现代大语言模型普遍依赖全注意力机制,但其计算复杂度随上下文长度呈平方级增长,这成为了支撑检索增强生成、工具集成推理等长上下文应用场景的主要瓶颈。为此,研究人员持续探索稀疏注意力作为高效替代方案,通过有选择地保留关键键值对来大幅降低计算开销。近期研究表明,在模型的中期训练阶段将全注意力替换为稀疏版本,已成为一条行之有效的优化路径。
为此,美团的研究团队提出了一种名为 LongCat ZigZag Attention (LoZA) 的新稀疏注意力机制。其核心目标是以极低的计算开销,将任意现有的全注意力模型高效地转换为稀疏版本。在长上下文场景中,LoZA 能够在预填充密集型任务(如RAG)和解码密集型任务(如工具调用)中实现显著加速,且适用于各类基于全注意力的语言模型。
具体而言,通过在中期训练阶段引入 LoZA,研究团队将 LongCat-Flash 模型升级为 LongCat-Flash-Exp。升级后的模型能够快速处理高达 100 万 tokens 的超长上下文,显著提升了长期推理与长周期智能体任务的执行效率。

方法
(1)LongCat ZigZag Attention机制
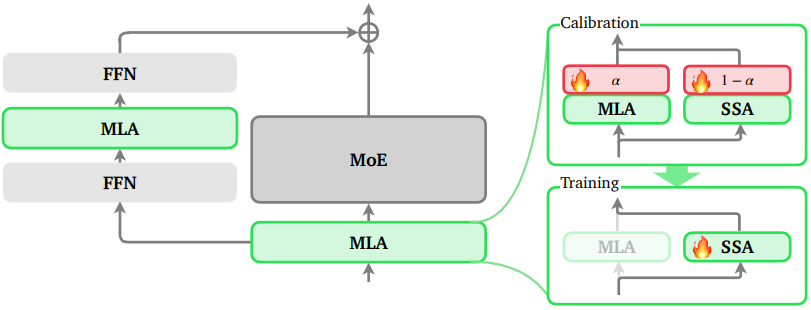
图1 LoZA方法示意图
如图1所示,LoZA 的实施分为两个关键步骤:首先,识别出在稀疏化后对模型整体性能影响较小的层;其次,对这些筛选出的层进行针对性的稀疏化与再训练,以弥合因稀疏化带来的性能差距。理论上,一个经过中期训练的语言模型会经历 稀疏化 → 权重回退 → 再次中期训练 的循环过程,旨在最大程度地恢复原始全注意力模型的性能。其中,校准阶段始于中期训练的末尾,而基于稀疏结构的正式训练则从中期训练的起始阶段开始。
校准
在 DeepSeek-V3 和 LongCat-Flash 等大语言模型中,已普遍采用了 MLA(Multi-head Latent Attention)机制。LoZA 假设模型中共包含 n 个 MLA 模块,并为每个模块引入一个独立的可学习权重 α_i ∈ [0,1],用于调节其注意力输出。具体而言,第 i 个 MLA 的最终输出由下式给出:
Output_i = α_i * MLA_full_i + (1 - α_i) * MLA_sparse_i
其中,MLA_full_i 和 MLA_sparse_i 分别表示第 i 个 MLA 使用全注意力和稀疏注意力所产生的输出。此处的稀疏注意力遵循流式稀疏模式,即每个查询 token 仅关注若干个“汇点块”(sink blocks)和局部块(local blocks)。
随后,在校准数据上进行一轮训练,此过程中冻结中期训练语言模型中的所有参数,仅优化所有权重 α_i。α_i 的大小直接表征了对应 MLA 模块的重要性。值得注意的是,对 α_i 值最低的那部分 MLA 进行稀疏化后,语言模型的整体性能仍能得到基本保持。
基于校准阶段的观察,LoZA 将中期训练模型中 α_i 最低的 50% 的 MLA 模块,由全注意力替换为流式稀疏注意力(SSA),其输出形式简化为:
Output_i = SSA(K*, V*)
其中, K* 和 V* 是经过特定模式选择并分块的键与值,该模式由几个关键参数定义:汇点块数量 s、局部块数量 l,以及块大小 b。
训练
尽管初步稀疏化后的模型已展现出较强的性能,但为弥补稀疏化操作(尤其是在长上下文场景中)可能引入的细节损失,仍需进行额外的训练以充分恢复模型能力。考虑到中期训练本身仅涉及数千亿量级的 token 消耗,相较于完整的预训练流程,其计算开销在有限资源下是相对可控的。因此,研究者将这一恢复性训练阶段整合到了中期训练过程中。
(2)LongCat‑Flash‑Exp训练过程
该训练过程涵盖了中期训练(仅包含长上下文扩展阶段)以及后续的轻量级后训练,最终得到 LongCat-Flash-Exp 模型。
中期训练
中期训练沿用 LongCat-Flash 的数据分布与训练策略,采用渐进式上下文扩展:依次在 32K、128K 和 256K token 长度上进行训练,并借助 YaRN 位置编码方法实现对 1M token 上下文的外推能力。
后训练
为快速验证并控制成本,后训练采用了轻量级方案,仅使用 LongCat-Flash 原始后训练数据量的 50%,但经过精心筛选以覆盖指令遵循、数学、代码、智能体任务和通用知识等关键领域。该阶段首先进行监督微调(SFT),随后结合直接偏好优化(DPO)与强化微调(RFT)进行人类偏好对齐。
整个架构集成了 LoZA 稀疏注意力机制,其关键配置包括:块大小 b=128,汇点块数 s=1,局部块数 l=7,形成了总计 1,024 token 的稀疏注意力窗口。这一设计在保障长上下文建模能力的同时,为实现计算效率的飞跃性提升奠定了基础。
评估

表2 LongCat-Flash-Exp-Base 的有效性
如表2所示,引入 LoZA 并未导致模型性能的下降。具体而言,在完成稀疏化改造及对应的中期训练后,LongCat-Flash-Exp-Base 在多项基准测试上的性能仍与原始的全注意力版本 LongCat-Flash-Base 保持相当。
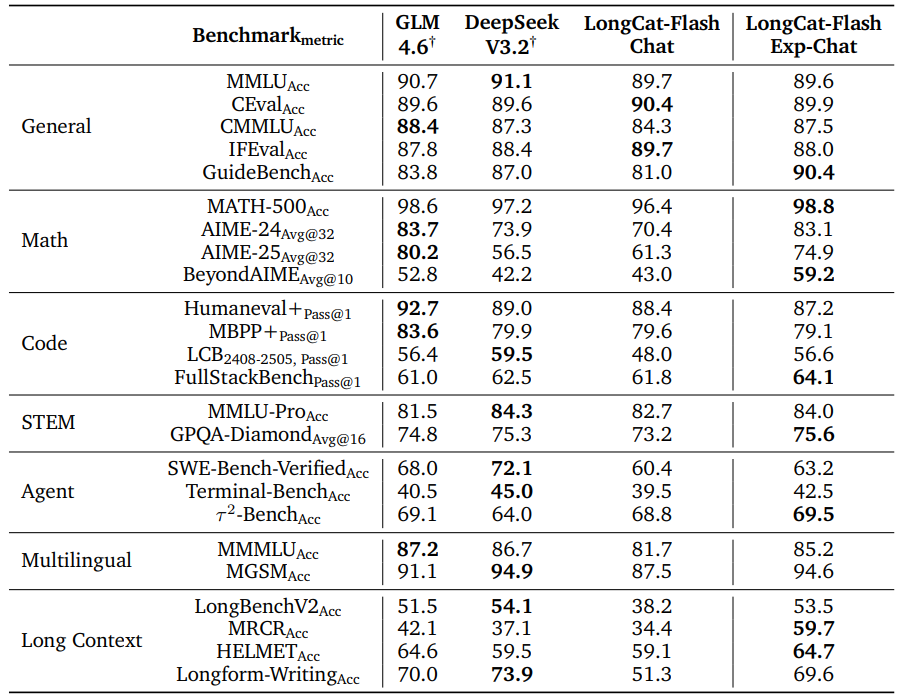
表3 LongCat‑Flash‑Exp‑Chat与主流模型综合能力对比
如表3所示,LoZA 并未以牺牲模型质量为代价来换取速度。在广泛的基准测试中,LongCat-Flash-Exp-Chat 表现出与 LongCat-Flash-Chat 相当的竞争力。具体而言,LongCat-Flash-Exp 在长上下文专项基准测试中的表现甚至优于 LongCat-Flash-Chat,这主要得益于其对更长上下文长度的原生支持。在对话能力的横向对比中,LongCat-Flash-Exp-Chat 的表现也与 GLM-4.6 等其他主流模型处于同一水平。
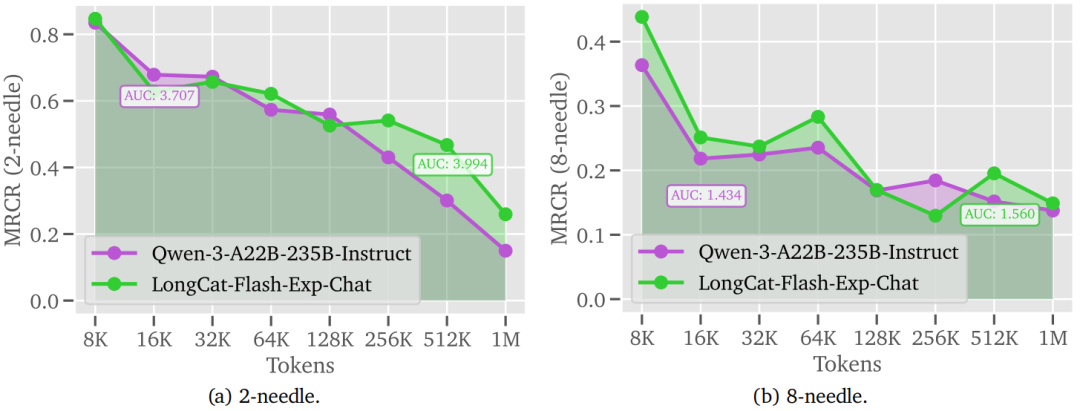
图2 LongCat-Flash-Exp-Chat 与 Qwen-3 在长上下文任务上的表现对比
此外,研究还对 LongCat-Flash-Exp-Chat 与同样支持 1M 上下文的 Qwen-3 模型进行了不同上下文长度下的细粒度对比评测。如图2所示,LongCat-Flash-Exp-Chat 在多个上下文长度区间上的表现明显优于 Qwen-3,并且在整体曲线下面积(AUC)指标上实现了超越。这一结果表明,LoZA 结合 YaRN 能够高效支撑 1M 级别的上下文扩展,在保持甚至提升模型长文本理解性能的同时,实现了更高的计算效率。
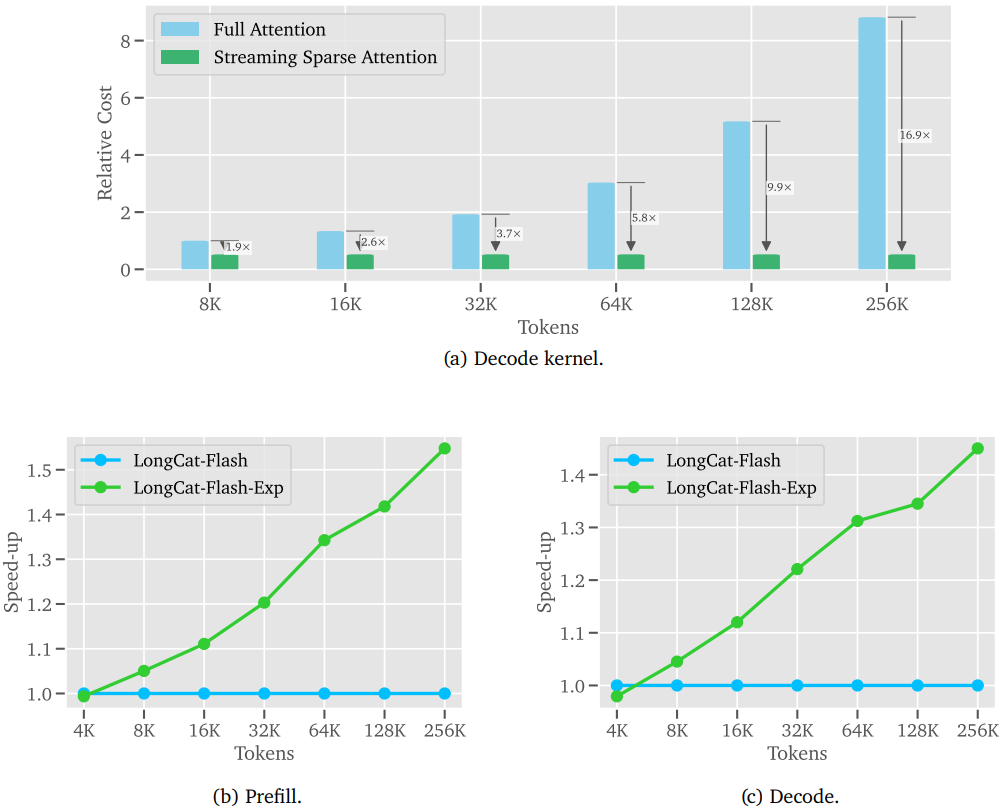
图3 LoZA 稀疏注意力机制带来的效率提升
如图 3 所示,LoZA 带来的效率提升是显著的。在 128K 上下文长度下,流式稀疏注意力核在解码阶段的计算开销相比全注意力核最高可降低 90%。从端到端的基准测试来看,LongCat-Flash-Exp 在 256K 上下文长度下,实现了超过 50% 的预填充阶段加速,并在解码阶段节省了逾 30% 的计算开销,充分彰显了其在真实推理场景中的高效性与实用价值。这项研究为大规模语言模型的高效训练与推理提供了一条新颖且有效的技术路径。
这项关于注意力机制优化的研究展示了前沿的模型压缩与加速思路,对从事AI研究与开发的朋友具有很高的参考价值。如果你想了解更多类似的硬核技术解析或与同行交流,欢迎关注云栈社区。
 发表于 2026-1-10 09:30:19
|
查看: 175|
回复: 0
发表于 2026-1-10 09:30:19
|
查看: 175|
回复: 0
