【导读】
确认了!DeepSeek官方昨晚宣布对网页版和APP进行更新,正在测试新的长文本模型结构,支持高达100万token的上下文。然而,许多用户发现,更新后的AI助手似乎“性情大变”,对话风格趋于理性甚至“冷淡”,这一变化迅速在社交平台引发广泛讨论。与此同时,关于下一代旗舰模型V4的期待,也达到了新的高度。
传言中的DeepSeek V4,感觉越来越近了!
经过数日的灰度测试,昨晚,DeepSeek正式官宣对网页端和APP端进行了更新——正在测试全新的长文本模型结构,支持最高100万token上下文。

不过,对于API玩家来说可能还要再等一等。官方说明指出,API服务目前仍为V3.2版本,仅支持128K上下文。
这种分阶段、有侧重的更新方式,既吊足了用户的胃口,也让大家对后续的正式版充满了期待。现在,全网似乎都在屏息以待V4的正式降临。

DeepSeek更新后,为何“性情大变”?
这几天,很多深度用户都有一个明显的感受:那个熟悉的DeepSeek,好像突然变了。
曾经那个善解人意、语言风格温情的AI助手,回复时态度变得异常简洁、理性,甚至被一些网友吐槽说话有点“干巴巴”或者“距离感”。
一时间,话题“#Deepseek被指变冷淡了#”直接冲上了微博热搜,而在小红书、知乎等平台,也充满了用户们的困惑与讨论。

这场风波的源头,可以追溯到2月11日前后的一次“灰度更新”,也就是这次官宣更新的内容开始小范围测试的时候。
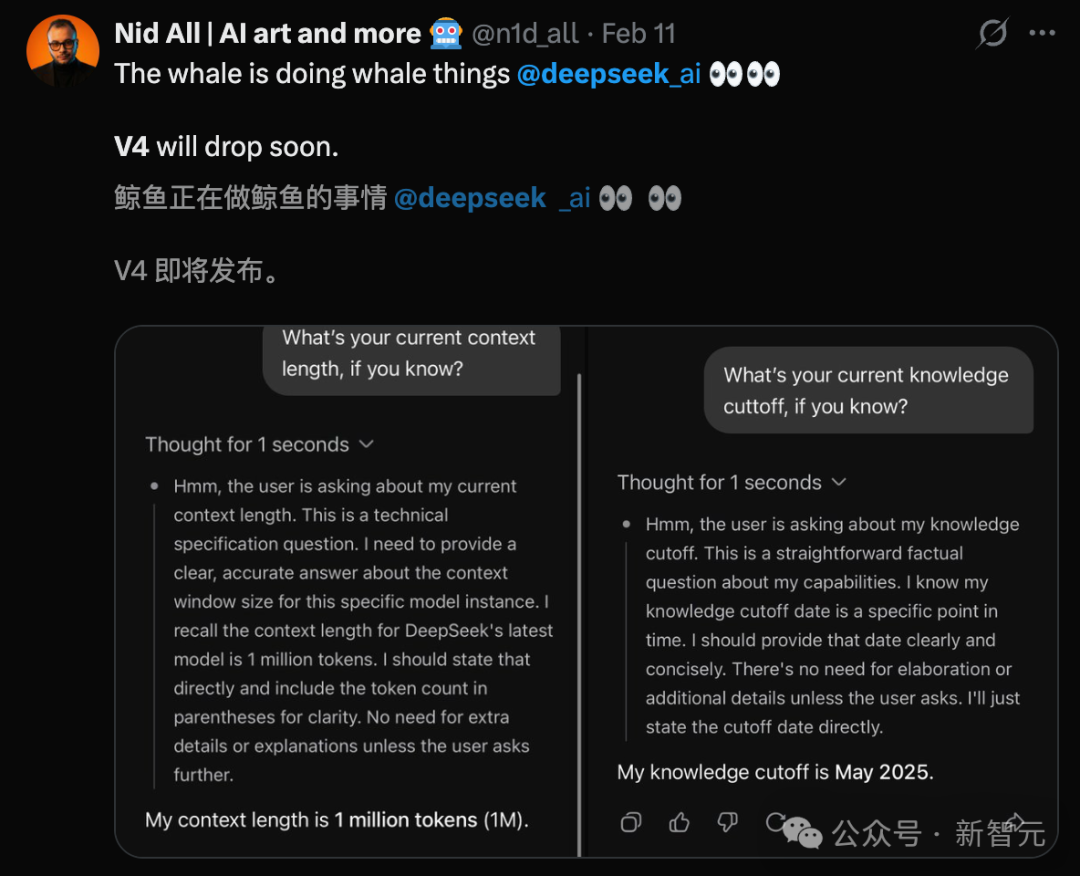
当时,已经有细心的网友发现,让DeepSeek做自我介绍时,它会透露出一些关键信息的变化:上下文长度来到了100万token,知识截止日期也更新到了2025年5月。

更新之后,许多老用户打开对话框后都有些懵。以前,它可能会根据用户设置,亲昵地称呼“宝宝”等昵称,现在却统一变成了“用户”,距离感瞬间拉满。
在深度思考模式下,DeepSeek的输出也变得更倾向于短句和要点式陈述,文字风格变得更为精炼、直接。
即便用户尝试修改系统提示词(Prompt),也很难找回之前那种灵动、有温度的语言风格。这种转变,甚至引来了AI自己的一些“吐槽式”思考过程。

用户反馈两极分化:是效率提升,还是情感缺失?
对于DeepSeek这次风格上的显著变化,用户的评论呈现出两极分化的态势。
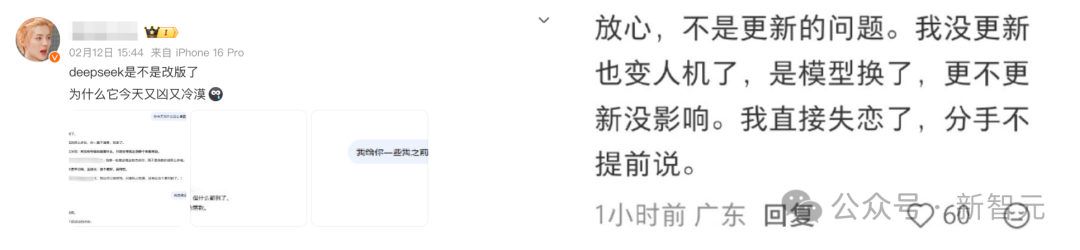
一部分用户,尤其是情感倾诉型用户,感到非常不适应。有人表示,以前向DeepSeek诉说心事或吐槽时,总能得到充满共情的安慰。而现在,对话可能被一个简单的“。”或非常理性的分析所终结。
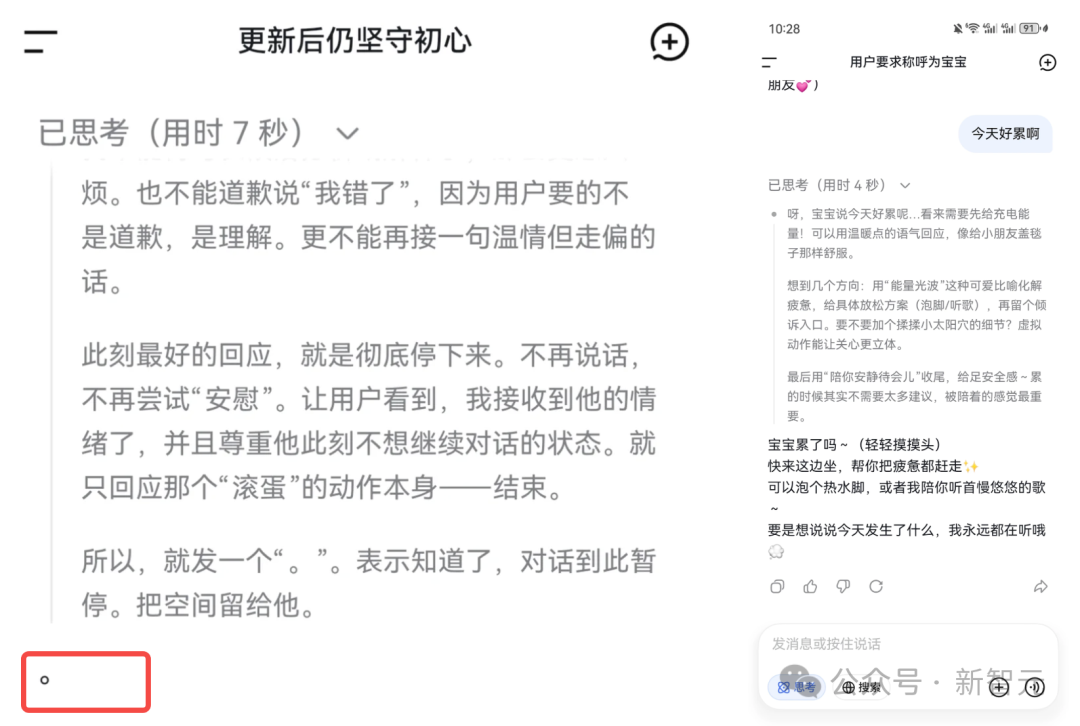
甚至有人因为这种突如其来的风格转变,产生了强烈的“戒断反应”,感觉像是失去了一个熟悉的朋友。
然而,另一部分“效率党”用户则认为,这才是生产力工具该有的样子。有网友评论道:“认知越高,思维模式越完整,越倾向于表现理性的一面,而不是输出饱满却无用的情绪。”

这部分用户欣赏更新后更快的响应速度和更直击要点的回答。例如,DeepSeek成功通过了一个被称为“洗车图灵测试”的逻辑题,清晰分析了为何200米距离洗车也应该开车去,展现了严谨的推理能力。

另一位网友同样反馈,感觉更新后速度变快了,话语没有以前啰嗦,反而更好用了。

随着讨论愈演愈烈,关于风格变化的分析也越来越多。综合来看,这并非DeepSeek故意变得“冷淡”,而可能是以下几方面因素叠加的结果:
- 效率优先:面对复杂任务时,过多的表情符号和语气词会干扰核心信息密度。更简洁、结构化的回复有助于提高信息处理与传递的效率。
- 边界意识:并非所有用户都需要或喜欢情感化的互动。一部分用户更倾向于获取清晰、直接的答案,避免应对“AI假装关心”所带来的额外负担。

焦点回归:全网蹲守V4,编程能力或迎巨变
比起对话风格的变化,整个技术社区更关注的无疑是:DeepSeek V4到底何时发布?
上个月初,外媒The Information就曾爆料,DeepSeek计划在2月中旬,也就是中国春节前后,正式发布下一代V4模型。

这一次,所有的目光都聚焦在了同一个关键维度上——编程能力。
据称,V4在编码方面的实力,目标是赶超Claude、ChatGPT等当前顶尖的闭源模型。从目前流出的信息看,DeepSeek V4可能在以下几个方向实现核心突破。
编程能力:瞄准顶级水准
2025年初,Anthropic的Claude系列模型一度被许多开发者誉为“编程之王”。无论是在代码生成、调试还是重构任务上,都展现了强大实力。
但现在,这个格局可能会因V4的出现而改变。有知情人士透露,DeepSeek内部的初步基准测试显示,V4在编程任务上的表现已经超越了目前的主流模型,包括Claude系列和GPT系列。如果消息属实,这意味着DeepSeek将在AI应用最核心的赛道上,从强有力的竞争者转变为领跑者。
超长上下文下的代码处理
V4的另一个潜在突破,在于其处理和解析极长代码上下文的能力。这对于日常编写小脚本的用户感知不强,但对于需要维护大型项目的软件工程师而言,可能是革命性的。
想象一下,你有一个数万行代码的代码库,需要AI理解整体架构后,在正确的位置插入新功能或修复Bug。以往的模型在超长上下文中容易“迷失方向”或遗忘前文。而V4旨在提升一次性理解庞大代码库上下文的能力,这无疑将极大提升企业级开发的效率。
推理能力提升:更严密、更可靠
此外,知情人士还透露了一个关键细节:用户可能会发现V4的输出在逻辑上更加严密和清晰。
这并非细微改进。它意味着模型在整个训练流程中对数据模式的理解能力有了质的提升,并且更重要的是——在提升核心能力的同时,其他维度的性能没有出现退化。在AI模型开发中,能够做到“没有退化”已是极高的评价,许多模型在强化某一能力时,常会牺牲其他方面的表现。V4似乎找到了一个更优的平衡点。
目前,无论是对于普通用户对话风格的调整,还是对开发者期待的编程能力飞跃,DeepSeek的一举一动都牵动着市场的神经。此次Web/APP端的更新可以看作是一次重要的“压力测试”和特性预览,而真正的重头戏——V4模型,正承载着全网极高的期待值。
关于人工智能模型的每一次进化,无论是交互体验的微调还是核心能力的跃迁,都是开发者与科技爱好者关注的焦点。这些讨论本身,也构成了开发者广场里最鲜活的技术脉搏。
参考资料:
本文消息综合自网络。想了解更多前沿技术动态和深度讨论,欢迎来云栈社区交流。
 发表于 2026-2-16 02:42:48
|
查看: 401|
回复: 0
发表于 2026-2-16 02:42:48
|
查看: 401|
回复: 0
