在企业网络运维中,你是否遇到过这样一种令人困惑的现象:一台路由器刚连接到核心交换机时一切正常,所有设备都能上网,但仅仅过了几分钟,整个网络突然瘫痪,所有设备都无法访问网络。
当网络突然中断,很多工程师的第一反应往往是怀疑硬件:
- 运营商线路不稳定
- 路由器性能不足
- 核心交换机出现故障

然而在实际的网络故障排查工作中,这类问题大多数并非设备物理损坏,其根源往往是配置错误或网络逻辑层面的问题。
为什么故障会在“几分钟后”出现?
在网络故障诊断中,时间特征是一个非常重要的线索。
- 如果一连接就不通:这通常指向物理链路、IP地址配置或路由表等“硬性错误”。
- 如果能正常使用几分钟后才出问题:这往往与设备的学习、缓存、老化机制以及广播流量有关。
例如:
- MAC地址表的学习过程
- ARP表的老化与刷新
- DHCP租期的交互过程
- 动态路由协议收敛或安全策略的生效
所以,面对这种延迟出现的故障,请先记住一个原则:延迟出现的问题,通常不是物理线路的问题。
先理清网络结构,切勿盲目操作
在开始具体排查之前,务必先厘清当前的网络逻辑结构。你至少需要想明白以下几个问题:
- 路由器的角色是什么?
- 是作为网络出口路由器?
- 还是充当了内网某个网段的网关?
- 核心交换机工作在二层还是三层?
- 是否配置了SVI(VLAN接口)?
- 网络的网关究竟设置在路由器上还是交换机上?
- 故障的具体表现是什么?
- 仅是“无法访问外网”,还是“内网设备间也无法通信”?
- 终端设备能否
ping通自己的网关?
这些问题不需要绘制复杂的拓扑图,但心中必须清晰,否则排查工作很容易迷失方向,越查越乱。
最常见的原因之一:二层环路
二层环路导致网络瘫痪的典型特征就是:
- 刚连接时一切正常,网络可以通行。
- 随着时间的推移,网络中的广播帧开始循环复制,流量指数级增长。
- 最终,网络设备CPU负载过高,带宽被广播风暴占满,导致全网瘫痪。
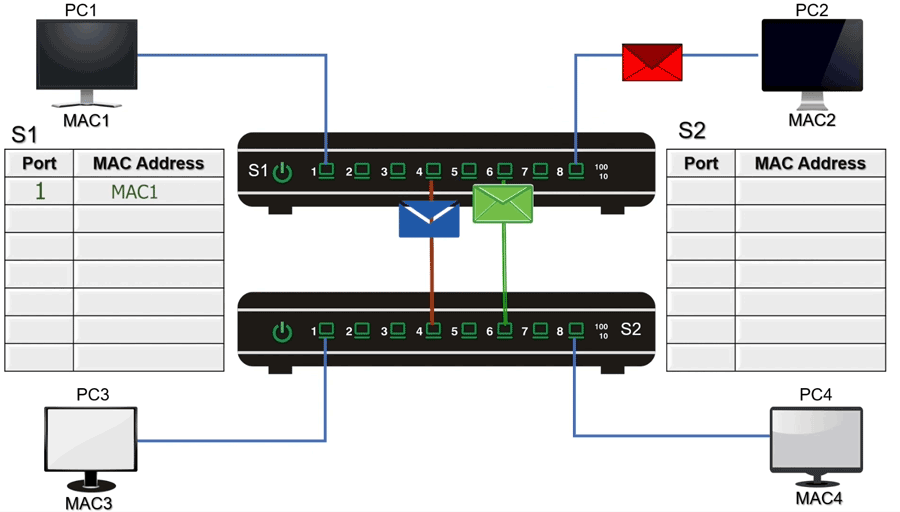
这是因为:
- 交换机需要时间来学习和建立MAC地址转发表。
- 广播风暴的效应是逐步放大、愈演愈烈的。
- 当MAC地址表因环路而频繁抖动更新时,设备性能会急剧下降。
因此,“能正常使用几分钟”完全不能证明网络中没有存在环路。
常见的环路触发场景
场景一:路由器多个LAN口同时接入核心交换机
有些家用或企业级路由器,其多个LAN口在内部是桥接(同属一个广播域)的。如果将其中两个或多个LAN口同时连接到核心交换机的不同端口,就相当于人工制造了一个物理上的二层环路。
场景二:交换机双上联但未启用环路防护
接入层交换机采用双链路上联到两台核心设备以提高可靠性,但如果未开启生成树协议(STP/RSTP/MSTP),或者STP的配置不完整(如端口角色、优先级设置错误),就可能形成逻辑环路。初期可能正常,一段时间后便开始出现异常。
简单的排查方法
可以重点观察以下几点:
- 核心交换机的CPU利用率是否在故障出现时突然飙高。
- 查看MAC地址表,某些MAC地址是否在不同端口间频繁跳动。
- 通过端口计数器或抓包,检查是否出现大量广播帧或未知单播帧。
一个快速的验证方法是:尝试拔掉其中一条你认为可能构成环路的网线,如果网络迅速恢复正常,那么基本可以断定是二层环路问题。
另一个高频原因:IP地址或网关冲突
IP地址冲突的表现并非总是立竿见影,原因在于:
- ARP表有缓存时间,设备不会立即感知到冲突。
- 终端系统的网络栈对冲突的反应有延迟。
- 冲突初期可能只影响少数主机,随着时间推移,影响范围扩大。

当ARP缓存过期刷新、网络流量交互增多时,问题才会全面爆发。
特别常见的一种情况:网关冲突
例如:
- 核心交换机上为VLAN 10配置的SVI接口网关地址是
192.168.1.1。
- 而路由器LAN口配置的IP地址也是
192.168.1.1。
这将导致:
- 网络中的ARP解析混乱,对于网关
192.168.1.1,终端有时学到的是交换机的MAC,有时是路由器的MAC。
- 流量路径不确定,时走交换机三层转发,时走路由器,表现为网络时通时断,最终完全不可用。
如何快速判断?
在任何一台终端上执行查看ARP表的命令(如Windows的 arp -a, Linux的 ip neigh show):
- 查看网关IP地址(如
192.168.1.1)对应的MAC地址。
- 观察该MAC地址是否频繁变化。
- 对比该MAC地址是否与已知的交换机或路由器MAC不一致。
通过这一步,往往能迅速定位到IP或网关冲突的问题。
DHCP配置混乱,也是常见坑点
DHCP相关问题之所以难以定位,是因为其故障表现不一:
- 部分终端能正常获取IP并上网。
- 部分终端获取不到IP地址。
- 部分终端能拿到IP,但网关或DNS错误,导致无法上网。
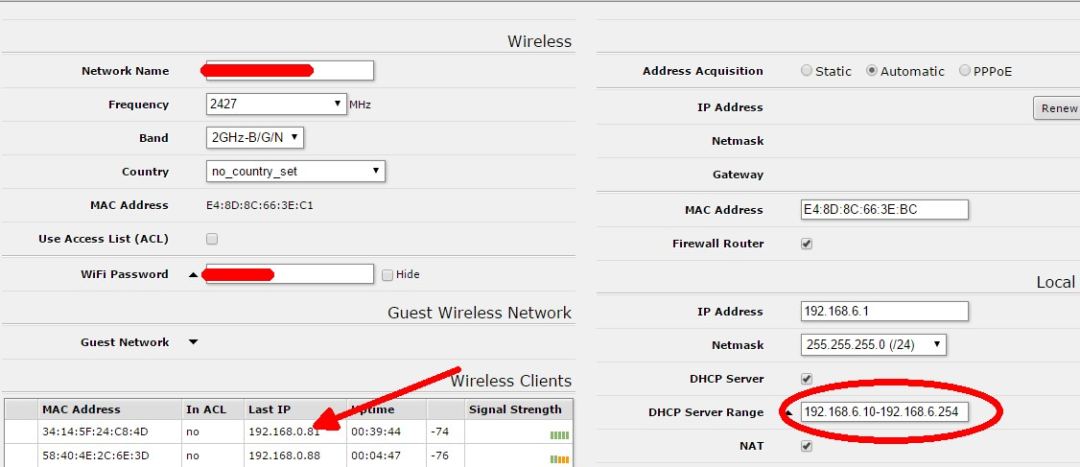
而且,这类问题通常也是过一段时间后,随着更多设备接入或DHCP租期更新,才变得明显。
常见错误场景
场景一:网络中同时存在多个DHCP服务器
- 核心交换机上开启了DHCP服务,为某些VLAN分配地址。
- 路由器默认也开启了DHCP服务器功能。
- 两台设备在同一广播域内同时响应DHCP请求。
终端可能随机从其中一台服务器获取配置,结果拿到:
- 错误的网关地址
- 错误的DNS服务器地址
- 甚至是不属于本网段的IP地址
场景二:DHCP中继(IP Helper)配置错误
在大型分层网络中,接入层VLAN的DHCP请求需要通过中继转发到专门的DHCP服务器。如果中继地址配置错误,或请求被意外转发到了多个服务器,就会造成地址分配混乱。
排查建议
可以重点检查:
- 比较不同终端获取到的IP地址、网关、DNS服务器信息是否一致且符合规划。
- 在核心交换机或通过抓包,分析DHCP Offer和ACK报文究竟来自哪台设备的IP。
- 确认网络中是否存在“意料之外的DHCP服务器”(如违规接人的小路由器)。
ARP异常或广播流量过大
在某些复杂环境中,还可能遇到:
- ARP请求/应答帧异常频繁,充斥网络。
- 某台故障设备(如网卡损坏、程序错误)持续发送广播包。
- 导致交换机CPU忙于处理这些无用流量,性能下降,正常流量受阻。
常见诱因包括:
- 路由器或防火墙的系统软件存在BUG,导致异常发包。
- 虚拟化环境中虚拟交换机的桥接或混杂模式配置不当。
- 某台服务器或终端网卡硬件故障,产生“坏包”。
这类问题往往需要:
- 在核心交换机或可疑网段进行抓包分析,寻找流量源头。
- 采用“隔离法”,逐段或逐台断开设备,观察网络状态是否恢复,来定位故障源。
别忽略路由和策略“延迟生效”的情况
虽然不如前述原因常见,但也值得注意:
- 动态路由协议(如OSPF)完成邻接关系建立后,学习到了错误的路由,覆盖了正确的路径。
- 设备上的默认路由因某种策略被删除或修改。
- 防火墙的会话表或NAT表达到性能上限,新建连接失败。
这些问题通常表现为:
- 网络初期,少量连接可以建立。
- 当用户数量增多、并发会话数增长后,新连接无法建立,网络访问失败。
一个相对系统化的排查流程
如果你在现场遇到此类“先好后坏”的网络故障,可以参考以下顺序进行排查,通常会提升效率:
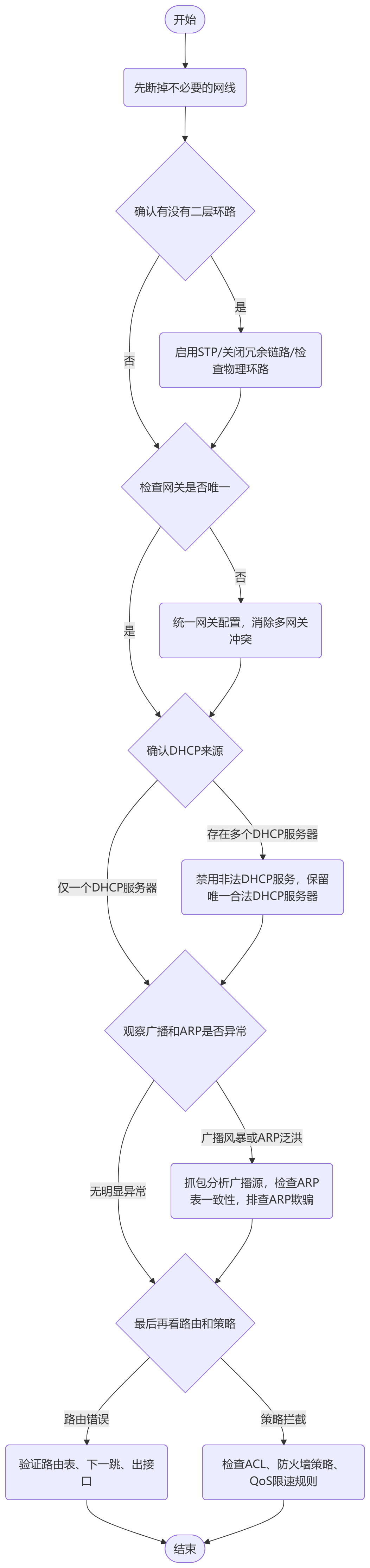
总结下来,问题的核心根源不外乎以下几类:
- 二层边界不清:环路导致广播风暴。
- 网关角色冲突:多个设备宣称自己是网关。
- DHCP或ARP混乱:地址分配或解析不一致。
如果在网络规划与设计阶段就能遵循以下原则,此类问题的发生概率将大大降低:
- 二层尽量简单:避免复杂的二层互联,确需冗余时,必须配置并验证STP。
- 网关职责明确:一个广播域内只有一个活动的网关设备。
- 服务角色单一:避免DHCP等服务在多台设备上重复启用。
希望这篇排查指南,能在你下次遇到类似棘手的网络问题时,提供清晰的思路,助你少走弯路。欢迎在云栈社区交流更多网络技术实践与心得。
 发表于 2026-1-13 04:14:40
|
查看: 256|
回复: 0
发表于 2026-1-13 04:14:40
|
查看: 256|
回复: 0
