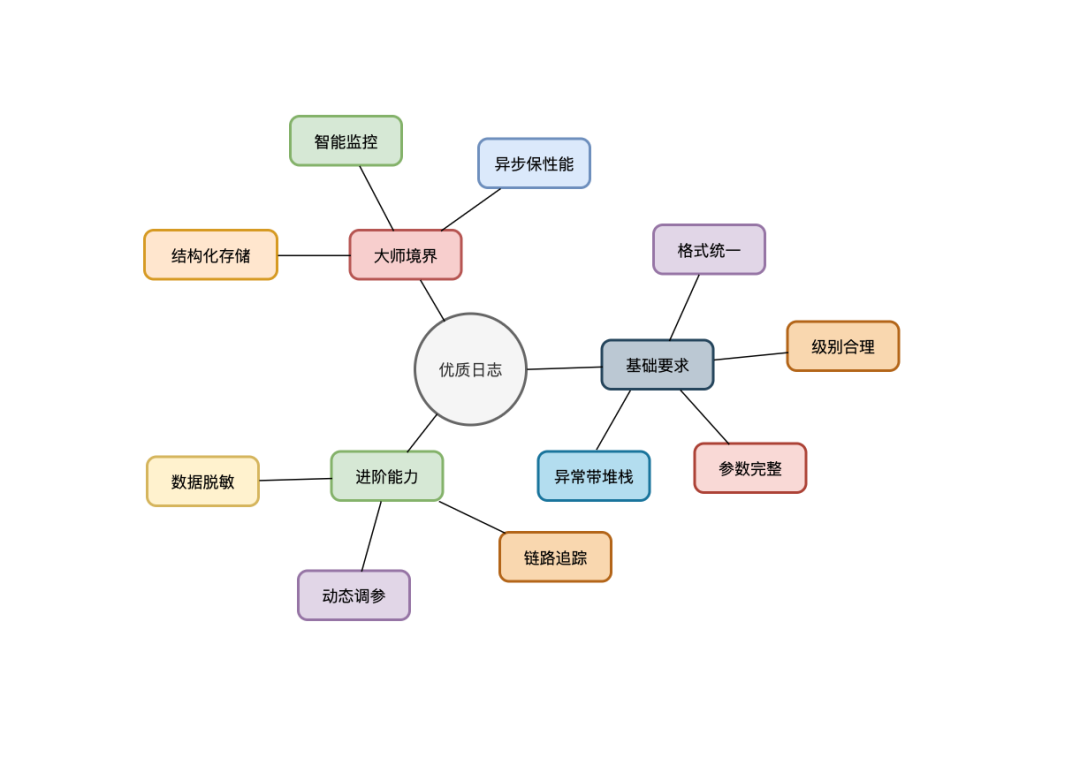
你是否曾因线上系统出问题,面对满屏杂乱无章的日志感到无从下手?一个优秀的日志系统,是快速定位问题、保障系统稳定性的基石。本文将为你梳理十条关于日志打印的黄金法则,涵盖从基础规范到高级实践,助你构建清晰、高效、安全的日志体系。
第1条:格式统一
反面示例:
log.info("start process");
log.error("error happen");
这样的日志缺少时间戳、线程信息、TraceID等关键上下文,一旦出现问题,排查如同大海捞针。
正确做法:
统一的日志格式是高效排查的前提。应在日志框架的配置文件中进行全局设定。例如,在 logback.xml 中配置一个清晰的结构化格式:
<!-- logback.xml核心配置 -->
<pattern>
%d{yy-MM-dd HH:mm:ss.SSS} <!-- 时间 -->
|%X{traceId:-NO_ID} <!-- 链路ID -->
|%thread <!-- 线程名 -->
|%-5level <!-- 日志级别 -->
|%logger{36} <!-- 日志器名(缩写) -->
|%msg%n <!-- 消息内容 -->
</pattern>
通过以上配置,每一条日志都包含了“时间、链路、线程、级别、来源、内容”六大要素,形成了标准化的信息模板。当问题发生时,运维或开发人员可以快速根据这些结构化信息进行筛选和定位。
第2条:异常必带堆栈
反面示例(严重问题):
try {
processOrder();
} catch (Exception e) {
log.error("处理失败");
}
这种写法完全“吞掉”了异常堆栈,是最危险的日志打印方式之一。你只知道“处理失败”,却完全不知道失败发生在哪一行代码、由什么原因引起。
正确姿势:
捕获异常并记录日志时,务必将异常对象作为最后一个参数传入。
log.error("订单处理异常 orderId={}", orderId, e); // 注意:参数e必须存在!
这样,日志中不仅会记录异常信息,还会打印完整的调用堆栈,直接指向问题根源,这是 Java 异常处理的基本功。
第3条:级别合理
日志级别滥用会严重干扰监控和问题排查。我们需要根据事件的性质严格区分级别。
反面教材:
log.debug("用户余额不足 userId={}", userId); // 业务异常应属WARN
log.error("接口响应稍慢"); // 普通超时属INFO
各级别定义与使用场景参考表:
| 级别 |
正确使用场景 |
| FATAL |
系统即将崩溃(如JVM OOM、磁盘爆满、数据库连接池耗尽) |
| ERROR |
核心业务失败(如支付失败、订单创建异常、关键数据校验不通过) |
| WARN |
可恢复的异常或预期外状态(如重试成功、缓存降级触发、第三方接口偶尔超时) |
| INFO |
关键业务流程节点(如订单状态变更、用户注册成功、重要配置加载完成) |
| DEBUG |
详细的调试信息(如方法入参/出参、中间计算结果、复杂的条件判断路径) |
第4条:参数完整
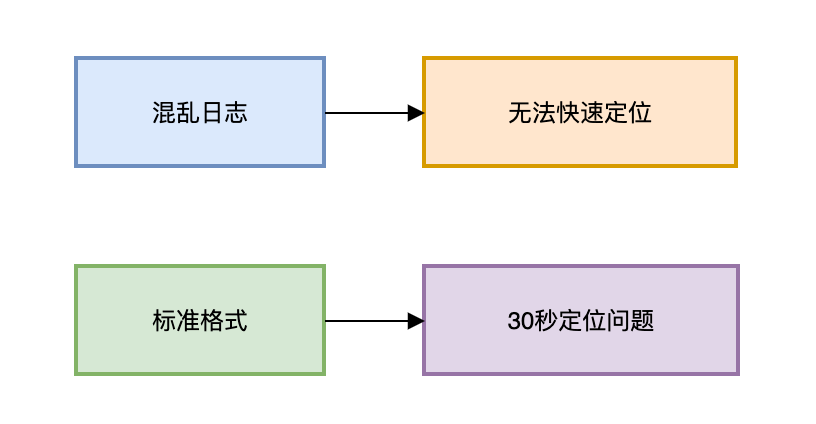
一条孤立的日志消息价值极低。好的日志应该是“侦探式”的,能够还原现场。
反面示例:
log.info("用户登录失败");
这条日志留下了无数疑问:哪个用户?在什么时间?从哪个IP?为什么失败?
侦探式日志:
log.warn("用户登录失败 username={}, clientIP={}, failReason={}",
username, clientIP, "密码错误次数超限");
这样的日志包含了完整的上下文信息(Who, When, Where, Why),结合统一的时间戳格式,能让我们在数十万条日志中快速锁定目标。
第5条:数据脱敏
在记录日志时,必须对用户的敏感个人信息进行脱敏处理,这是合规性的要求,也是对用户隐私的基本尊重。
血泪教训:曾有开发者因在日志中直接打印用户手机号而导致用户投诉及数据泄露风险。
实现方案:
应建立统一的脱敏工具类,在日志打印前对敏感字段进行处理。
// 脱敏工具类
public class LogMasker{
public static String maskMobile(String mobile){
return mobile.replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2");
}
// 可扩展身份证、邮箱、银行卡号等脱敏方法
}
// 使用示例
log.info("用户注册 mobile={}", LogMasker.maskMobile("13812345678"));
// 输出:用户注册 mobile=138****5678
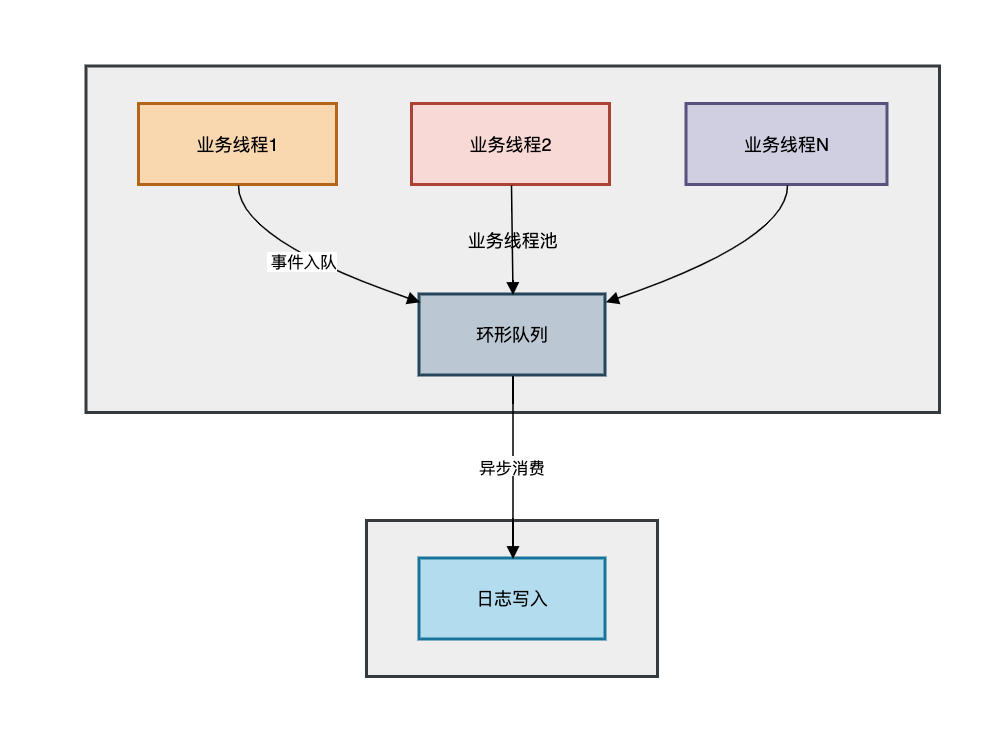
第6条:异步保性能
在高并发场景下,同步写日志(尤其是写文件或网络)可能成为性能瓶颈,因为I/O操作会阻塞业务线程。
问题复现:某次秒杀活动中,大量线程因同步写日志而阻塞。
log.info("秒杀请求 userId={}, itemId={}", userId, itemId); // 高并发下同步I/O是灾难
异步日志配置(以Logback为例):
步骤1:在logback.xml中配置异步Appender
<!-- 异步Appender核心配置 -->
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志的阈值:当队列剩余容量<此值时,TRACE/DEBUG级别日志将被丢弃 -->
<discardingThreshold>0</discardingThreshold>
<!-- 队列深度:建议设为 (最大并发线程数 × 2) -->
<queueSize>4096</queueSize>
<!-- 关联真实Appender -->
<appender-ref ref="FILE"/>
</appender>
步骤2:日志输出优化实践
// 正确:直接打印,由异步框架处理
log.debug("接收到MQ消息:{}", msg.toSimpleString());
// 错误:在日志语句中进行复杂计算,计算过程仍在业务线程中执行!
log.debug("详细内容:{}", computeExpensiveLog()); // computeExpensiveLog()耗时严重
步骤3:关键性能参数公式
最大内存占用 ≈ 队列长度 × 平均单条日志大小
推荐队列深度 = 峰值TPS × 容忍最大延迟(秒)
例如:10000 TPS × 0.5s容忍 ⇒ 5000队列大小
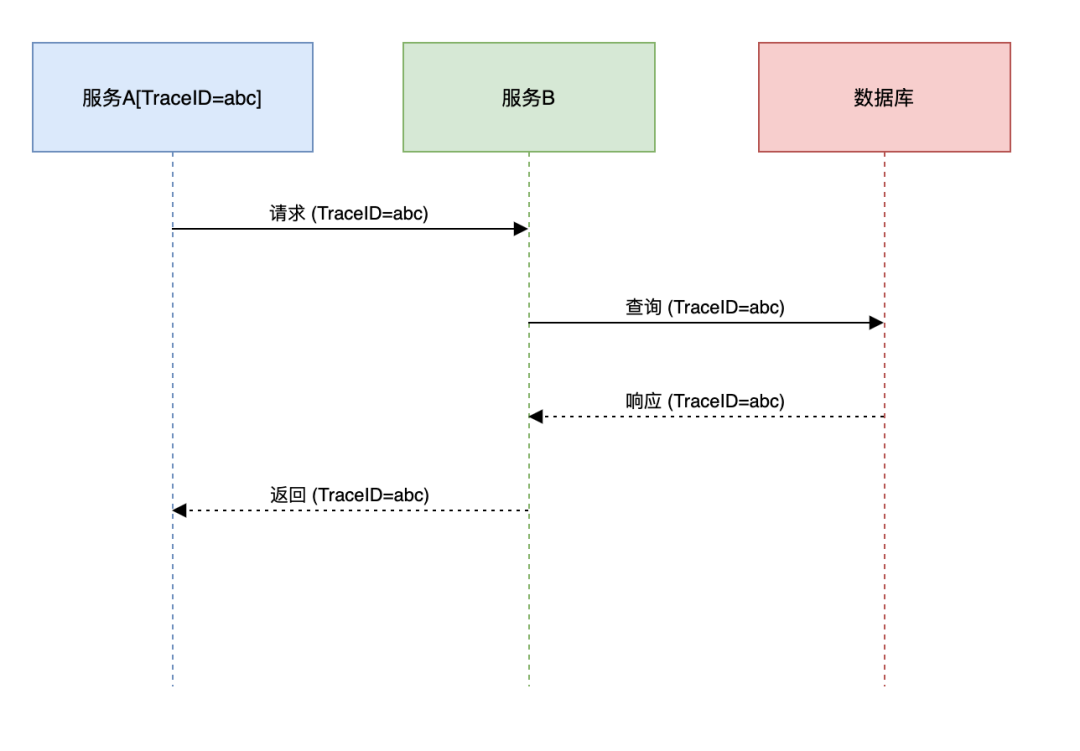
第7条:链路追踪
在微服务或分布式系统中,一个请求可能穿越多个服务。如果没有统一的标识,将无法串联散落在各服务中的日志。
解决方案:引入TraceID
通过拦截器在请求入口生成一个全局唯一的TraceID,并存入 MDC(Mapped Diagnostic Context,线程上下文映射),在日志配置中输出该ID。
1. 拦截器注入TraceID
// 在网关或第一个接收请求的拦截器中
MDC.put("traceId", UUID.randomUUID().toString().substring(0,8));
2. 日志格式包含TraceID
<pattern>%d{HH:mm:ss} |%X{traceId}| %msg%n</pattern>
此后,在请求链路上的任何服务中打印的日志都会携带同一个TraceID。通过这个ID,我们可以在 ELK 或类似日志平台中一键检索出该请求的全部足迹,实现完整的 分布式链路追踪。
第8条:动态调参
线上环境通常将日志级别设为INFO或WARN以控制日志量。但当需要排查复杂问题时,往往需要临时开启DEBUG日志来获取更详细的信息。传统方式需要修改配置并重启应用,可能中断服务。
热更新方案:
通过暴露一个安全的HTTP管理端点(需做好权限控制),实现日志级别的动态调整。
@GetMapping("/logLevel")
public String changeLogLevel(
@RequestParam String loggerName, // 如 “com.example.service”
@RequestParam String level) { // 如 “DEBUG”
Logger logger = (Logger) LoggerFactory.getLogger(loggerName);
logger.setLevel(Level.valueOf(level)); // 立即生效
return "OK";
}
调用 GET /logLevel?loggerName=com.example.service&level=DEBUG 即可实时调整指定包或类的日志级别,无需重启,问题排查完毕后可以再调回原级别。
第9条:结构化存储
传统的纯文本日志虽然对人类可读,但对日志分析系统(Logstash, Fluentd等)并不友好,需要复杂的解析规则(Grok)。
混沌日志示例:
用户购买了苹果手机 订单号1001 金额8999
结构化(JSON)日志:
{
"event": "ORDER_CREATE",
"orderId": 1001,
"amount": 8999,
"products": [{"name": "iPhone", "sku": "A123"}],
"timestamp": "2023-10-27T10:30:00.000Z",
"level": "INFO",
"traceId": "abc123"
}
JSON格式的日志天生是结构化的,每个字段都有明确的键(Key)。这使日志收集系统能够直接提取字段,无需解析,极大地提升了日志查询、聚合分析和仪表盘制作的效率。
第10条:智能监控
日志不应只是事后排查问题的“黑匣子”,更应该成为实时感知系统健康的“仪表盘”。我们需要对错误和异常日志进行监控和告警。
失败案例:错误日志堆积了3天,直到用户大量投诉才发现,为时已晚。
ELK监控方案:
一个典型的流程是:应用日志 -> Filebeat采集 -> Logstash过滤/增强 -> Elasticsearch存储 -> Kibana可视化与告警。
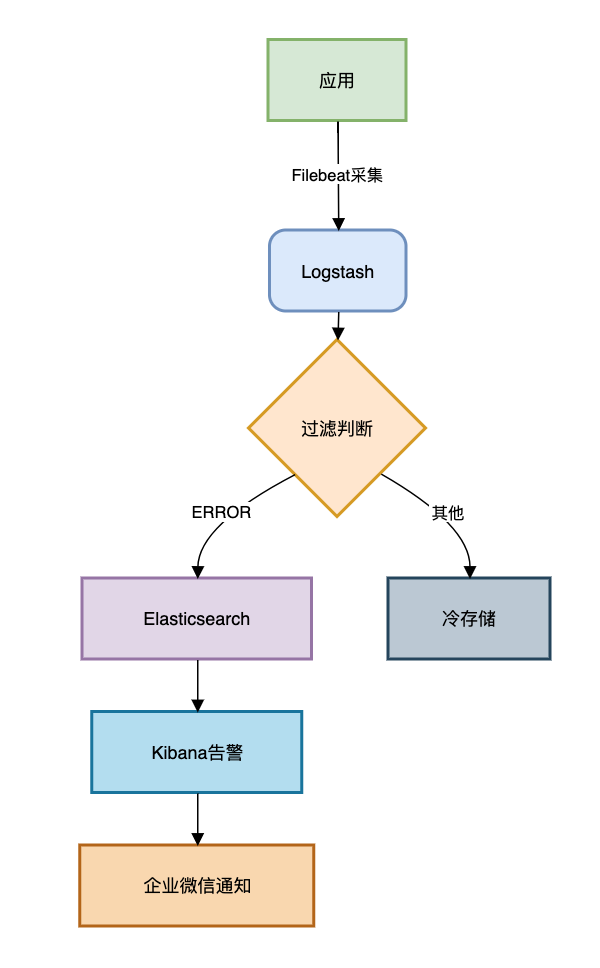
报警规则示例:
- 紧急告警(电话/钉钉/企微):
ERROR级别日志在5分钟内出现超过100次。
- 预警通知(邮件):
WARN级别日志持续出现超过1小时。
- 业务监控:关键业务事件(如“支付成功”)在特定时间段内数量骤降。
通过设定合理的告警规则,我们可以在用户感知之前就发现并响应系统异常。
总结
回顾这十条实践,我们可以将开发人员对日志的认知分为三个境界:
- 青铜:停留在
System.out.println("error!") 的阶段,日志是随意的。
- 钻石:遵循规范,实现了格式统一、异常堆栈、链路追踪,并接入了
ELK 等日志平台进行监控。
- 王者:日志不仅是记录,更是驱动。通过日志分析进行代码优化、构建异常预测系统,甚至利用AI模型进行根因自动分析。
最后,留一个灵魂拷问:当下次线上故障发生时,你留下的日志,能否让一个不熟悉业务的新同事在5分钟内定位到问题根源?
如果你想了解更多关于系统架构、性能优化和开发实践的经验,欢迎来到 云栈社区 与广大开发者一起交流探讨。
 发表于 2026-1-12 05:41:34
|
查看: 191|
回复: 0
发表于 2026-1-12 05:41:34
|
查看: 191|
回复: 0
