在构建分布式监控系统时,理解主从架构是关键。传统监控工具如Zabbix通常以分钟级间隔采集数据,可能错过瞬时性能波动,而Netdata默认以秒级精度捕获系统指标,更适合诊断突发故障。
主从架构解析
监控集群采用流式传输模式,逻辑分为两类节点:
- 主节点(Master):集中接收、存储和展示所有从节点数据
- 从节点(Slave):负责本地数据采集,实时推送至主节点
这种架构显著降低从节点资源消耗,避免历史数据本地存储。
环境部署
所有节点均需安装Netdata,推荐直接使用官方脚本在物理机部署:
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
安装完成后开放防火墙19999端口,通过http://服务器IP:19999访问控制台。
主节点配置
-
生成API密钥作为身份凭证:
uuidgen
# 输出示例:e1540a6c-f179-476f-813d-d0c46000eb15
-
修改流式传输配置:
cd /etc/netdata
./edit-config stream.conf
添加以下配置段:
[e1540a6c-f179-476f-813d-d0c46000eb15]
enabled = yes
default history = 3600
default memory mode = dbengine
health enabled by default = auto
allow from = *
关键参数说明:
dbengine模式将数据压缩存储至磁盘,大幅降低内存占用allow from支持IP段限制增强安全性
-
重启服务生效:
systemctl restart netdata
从节点配置
-
配置数据推送目标:
cd /etc/netdata
./edit-config stream.conf
修改流式传输段:
[stream]
enabled = yes
destination = 192.168.198.133:19999
api key = e1540a6c-f179-476f-813d-d0c46000eb15
timeout seconds = 60
default port = 19999
send charts matching = *
buffer size bytes = 1048576
reconnect delay seconds = 5
initial clock resync iterations = 60
-
关闭本地存储避免资源浪费:
./edit-config netdata.conf
设置全局存储模式:
[global]
memory mode = none
-
重启从节点服务完成配置。
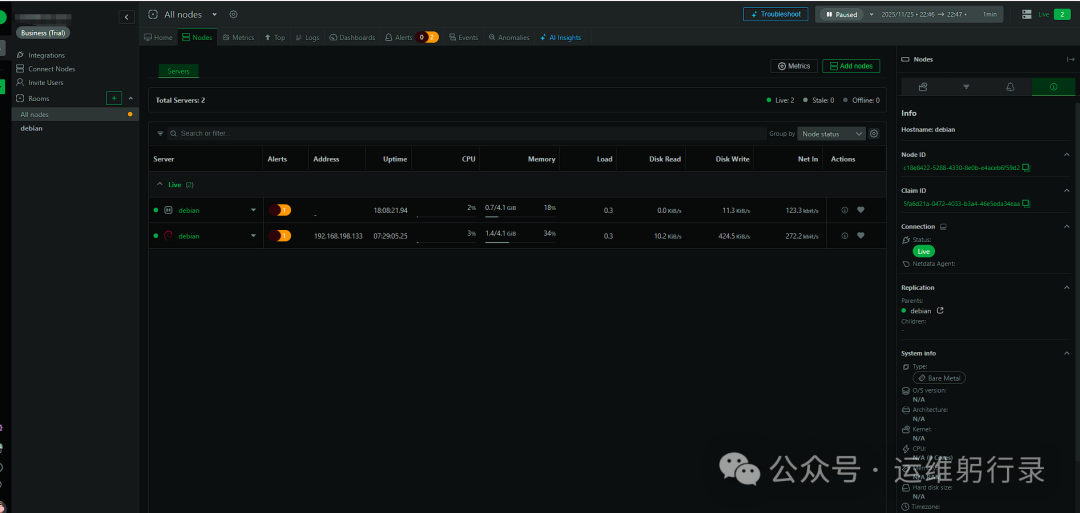
集群验证
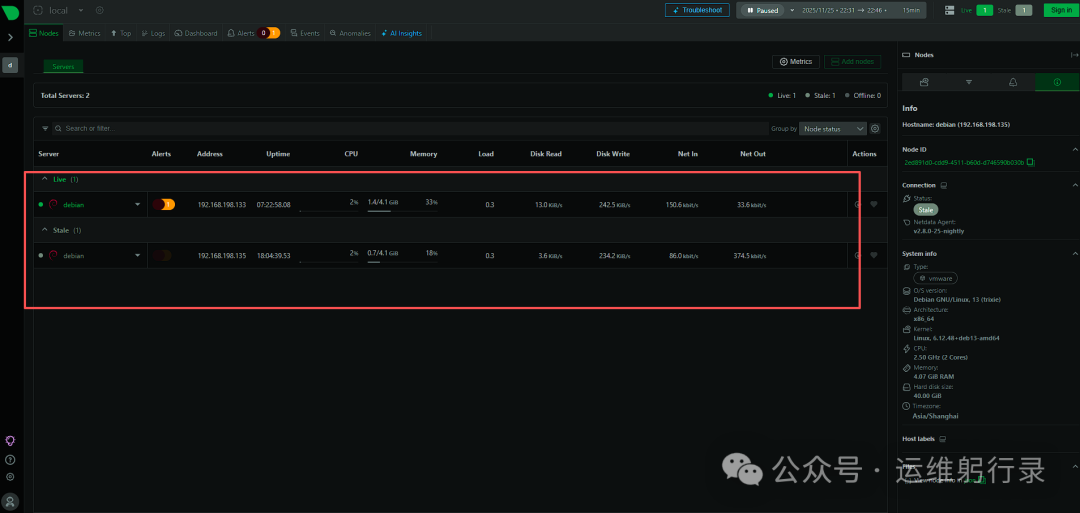
访问主节点控制台,左上角主机列表将显示所有已连接的从节点。点击任意主机即可查看其完整监控指标,实现统一监控界面。
告警集成方案
Netdata内置丰富告警规则,可通过以下方式扩展通知渠道:
-
修改告警配置启用自定义发送器:
./edit-config health_alarm_notify.conf
设置参数:
SEND_CUSTOM="YES"
-
通过Prometheus导出器实现生态集成:
- Netdata提供Prometheus格式数据接口
- 结合Alertmanager构建成熟告警流水线
- 保留秒级采集优势的同时复用Prometheus存储体系
常见问题处理
- 时间同步异常:主从节点时间差超过阈值会导致数据异常,需配置NTP服务保持时钟同步
- 节点标识冲突:虚拟机克隆场景需重置Netdata机器ID,避免数据混淆
- 资源占用优化:禁用未使用的采集插件(如未部署的数据库服务),通过
edit-config调整插件配置
技术优势总结
- 采集精度:秒级粒度捕获系统瞬时状态
- 资源效率:流式架构减少从节点存储开销
- 扩展灵活:支持水平扩展至数百节点
- 生态兼容:原生支持主流监控生态集成
通过合理配置,Netdata可成为分布式系统监控的核心组件,为性能优化和故障诊断提供高精度数据支撑。 |  发表于 2025-11-28 00:50:08
|
查看: 232|
回复: 0
发表于 2025-11-28 00:50:08
|
查看: 232|
回复: 0
