文件系统一致性是存储系统的生命线。当系统突然掉电或崩溃时,如果不能保证数据结构的完整性,轻则丢失用户数据,重则文件系统彻底损坏。这就是为什么 Linux 文件系统需要复杂的一致性保证机制。
本文深入探讨 Linux 文件系统如何面对这个挑战:从最初的同步写入到现代的 Journaling 机制,从元数据保护到数据完整性校验。我们会剖析 ext4、Btrfs、XFS 等主流文件系统的实现细节,揭示它们如何在性能和安全之间找到平衡点。通过理解这些底层机制,你会认识到看似简单的“文件操作”背后有多少工程智慧。
核心概念详解
什么是文件系统一致性
文件系统一致性指的是磁盘上的数据结构和内存中的视图保持同步,满足特定的不变式(invariants)。简单理解就是:无论何时中断,文件系统都能恢复到一个合法的状态。
比如,当你删除一个文件时,需要同时更新三处地方:
- inode 位图(标记该 inode 为空闲)
- 数据块位图(标记数据块为空闲)
- 父目录项(删除目录条目)
如果只完成了其中一两步就掉电,文件系统就进入了不一致状态:可能 inode 仍被标记为占用,但对应的数据块已被清空,导致垃圾文件占据磁盘空间。
三类一致性问题
元数据不一致:位图、inode、超级块等管理结构出现矛盾。这是最严重的,会导致文件系统彻底崩坏。
数据泄露:已删除文件的数据块未被正确释放,残留数据可能被新文件覆盖,造成信息泄露。
数据损坏:文件内容被不完整的写入中断,导致文件数据不完整或乱码。
Journaling 的基本思想
想象你在账本上记账。传统方式是直接修改账本,结果掉电了,数据一半没写。更聪明的办法是先在日志本上记录“要做什么”,然后再执行,最后在日志上打个勾。即使中途掉电,恢复时只需扫描日志本就知道该做什么。
文件系统 Journaling 的原理完全一样:在真正修改磁盘数据前,先把这次操作的所有变更写进一个 journal 日志区域。journal 采用循环写入,一旦操作成功确认,该日志项就可被覆盖。
Ordered vs Writeback vs Data Journal
Ordered 模式(ext4 默认):
- 元数据修改进日志
- 用户数据先写,再更新元数据
- 这样即使元数据成功提交但数据未写,至少数据本身是完整的
Writeback 模式:
- 只有元数据进日志
- 用户数据写入没有特殊顺序保证
- 最快,但数据文件可能看到旧数据(虽然元数据一致)
Data Journal 模式:
- 所有变更(包括用户数据)都进日志
- 最安全,但 journal I/O 翻倍,性能最差
实现机制深度剖析
数据结构
Journal 日志结构
// Linux 内核 journal 核心数据结构
typedef struct journal_s {
unsigned long j_flags; // 日志状态标志
unsigned long j_total_len; // 日志总大小(块数)
unsigned long j_blk_offset; // 日志在磁盘上的偏移
struct mutex j_checkpoint_mutex; // 检查点保护
struct buffer_head *j_sb_buffer; // 超级块缓冲
journal_superblock_t *j_superblock; // 日志超级块
spinlock_t j_list_lock; // 保护事务列表
struct journal_head *j_checkpoint_transactions;
unsigned long j_tail; // 日志尾部指针
unsigned long j_tail_sequence; // 尾部序列号
unsigned long j_transaction_sequence; // 事务序列号
wait_queue_head_t j_wait_transaction_locked; // 事务锁等待队列
} journal_t;
关键字段解释:
j_flags: 记录日志是否启用、是否需要恢复等状态j_tail、j_transaction_sequence: 日志指针环形队列的关键,防止日志覆盖未确认的项j_checkpoint_mutex: 保护检查点操作,确保日志安全回收
事务结构
// 事务描述结构
typedef struct transaction_s {
journal_t *t_journal; // 所属日志
unsigned long t_tid; // 事务ID
unsigned int t_state; // 事务状态
unsigned long t_log_start; // 在日志中的起始位置
struct buffer_head *t_descriptor_buffer; // 事务描述符块
struct journal_head *t_buffers; // 该事务包含的buffer_head链表
struct journal_head *t_checkpoint_list; // 检查点列表
struct journal_head *t_inode_list; // inode列表
spinlock_t t_handle_lock; // 保护handle计数
int t_updates; // 未提交的handle数
__u32 t_log_csum; // 日志校验和(防止日志损坏)
} transaction_t;
buffer_head 的 journal 扩展
// 每个缓冲块都可能属于日志事务
struct journal_head {
struct buffer_head *b_bh; // 指向实际缓冲
transaction_t *b_transaction; // 所属事务(运行中)
transaction_t *b_next_transaction; // 下一个事务(排队中)
unsigned int b_jlist; // 在事务中的位置(metadata/data/revoke)
unsigned long b_modified; // 修改标记
};
数据流向与操作序列
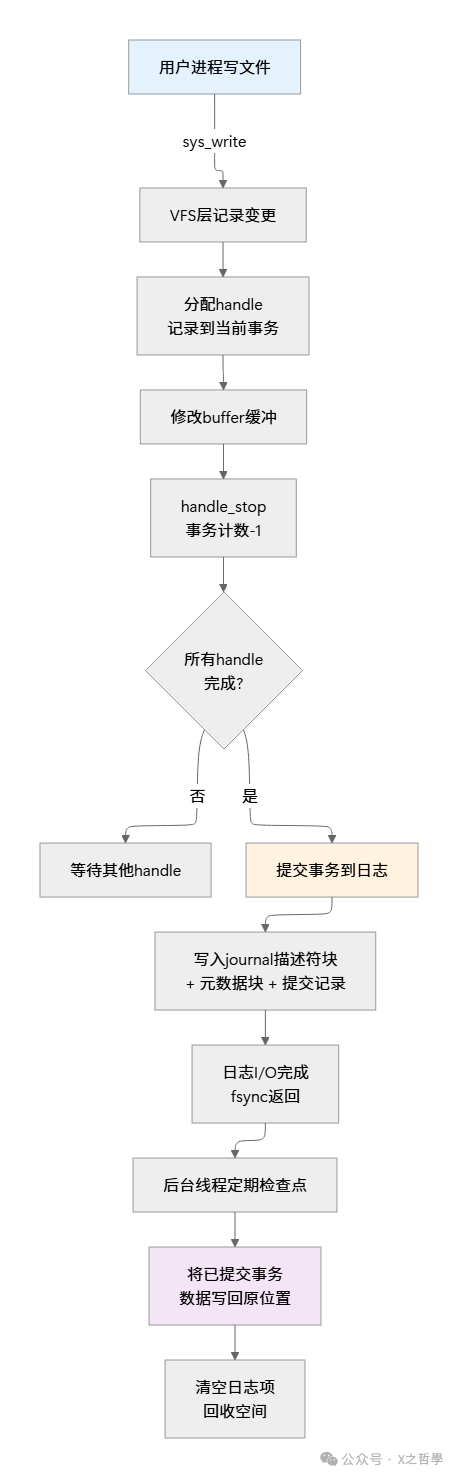
内存布局与 Journal 循环队列
(原图包含引流信息,已根据优化规则删除)
核心算法:事务生命周期
第1阶段:Running - 事务运行
// 内核代码简化版
handle_t *ext4_journal_start(struct inode *inode, int blocks) {
journal_t *journal = EXT4_JOURNAL(inode->i_sb);
transaction_t *transaction;
// 获取当前事务或创建新事务
spin_lock(&journal->j_state_lock);
transaction = journal->j_running_transaction;
if (!transaction) {
// 没有运行事务, 创建新的
transaction = kzalloc(sizeof(transaction_t), GFP_NOFS);
transaction->t_tid = ++journal->j_transaction_sequence;
transaction->t_state = T_RUNNING;
journal->j_running_transaction = transaction;
}
// 分配handle, 这允许多个进程并发修改
handle_t *handle = kzalloc(sizeof(handle_t), GFP_NOFS);
handle->h_transaction = transaction;
transaction->t_updates++; // 增加handle计数
spin_unlock(&journal->j_state_lock);
return handle;
}
第2阶段:Locked - 事务锁定(准备提交)
// 停止接收新handle, 准备提交
int ext4_journal_stop(handle_t *handle) {
transaction_t *transaction = handle->h_transaction;
spin_lock(&transaction->t_handle_lock);
transaction->t_updates--; // handle计数递减
if (transaction->t_updates == 0 &&
transaction->t_state == T_RUNNING) {
// 最后一个handle, 转移到锁定状态
transaction->t_state = T_LOCKED;
// 不再接收新的handle加入此事务
journal->j_running_transaction = NULL;
}
spin_unlock(&transaction->t_handle_lock);
return 0;
}
第3阶段:Commit - 提交到日志
这一步是 Journaling 的核心,分为多个子步骤:
// 这是最关键的一步:保证日志写入
int journal_commit_transaction(journal_t *journal) {
transaction_t *commit_transaction = journal->j_committing_transaction;
struct journal_head *jh;
int err;
// 步骤1:写事务描述符块
// 这告诉恢复代码“一个新事务开始了”
write_buffer_to_journal(commit_transaction->t_descriptor_buffer);
journal_wait_on_commit_record(journal); // 等待写入完成
// 步骤2:写所有元数据块(可能并发)
journal_submit_data_buffers(journal, commit_transaction);
journal_wait_on_data_buffers(journal); // 等待所有数据块写完
// 步骤3:写提交块(关键点!)
// 一旦这个块写到磁盘, 事务即可被认为已成功提交
// 恢复时, 只需扫描已有提交块的事务即可重做
write_commit_block(commit_transaction);
journal_wait_on_commit_record(journal);
// 步骤4:标记为已提交, 准备回收
commit_transaction->t_state = T_FINISHED;
return 0;
}
第4阶段:Checkpoint - 检查点和回收
// 后台定期运行, 将已提交事务的数据写回原位置
int journal_do_checkpoint(journal_t *journal) {
struct journal_head *jh;
transaction_t *transaction;
// 遍历已完成的事务
transaction = journal->j_checkpoint_transactions;
while (transaction) {
jh = transaction->t_buffers;
while (jh) {
// 写回buffer到原位置
if (buffer_dirty(jh->b_bh)) {
sync_dirty_buffer(jh->b_bh);
}
// 从事务中移除此buffer
__journal_unfile_buffer(jh);
jh = jh->b_tnext;
}
// 整个事务都写回了, 可以回收日志空间
__journal_drop_transaction(journal, transaction);
transaction = transaction->t_next;
}
return 0;
}
崩溃恢复机制
系统启动时运行 fsck 的日志恢复阶段。关键思路是:只重新执行那些已经提交到日志的事务。
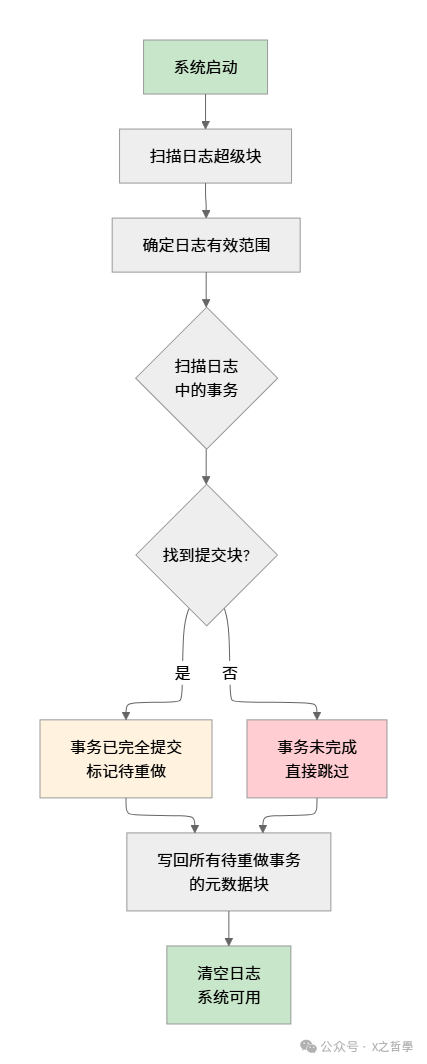
// 恢复过程的核心函数
int journal_recover(journal_t *journal) {
journal_superblock_t *sb = journal->j_superblock;
struct buffer_head *bh;
unsigned long next_log_block;
// 确定恢复范围
next_log_block = be32_to_cpu(sb->s_start);
if (next_log_block == 0)
return 0; // 日志为空, 无需恢复
printk(KERN_INFO "journal: recovering from log %lu to %lu\n",
next_log_block, be32_to_cpu(sb->s_maxlen));
// 扫描所有日志块
while (next_log_block != journal->j_tail) {
bh = journal_get_descriptor_buffer(journal, next_log_block);
if (!is_valid_descriptor(bh)) {
// 无效的描述符块, 扫描停止
break;
}
// 扫描此事务的所有块
journal_scan_transaction(journal, next_log_block, bh);
next_log_block++;
}
// 重做所有已识别的事务
journal_do_redo_transactions(journal);
return 0;
}
数据完整性的关键保证
1. 顺序写入保证(Write Ordering)
文件系统必须按正确的顺序写入数据和元数据,利用内存屏障保证:
// 伪代码演示关键的写入顺序
void write_with_ordering(struct buffer_head *meta, struct buffer_head *data) {
// 1. 先写用户数据(在ordered模式下)
write_buffer(data);
smp_wmb(); // 内存写屏障, 保证前面的写完成
// 2. 再写元数据(元数据进日志)
journal_add_buffer(meta);
fsync_journal();
// 3. 最后写日志提交块
write_commit_block();
smp_wmb();
// 现在即使掉电, 恢复时也能保证一致性
}
2. 校验和机制
// ext4 中的校验和计算
static __u32 journal_calculate_csum(transaction_t *commit_transaction) {
struct journal_head *jh;
__u32 csum = journal->j_csum_seed;
// 遍历事务中的所有块
for (jh = commit_transaction->t_buffers; jh; jh = jh->b_tnext) {
// 使用CRC32计算块的校验和
csum = crc32_le(csum, (const void *)jh->b_bh->b_data,
jh->b_bh->b_size);
}
return csum;
}
设计思想与架构
为什么需要 Journaling
早期的 Linux 文件系统(如 ext2)完全同步写入所有数据。这意味着删除一个文件需要同步更新多个磁盘块,性能极差。而且任何时刻掉电都可能造成不一致,需要运行耗时的 fsck 检查。
Journaling 的优雅之处在于:
- 性能:只需同步写入日志(顺序 I/O,很快),元数据回写可异步进行
- 可靠性:即使频繁掉电,也只需扫描日志恢复,不需要全盘扫描
- 一致性:通过事务模型保证原子性,要么全部成功,要么全不成功
各主流文件系统的方案对比
| 特性 |
ext4 |
Btrfs |
XFS |
| 日志类型 |
块级 Journaling |
Copy-on-Write |
文件系统 Journal |
| 元数据保护 |
Journaling |
CoW + 校验和 |
Journal |
| 用户数据保护 |
可选 Data Journal |
CoW |
无(需配置fsync) |
| 性能 |
中等 |
低(CoW开销) |
高 |
| 恢复时间 |
秒级 |
无需恢复 |
秒级 |
| 复杂度 |
中等 |
高 |
高 |
Btrfs 的 CoW 方案:不用日志,而是通过 Copy-on-Write 天然保证一致性。修改任何块前,先写到新位置,再更新指针。但这引入碎片化和 RAID1 同步问题。
XFS 的高性能方案:使用日志保护元数据,但对用户数据不保护(除非明确 fsync),依赖文件系统级别的聚合操作保证一致性。
设计权衡
Ordered vs Data Journal:
- Ordered 模式平衡性能和安全性,是 ext4 默认选择
- Data Journal 最安全但性能损失大(日志 I/O 翻倍),仅在对数据安全性要求极高时使用
同步 vs 异步日志:
- 同步日志(fsync 等待提交块写入):安全,但延迟大
- 异步日志(只等待日志空间分配):快速,但掉电前的少数操作可能丢失
- 现代系统通常用异步日志,关键操作(如删除)再加 fsync
日志大小设置:
- 日志过小:容易满,导致频繁阻塞
- 日志过大:恢复慢,占用空间
- 最优值取决于工作负载,通常为磁盘大小的 0.1% - 1%
实践示例
场景:观察 ext4 日志操作
这个示例演示如何在实际系统上观察和验证 ext4 日志的行为。
#!/bin/bash
# 1. 创建有日志的 ext4 文件系统
dd if=/dev/zero of=test_disk.img bs=1M count=100
mkfs.ext4 -J test_disk.img
# 2. 挂载并设置跟踪
mkdir -p /mnt/test
mount -o loop test_disk.img /mnt/test
# 3. 启用内核跟踪以观察日志活动
echo 1 > /proc/sys/kernel/trace_enable
cat > /tmp/trace_events << 'EOF'
ext4:ext4_journal_start
ext4:ext4_journal_stop
ext4:ext4_journal_commit
EOF
while read event; do
echo 1 > /sys/kernel/debug/tracing/events/$event/enable
done < /tmp/trace_events
# 4. 在跟踪状态下执行文件操作
cd /mnt/test
touch testfile.txt
echo "hello world" > testfile.txt
rm testfile.txt
# 5. 查看跟踪输出
cat /sys/kernel/debug/tracing/trace | grep -E "ext4_journal"
预期输出解释:
ext4_journal_start:新建写操作时出现,显示分配的 handleext4_journal_stop:写操作完成,handle 释放,可能触发事务提交ext4_journal_commit:事务被提交到日志
代码示例:检查日志状态
#include <stdio.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <linux/fs.h>
#include <linux/ext4_fs.h>
int main(int argc, char *argv[]) {
int fd;
struct ext4_super_block sb;
if (argc < 2) {
fprintf(stderr, "Usage: %s <device>\n", argv[0]);
return 1;
}
// 打开设备
fd = open(argv[1], O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
// 读取超级块
lseek(fd, 1024, SEEK_SET);
if (read(fd, &sb, sizeof(sb)) != sizeof(sb)) {
perror("read superblock");
return 1;
}
// 检查日志状态
printf("Journal Inode: %u\n", sb.s_journal_inum);
printf("Journal Device: 0x%x\n", sb.s_journal_dev);
printf("Journal Backup: %u\n", sb.s_backup_bgs[0]);
if (sb.s_feature_compat & EXT4_FEATURE_COMPAT_HAS_JOURNAL) {
printf("Status: Journal enabled\n");
} else {
printf("Status: Journal disabled\n");
}
// 检查是否需要日志恢复
if (sb.s_state & EXT4_ERROR_FS) {
printf("WARNING: Filesystem had errors, recovery needed\n");
}
close(fd);
return 0;
}
/*
编译运行:
gcc -o check_journal check_journal.c
sudo ./check_journal /dev/sda1
预期输出:
Journal Inode: 8
Journal Device: 0x0
Journal Backup: 0
Status: Journal enabled
*/
模拟日志恢复场景
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <signal.h>
#include <sys/mman.h>
volatile int should_exit = 0;
void signal_handler(int sig) {
should_exit = 1;
}
int main() {
char *filename = "/tmp/journal_test.txt";
int fd;
char buffer[4096] = "Journal test data with intentional interruption\n";
// 注册信号处理
signal(SIGTERM, signal_handler);
signal(SIGINT, signal_handler);
fd = open(filename, O_CREAT | O_RDWR | O_TRUNC, 0644);
if (fd < 0) {
perror("open");
return 1;
}
// 模拟长时间写入
for (int i = 0; i < 1000; i++) {
if (should_exit) {
printf("Interrupted at iteration %d\n", i);
break;
}
// 多次小写入, 增加被中断的概率
if (write(fd, buffer, sizeof(buffer)) < 0) {
perror("write");
break;
}
// 每10次迭代进行一次同步
if (i % 10 == 0) {
fsync(fd);
printf("Checkpoint at iteration %d\n", i);
}
usleep(100000); // 100ms 延迟, 留出中断机会
}
// 正常关闭
fsync(fd);
close(fd);
// 显示文件大小
struct stat st;
stat(filename, &st);
printf("Final file size: %ld bytes\n", st.st_size);
return 0;
}
/*
编译运行:
gcc -o journal_interrupt journal_interrupt.c
./journal_interrupt &
sleep 2
kill %1
结果分析:
- 如果接收到 SIGTERM, 程序记录中断位置
- fsync() 确保已写数据持久化
- 最终文件大小应该是写入的整数倍数据块
*/
工具与调试
| 工具/命令 |
用途 |
示例 |
debugfs |
检查日志和 inode 信息 |
debugfs -R "stat <inode>" /dev/sda1 |
tune2fs |
查看/修改日志参数 |
tune2fs -l /dev/sda1 \| grep -i journal |
e2image |
备份/恢复文件系统 |
e2image -r /dev/sda1 backup.img |
fsck.ext4 |
离线检查和修复 |
fsck.ext4 -n /dev/sda1 (只读模式) |
ftrace |
跟踪内核文件系统调用 |
trace-cmd record -e ext4:ext4_journal_start |
blktrace |
跟踪块设备 I/O |
blktrace -d /dev/sda1 -o - \| blkparse |
实用调试技巧:
# 1. 查看当前日志状态
tune2fs -l /dev/sda1 | grep -E "journal|Journal"
# 2. 强制日志恢复(卸载后)
fsck.ext4 -f /dev/sda1
# 3. 用 debugfs 查看特定 inode 的日志状态
debugfs -R "stat <12>" /dev/sda1
# 4. 实时监控日志压力
watch -n 1 'cat /proc/fs/ext4/*/mb_groups | head -20'
# 5. 禁用日志(仅用于测试)
tune2fs -O ^has_journal /dev/sda1
# 6. 使用 strace 跟踪系统调用
strace -e openat,write,fsync,fallocate -f dd if=/dev/zero of=/tmp/test.img bs=1M count=100
架构总览
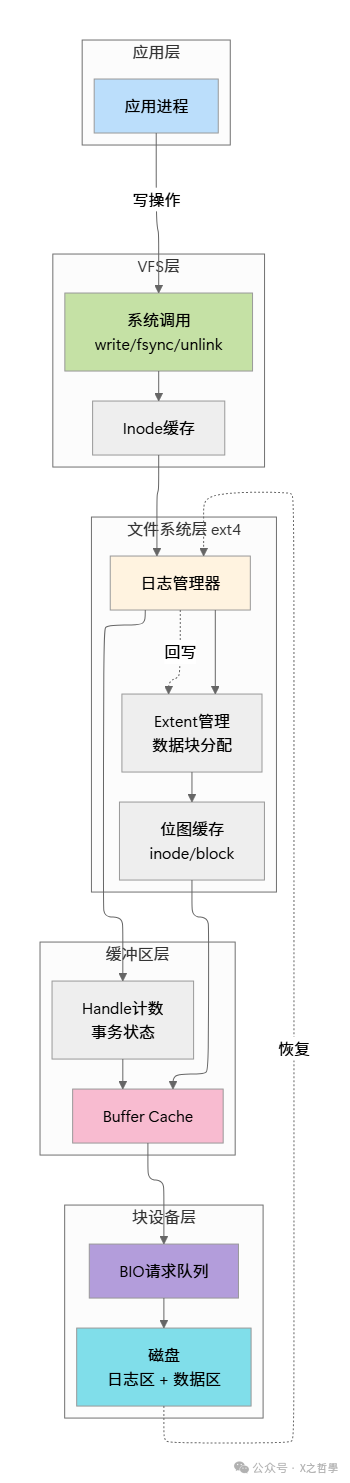
分层说明:
- 应用层:用户程序发起 write/fsync/unlink 等系统调用
- VFS层:通用虚拟文件系统接口,屏蔽文件系统差异
- 文件系统层:ext4 特定逻辑,处理 Journaling、extent、位图等
- 缓冲区层:内存缓冲管理,决定何时真正写入磁盘
- 块设备层:与硬件交互,管理 I/O 队列和调度
数据流:
- 写入路径:应用 → VFS → ext4 → Journal → Buffer Cache → 磁盘
- 恢复路径:掉电后 → 扫描日志 → 重做已提交事务 → 系统可用
全文总结
Linux 文件系统一致性问题是一个经典的工程难题,涉及多个层面的权衡:
| 维度 |
挑战 |
解决方案 |
| 可靠性 |
掉电/崩溃导致数据不一致 |
Journaling 记录操作日志,宕机后快速恢复 |
| 性能 |
同步写入效率太低 |
异步日志 + 定期 checkpoint,日志只记录元数据 |
| 复杂性 |
并发事务管理困难 |
Handle 计数模型允许多个进程并发修改同一事务 |
| 正确性 |
元数据和数据顺序错乱 |
写入顺序保证 + 内存屏障 + 校验和 |
关键洞察:
- 最小原子单位:事务而非单个操作,通过日志保证原子性
- 异步回写:日志只记录变更,真实回写可延迟,大幅提升性能
- 快速恢复:不需要扫描全盘,只扫描日志,秒级恢复
- 隔离设计:日志区和数据区隔离,降低相互干扰
虽然 Journaling 增加了复杂性,但为现代文件系统带来了既可靠又高效的设计。理解这些机制,不仅能帮助你配置更安全的存储系统,也能在性能调优时做出更明智的决策。比如在嵌入式系统中,你可能会禁用日志以节省空间;而在关键业务系统中,可以启用 Data Journal 模式以获得最高的数据保护等级。
深入研究这些网络与系统底层原理,对于构建高可用的基础设施至关重要。如果你对文件系统、内核机制等计算机基础有更多兴趣,欢迎在云栈社区与更多开发者交流探讨。
 发表于 2026-1-10 16:24:43
|
查看: 172|
回复: 0
发表于 2026-1-10 16:24:43
|
查看: 172|
回复: 0
