1 汇编语言和本地代码是一一对应的
计算机 CPU 能直接解释运行的只有本地代码(也称为机器语言)程序。用高级语言编写的源代码,必须通过编译器编译,才能转换成本地代码。
通过研究本地代码的内容,我们能了解程序最终是以何种形式运行的。但如果直接打开本地代码文件,看到的只是一堆难以理解的数值罗列。
为了解决这个问题,人们想出了为本地代码附上表示其功能的英语单词缩写。例如,在加法运算的本地代码旁加上add(addition的缩写),在比较运算旁加上cmp(compare的缩写)。这些缩写被称为助记符,而使用助记符的编程语言就称为汇编语言。
即便如此,用汇编语言编写的源代码最终也必须转换成本地代码才能运行。负责这项转换工作的程序称为汇编器,转换过程本身称为汇编。反过来,本地代码也可以转换成汇编语言的源代码。具备这种逆转换功能的程序称为反汇编程序,逆转换过程称为反汇编。
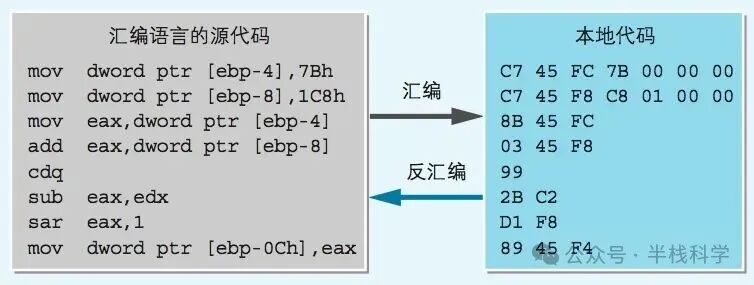
2 通过编译器输出汇编语言的源代码
获取汇编语言源代码,除了对本地代码进行反汇编,还有另一种常用方法。大多数 C 语言编译器都支持将 C 源代码直接转换成汇编语言源代码,而不是一步到位生成本地代码。这对于学习计算机基础知识,理解高级语言如何映射到底层操作非常有帮助。

下面是通过编译器生成的汇编语言源代码片段(部分省略,彩色部分是转换成的 C 语言注释)。
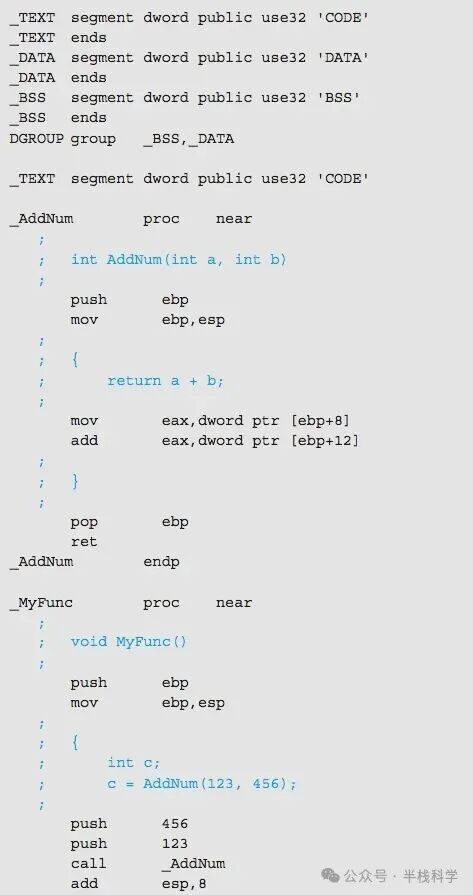

3 不会转换成本地代码的伪指令
汇编语言的源代码由两部分构成:一是可以转换成本地代码的指令(即操作码),二是针对汇编器的伪指令。
伪指令的作用是将程序的构造及汇编方法指示给汇编器,但它本身不会被汇编成本地代码。
例如,下面是从示例代码中摘出的伪指令部分:


由伪指令 segment 和 ends 围起来的部分,被称为段定义。它给构成程序的命令或数据的集合体加上一个名字。
_TEXT 是指令的段定义。_DATA 是已初始化(有初始值)的数据的段定义。_BSS 是尚未初始化数据的段定义。group 伪指令表示将 _BSS 和 _DATA 这两个段定义汇总为名为 DGROUP 的组。_AddNum proc 和 _AddNum endp 围起来的部分,以及 _MyFunc proc 和 _MyFunc endp 围起来的部分,分别表示 AddNum 函数和 MyFunc 函数的范围。用伪指令 proc 和 endp 围起来的部分表示一个过程(procedure)的范围。
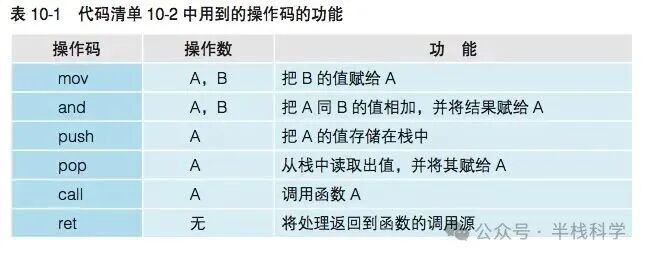
4 汇编语言的语法是“操作码 + 操作数”
在汇编语言中,一行通常对应 CPU 的一个指令。其语法结构是操作码 + 操作数(也存在只有操作码的指令)。操作码表示指令要执行的动作,而操作数则表示指令操作的对象。
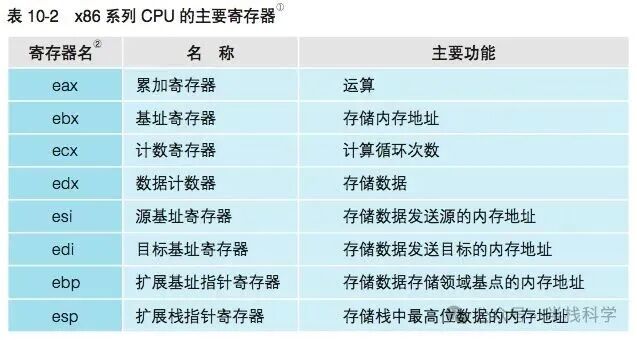
本地代码必须加载到内存中才能运行。内存里存储着构成本地代码的指令和数据。程序运行时,CPU 会从内存中读取指令和数据,然后将它们存储在 CPU 内部的寄存器中进行处理。
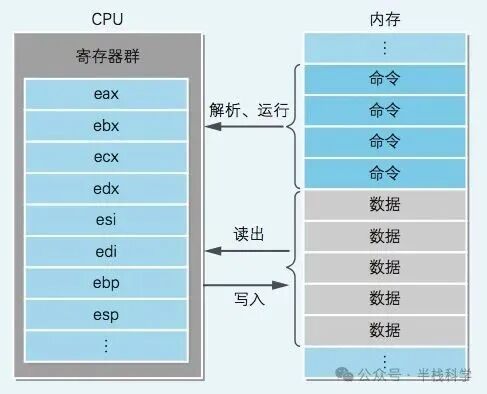
寄存器是 CPU 中的存储区域,但它不仅有存储功能,还具备运算能力。在汇编语言中,操作数通过名称来指定寄存器。这与内存用地址编号来区分不同,CPU 内的寄存器是用 eax、ebx 这类名称来区分的。
5 最常用的 mov 指令
指令中最常用的当属 mov 指令,它负责在寄存器和内存之间移动数据。mov 指令的两个操作数,分别指定数据的存储目的地和读取源。
操作数可以指定为寄存器、常数、标签(附加在地址前),或者用方括号 [] 括起来的上述内容。如果指定了没用方括号括起来的内容,表示直接处理该值;如果指定了用方括号括起来的内容,则方括号内的值会被解释为内存地址,进而对该地址的值进行读写。

在 mov ebp, esp 中,esp 寄存器中的值被直接存储到 ebp 寄存器中。如果 esp 的值是 100,那么 ebp 的值也会变成 100。
而在 mov eax, dword ptr [ebp+8] 中,ebp 的值加上 8 后会被解释为内存地址。如果 ebp 的值是 100,那么 eax 寄存器将存储内存地址 108 处的数据。dword ptr(double word pointer)表示从指定内存地址读取 4 字节的数据。
6 对栈进行 push 和 pop
程序运行时,会在内存上分配一个称为栈的数据空间。正如其名,数据存储时从内存的高地址向低地址堆积(即“向下生长”),读取时则按照从低地址到高地址的顺序进行。
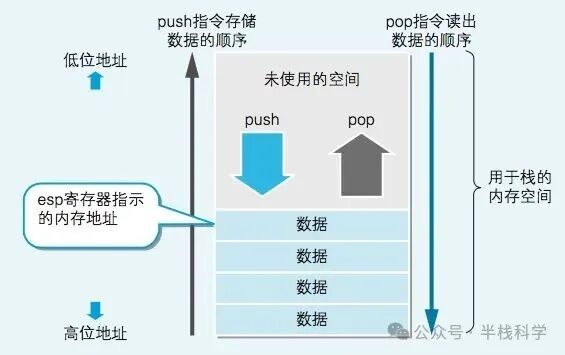
栈是存储临时数据的区域,通过 push 指令和 pop 指令进行数据的存入和读出。 存入数据称为“入栈”,读出数据称为“出栈”。在 32 位 x86 系列 CPU 中,一次 push 或 pop 可以处理 32 位(4 字节)的数据。
栈的读写地址由 esp 寄存器(栈指针)管理。 push 和 pop 指令执行后,esp 寄存器的值会自动更新(push 时减 4,pop 时加 4),因此程序员无需手动指定内存地址。
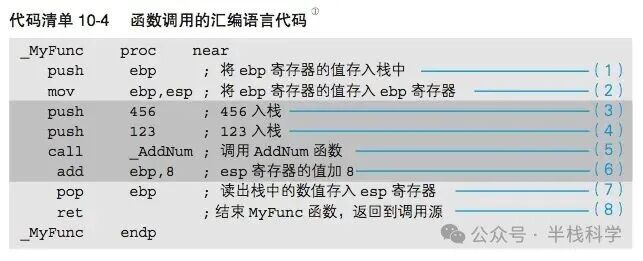
7 函数调用机制
在高级语言中,函数调用看起来很简单,但在汇编层面,它涉及一系列精心设计的栈操作。以下是函数调用的汇编语言代码示例。
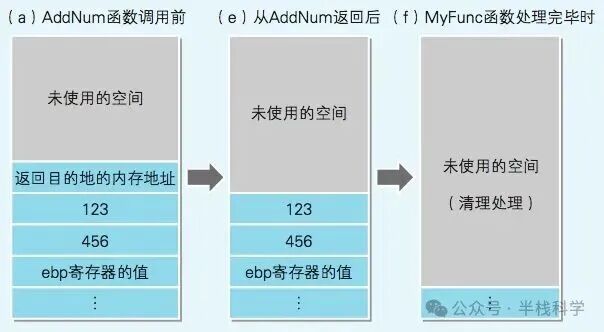
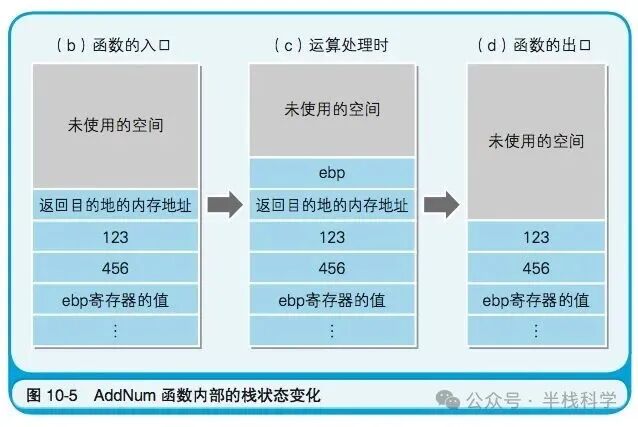
整个过程伴随着栈空间的动态变化,下图展示了关键节点的栈状态。
8 函数内部的处理
函数被调用后,其内部同样需要处理参数、局部变量并返回结果。下面的代码展示了一个加法函数内部的汇编实现。

这印证了一个重要约定:“函数的参数通过栈传递,而返回值通常通过寄存器(如 eax)返回。”
函数内部执行时,栈空间会进一步被用于保存现场和分配局部变量,其状态变化如下图所示。
9 始终确保全局变量用的内存空间
在 C 语言中,在函数外部定义的变量称为全局变量,在函数内部定义的变量称为局部变量。了解它们在汇编层面的实现,是深入理解内存管理的关键。


将上述 C 代码转换成汇编语言后,全局变量的定义和初始化会体现在特定的段中。
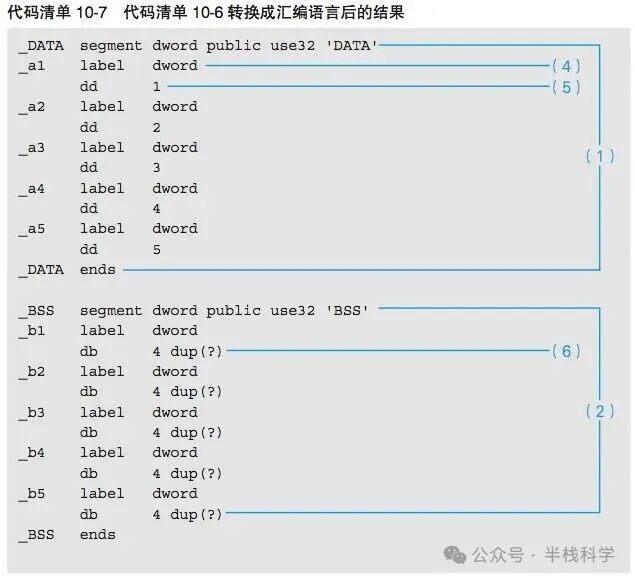
而函数中对这些变量的操作,则转换为对固定内存地址的读写指令。如果你对这类底层交互的细节感兴趣,可以在云栈社区找到更多深入的讨论和资源。

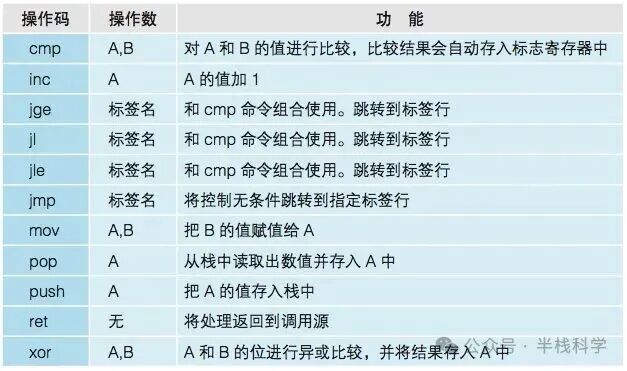
以下是上述及后续代码中出现的一些汇编指令功能说明。

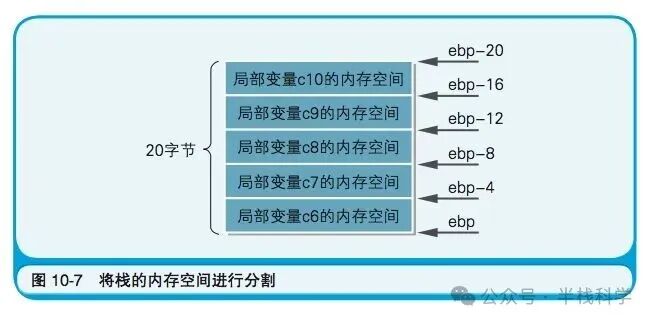
10 临时确保局部变量用的内存空间
与全局变量在程序启动时就分配好内存不同,局部变量的内存空间是临时的,通常在函数被调用时在栈上分配,函数返回时释放。下图清晰地展示了这个过程。
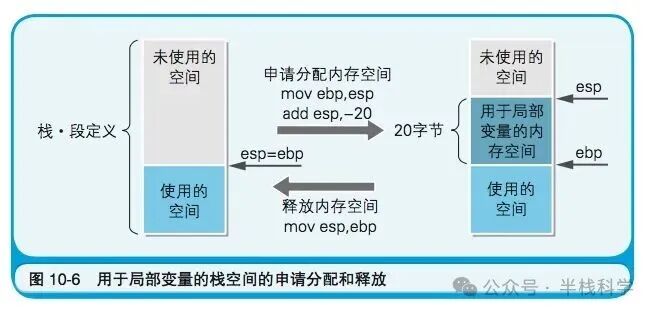
通过调整栈指针 esp,函数为自己预留出一块空间。这块空间随后被分割,用于存放各个局部变量。
11 循环处理的实现方法
高级语言中的循环结构,在汇编层面是通过标签跳转和条件判断指令组合实现的。例如,一个简单的 for 循环会被转换成以下形式。

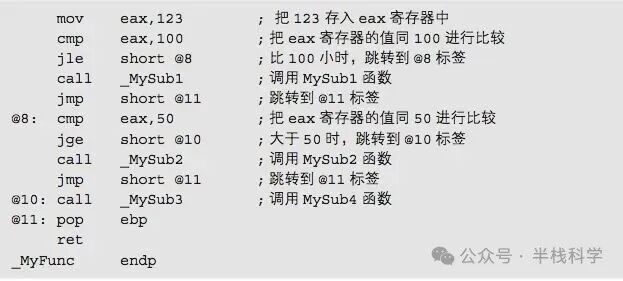
12 条件分支的实现方法
同样,if-else 这类条件分支语句,在汇编中依赖 cmp(比较)指令和一系列条件跳转指令(如 jle, jge, jmp)来完成逻辑判断和流程控制。这属于后端其他语言实现中常见的控制流转换模式。

下面的汇编代码展示了条件分支的具体实现方式。

 发表于 2026-1-10 09:44:17
|
查看: 240|
回复: 0
发表于 2026-1-10 09:44:17
|
查看: 240|
回复: 0
