
container.scrollTop = container.scrollHeight; // 滚动到底部
}
// 支持回车发送
document.getElementById('userInput').addEventListener('keypress', e => { if (e.key === 'Enter') sendMessage(); });
</script>
</body>
</html>
六、系统部署与监控
6.1 容器化部署架构
采用 Docker 容器化部署是实现环境一致性和快速伸缩的最佳实践。
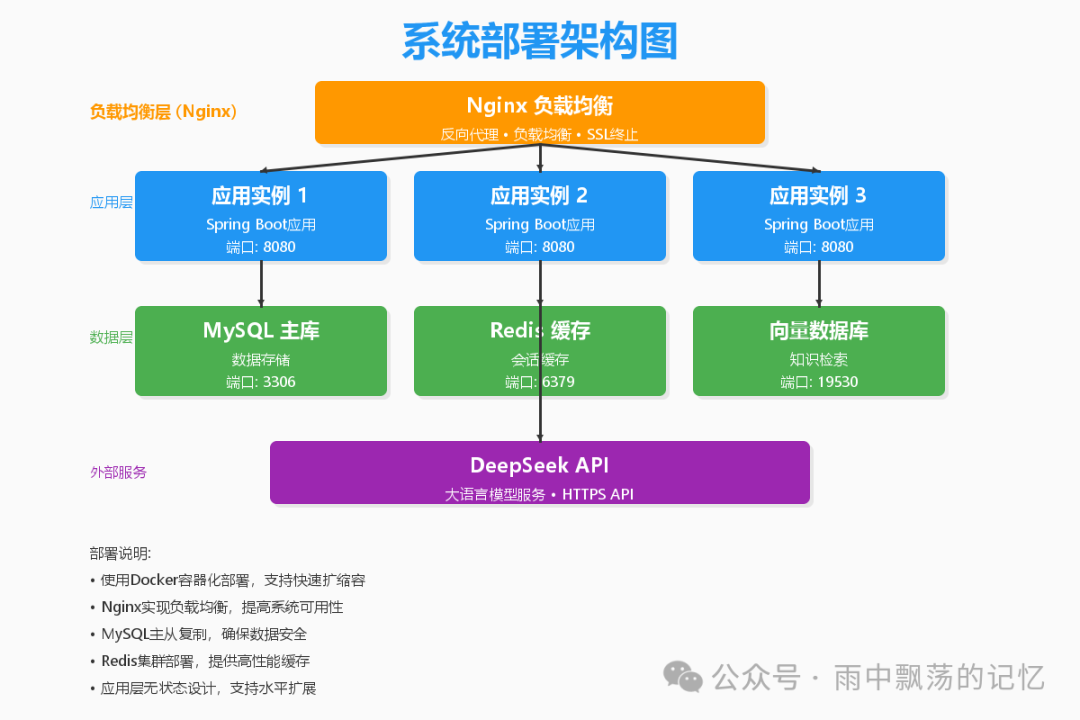
部署说明:
- 负载均衡层: 使用 Nginx 作为反向代理,实现 SSL 终止、负载均衡和静态资源服务。
- 应用层: 将 Spring Boot 应用打包为 Docker 镜像,通过多个容器实例实现水平扩展。
- 数据层: MySQL 和 Redis 也运行在容器中,生产环境建议使用云托管服务或独立服务器保障数据持久性。
- 外部服务: DeepSeek API 作为外部 HTTPS 服务被调用。
6.2 Docker 配置示例
Dockerfile:
FROM openjdk:17-jdk-slim AS builder
WORKDIR /app
COPY mvnw pom.xml ./
COPY .mvn .mvn
RUN ./mvnw dependency:go-offline
COPY src ./src
RUN ./mvnw clean package -DskipTests
FROM openjdk:17-jdk-slim
WORKDIR /app
COPY --from=builder /app/target/*.jar app.jar
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "app.jar"]
docker-compose.yml (开发环境):
version: '3.8'
services:
app:
build: .
ports:
- "8080:8080"
environment:
- SPRING_DATASOURCE_URL=jdbc:mysql://db:3306/ai_customer_service
- SPRING_REDIS_HOST=redis
- DEEPSEEK_API_KEY=${DEEPSEEK_API_KEY}
depends_on:
- db
- redis
db:
image: mysql:8.0
environment:
- MYSQL_ROOT_PASSWORD=rootpassword
- MYSQL_DATABASE=ai_customer_service
volumes:
- mysql_data:/var/lib/mysql
redis:
image: redis:7-alpine
volumes:
- redis_data:/data
volumes:
mysql_data:
redis_data:
6.3 关键监控指标
系统上线后,需密切关注以下指标以保障稳定运行与持续优化:
- 服务质量: 平均响应延迟、每秒查询率、WebSocket 连接数。
- AI性能: 每次调用的 Token 消耗、DeepSeek API 调用成功率与错误类型。
- 业务效果: 用户主动好评/差评率、会话平均轮次、问题解决率。
- 系统资源: 应用服务器的 CPU、内存使用率,数据库连接池状态。
七、总结与最佳实践
通过本文的实践,我们完成了一个基于 Spring AI 1.0 和 DeepSeek 的智能客服系统核心搭建。Spring AI 以其统一的抽象层,显著降低了在 Java 生态中集成 AI 能力的复杂度。
核心收获与建议:
- 提示词工程是关键: 精心设计的提示词(包括系统指令、上下文格式)直接决定回答质量。应持续根据业务反馈进行迭代优化。
- RAG架构提升准确性: 对于企业专属知识,务必采用检索增强生成技术,避免模型“幻觉”,确保回答基于事实。
- 流式响应优化体验: 对于文本生成类应用,流式输出能极大提升用户感知速度,务必采用。
- 函数调用扩展边界: 将 AI 与内部业务系统(如订单、用户系统)通过函数调用连接,能实现从“问答”到“办事”的质变。
- 关注成本与性能: 大模型 API 调用有成本,需通过缓存常见问答、合理设置
max-tokens 等方式进行控制。同时,数据库查询和向量检索的性能直接影响整体响应时间。
Spring AI 作为 Spring 官方项目,其生态和稳定性值得信赖。随着人工智能技术的不断进步,相信它将成为 Java 开发者构建智能应用的标配工具。希望本文的实战指南能为你开启 AI 应用开发之门。如果你想了解更多关于系统架构或微服务设计的深度内容,欢迎访问云栈社区进行交流探讨。
 发表于 2026-1-10 09:24:08
|
查看: 282|
回复: 0
发表于 2026-1-10 09:24:08
|
查看: 282|
回复: 0
