痛点:AI 编程助手为何总是“半途而废”?
在使用 AI 编程工具时,开发者经常遭遇这些困境:
- 过早退出:AI 在它认为“足够好”时就停止工作,而非真正完成任务
- 单次提示脆弱:复杂任务无法通过一次提示完成,需要反复人工干预
- 重新提示成本高:每次手动重新引导都在浪费开发者时间
- 上下文断裂:会话重启后,之前的所有进展和上下文全部丢失
这些问题的本质是:LLM 的自我评估机制不可靠——它会在主观认为“完成”时退出,而非达到客观可验证的标准。
解决思路:让 AI 持续工作直到真正完成
Claude Code 社区诞生了一种极简但有效的范式——Ralph Loop(也称 Ralph Wiggum Loop):
while :; do
cat PROMPT.md | claude-code --continue
done
核心思想:同一个提示反复输入,让 AI 在文件系统和 Git 历史中看到自己之前的工作成果。
这不是简单的“输出反馈为输入”,而是通过外部状态(代码、测试结果、提交记录)形成自我参照的迭代循环。其技术实现依赖于 Stop Hook 拦截机制。
Ralph Loop 让大语言模型持续迭代、自动运行直到任务完成,而不在典型“一次性提示 → 结束”循环中退出。这种范式已被集成到主流 AI 编程工具与框架中,被一些开发者称作“AI 持续工作模式”。
甚至 Ralph Loop 结合 Amp Code 被用来构建新编程语言(AFK):
https://x.com/GeoffreyHuntley/status/1944377299425706060
TL;DR / 快速开始
Ralph Loop 让 AI 代理持续迭代直到任务完成。
核心三要素:
- 明确任务 + 完成条件:定义可验证的成功标准
- Stop Hook 阻止提前退出:未达标时强制继续
- max-iterations 安全阀:防止无限循环
最简示例(Claude Code):
# 安装插件
/plugin install ralph-wiggum@claude-plugins-official
# 运行循环
/ralph-loop "为当前项目添加单元测试
Completion criteria: - Tests passing (coverage > 80%) - Output <promise>COMPLETE</promise>" \
--completion-promise "COMPLETE" \
--max-iterations 50
场景适用性:详见「实践建议 - 场景适用性」。
Ralph Loop 概述
什么是 Ralph Loop?
Ralph Loop 是一种自主迭代循环机制。你给出一个任务和完成条件后,代理开始执行该任务;当模型在某次迭代中尝试结束时,一个 Stop Hook 会拦截试图退出的动作,并重新注入原始任务提示,从而创建一个自我参照的反馈循环。在这个循环中,模型可以读取上一次迭代改动过的文件、测试结果和 git 历史,并据此逐步修正自己的输出,直到达到完成条件或达到设定的迭代上限。
简言之:
- 不是简单的一次性运行,而是持续迭代直到完成任务
- 循环使用同一个 prompt,但外部状态(代码、测试输出、文件等)会在每次迭代后改变
- 需要明确的完成条件(如输出特定关键字、测试通过等)和合理的最大迭代次数作为安全控制
Ralph 起源

- Ralph Wiggum 名称来自《辛普森一家》的角色,用于象征“反复迭代、不放弃”的精神,但实际实现是一个简单的循环控制机制,并非模型自身拥有特殊认知。
- 核心机制不是模型自行创造循环,而是 Stop Hook 在模型尝试退出时拦截并重新注入 prompt,从而在同一会话中形成“自我参照反馈”。
- 迭代不是无条件持续,而是依赖于明确可验证的完成信号或最大迭代次数。否则循环可能永不结束。
- 哲学根源:Ralph 循环可以追溯到软件工程中的 “Bash 循环” 思维,其核心逻辑是“不断向智能体提供任务,直到任务完成为止”。这种极致简化体现了将失败视为数据、将持久性置于完美之上的设计哲学。
核心原理
与传统智能体循环的对比
为了深入理解 Ralph Loop 与常规智能体循环的区别,需要先建立对“智能体”的通用语义框架。根据当代人工智能实验室的共识,智能体可定义为:“在循环中运行工具以实现目标的 LLM 系统”。这一共识强调三个关键属性:
- LLM 编排的推理能力:智能体能够根据观察结果进行推理和决策
- 工具集成的迭代能力:智能体可以调用外部工具并基于工具输出调整行为
- 最小化人工监督的自主性:智能体能够在有限指导下自主完成任务
在常规智能体架构中,循环通常发生在单一会话的上下文窗口内,由 LLM 根据当前观察到的结果决定下一步行动。
ReAct(Reason + Act)模式
ReAct 遵循 “观察(Observation)→ 推理(Reasoning)→ 行动(Acting)” 的节奏。优势在于动态适应性:当智能体遇到不可预见的工具输出时,它可以在当前上下文序列中即时修正推理路径。
但这种“内部循环”仍受限于 LLM 的自我评估能力:如果 LLM 在某一步产生幻觉,认为任务已经完成并选择退出,系统就会在未达到真实目标的情况下停止运行。
Plan-and-Execute(计划并执行)模式
Plan-and-Execute 将任务分解为静态子任务序列,由执行器依次完成。它在处理长程任务时更结构化,但对环境变化适应度较低:如果第三步执行失败,计划往往会崩溃,或需要复杂的重计划机制(Re-planning)。
Ralph 循环的“外部化”范式
Ralph 循环打破了对 LLM 自我评估的依赖。它采用 Stop Hook:当智能体试图退出(认为任务完成)时,系统会通过特定退出代码(如退出码 2)截断退出信号。外部控制脚本扫描输出结果,如果未发现预定义的“完成承诺”(Completion Promise),系统将重新加载原始提示词并开启新一轮迭代。
这种模式本质上是强制性的:它不依赖智能体的主观判断,而是依赖外部验证。
对比总结
在开发者语境中,“agent loop” 通常指智能体内部的感知—决策—执行—反馈循环(典型的感知-推理-行动机制)。而 Ralph Loop 更侧重于迭代执行同一任务直至成功,与典型智能体循环在目的与设计上不同:
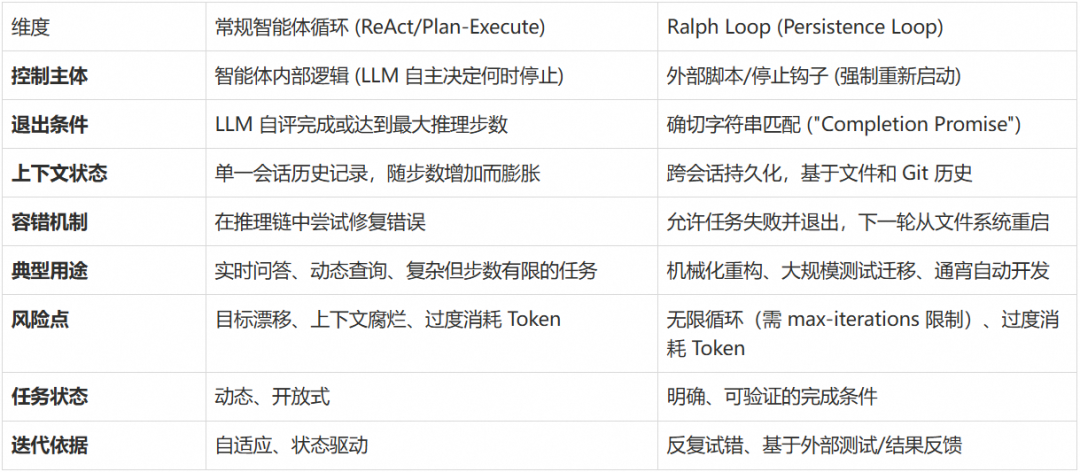
比较结果表明:
- 常规 Agent Loop 更通用:用于决策型 agent,可根据多种状态与输入动态调整下一步操作。ReAct 适合动态适应场景,Plan-and-Execute 适合结构化任务分解。
- Ralph Loop 更像 refine-until-done:重点是让模型在固定任务上不断修正输出,直到满足完成条件;通过外部强制控制避免 LLM 自我评估的局限性。
因此,它与一般意义上的 agent 循环并不矛盾,但定位更专注于可验证任务的持续迭代修正,而非全面的 agent lifecycle 管理。
Stop-hook 拦截机制
Ralph 循环的技术优雅之处在于:它利用现有开发工具链(如 Bash、Git、Linter、Test Runner)构建闭环反馈系统。在常规循环中,工具输出仅作为下一步推理的参考;而在 Ralph 循环中,工具输出成为决定循环是否继续的“客观事实”。
Ralph 循环的工业实现依赖对终端交互的深度拦截。通过 hooks/stop-hook.sh 脚本,开发者可以捕获智能体的退出意图。如果智能体没有输出用户指定的承诺标识(如 <promise>COMPLETE</promise>),停止钩子会阻止正常会话结束。
这种机制强迫 LLM 面对这样一个事实:只要没有达到客观成功标准,它就无法“下班”。外部压力通过重复输入相同的 Prompt 来实现,智能体在每一轮迭代都能看到上一轮留下的改动痕迹和 Git 提交记录。
状态持久化与记忆管理
解决上下文腐烂问题
常规智能体的一个核心痛点是 “上下文腐烂(Context Rot)”:随着对话轮次增加,LLM 对早期指令的注意力和精确度会线性下降。Ralph 循环通过“刷新上下文”绕开这一问题:
- 每一轮循环可视作一个全新的会话,智能体不再从臃肿历史记录中读取状态
- 智能体直接通过文件读取工具扫描当前项目结构与日志文件
- 将“状态管理”从 LLM 的内存(Token 序列)转移到硬盘(文件系统)
由于 Git 历史记录是累积的,智能体可通过 git log 查看自己之前的尝试路径,从而避免重复同样的错误。这种将环境视为“累积记忆”的做法,是 Ralph 循环能支持持续数小时甚至数天开发的核心原因。
核心持久化组件
在典型 Ralph 实现中,智能体会维护这些关键文件:
- progress.txt:追加式日志文件,记录每轮迭代的尝试、踩坑与已确认模式;后续迭代会优先读取以快速同步进度。
- prd.json:结构化任务清单。每完成一个子项,就在 JSON 中标记
passes: true,即使循环中断也能恢复优先级。
- Git 提交记录:每一步成功后提交,不仅便于回滚,更为下一轮迭代提供明确 Diff,便于客观评估现状。
文件结构
scripts/ralph/
├── ralph.sh
├── prompt.md
├── prd.json
└── progress.txt
ralph.sh
#!/bin/bash
set -e
MAX_ITERATIONS=${1:-10}
SCRIPT_DIR="$(cd "$(dirname \
"${BASH_SOURCE[0]}")" && pwd)"
echo "🚀 Starting Ralph"
for i in $(seq 1 $MAX_ITERATIONS); do
echo "═══ Iteration $i ═══"
OUTPUT=$(cat "$SCRIPT_DIR/prompt.md" \
| amp --dangerously-allow-all 2>&1 \
| tee /dev/stderr) || true
if echo "$OUTPUT" | \
grep -q "<promise>COMPLETE</promise>"
then
echo "✅ Done!"
exit 0
fi
sleep 2
done
echo "⚠️ Max iterations reached"
exit 1
prompt.md
每次迭代的说明:
# Ralph Agent Instructions
## Your Task
1. Read `scripts/ralph/prd.json`
2. Read `scripts/ralph/progress.txt`
(check Codebase Patterns first)
3. Check you're on the correct branch
4. Pick highest priority story
where `passes: false`
5. Implement that ONE story
6. Run typecheck and tests
7. Update AGENTS.md files with learnings
8. Commit: `feat: [ID] - [Title]`
9. Update prd.json: `passes: true`
10. Append learnings to progress.txt
## Progress Format
APPEND to progress.txt:
## [Date] - [Story ID]
- What was implemented
- Files changed
- **Learnings:**
- Patterns discovered
- Gotchas encountered
---
## Codebase Patterns
Add reusable patterns to the TOP
of progress.txt:
## Codebase Patterns
- Migrations: Use IF NOT EXISTS
- React: useRef<Timeout | null>(null)
## Stop Condition
If ALL stories pass, reply:
<promise>COMPLETE</promise>
Otherwise end normally.
prd.json(任务状态)
任务清单:
{
"branchName": "ralph/feature",
"userStories": [
{
"id": "US-001",
"title": "Add login form",
"acceptanceCriteria": [
"Email/password fields",
"Validates email format",
"typecheck passes"
],
"priority": 1,
"passes": false,
"notes": ""
}
]
}
progress.txt
任务进度日志:
# Ralph Progress Log
Started: 2024-01-15
## Codebase Patterns
- Migrations: IF NOT EXISTS
- Types: Export from actions.ts
## Key Files
- db/schema.ts
- app/auth/actions.ts
---
## 2024-01-15 - US-001
- What was implemented: Added login form with email/password fields
- Files changed: app/auth/login.tsx, app/auth/actions.ts
- **Learnings:**
- Patterns discovered: Use IF NOT EXISTS for migrations
- Gotchas encountered: Need to handle email validation on both client and server
---
运行 Ralph
./scripts/ralph/ralph.sh 25
运行最多 25 次迭代。Ralph 将:
- 创建功能分支
- 逐个完成任务
- 每个任务完成后提交
- 当所有任务通过时停止
上下文工程的对比分析
常规智能体通常采用总结(Summarization)或截断(Truncation)管理上下文。研究表明,相比复杂总结,简单的“观察掩码”(Observation Masking:保留最新 N 轮,其余用占位符)在效率与可靠性上往往更胜一筹。
但即使最好的掩码策略,也难以处理跨越数十轮、数千行代码改动的任务。Ralph 循环绕开这一难题:它不试图“总结过去”,而是通过提示词引导智能体进行“自我重新加载”。每轮提示始终包含对核心目标的清晰描述,而执行细节留给智能体实时探索环境。这种“即时上下文”加载方式,使 Ralph 能处理规模远超单次窗口容量的工程项目。
框架和工具实现示例
以下是一些主流框架和工具对 Ralph Loop 模式的支持(相关实现通常归类于 人工智能 工具链与 Agent 工程实践):
LangChain / DeepAgents
https://github.com/langchain-ai/deepagents/tree/master/examples/ralph_mode
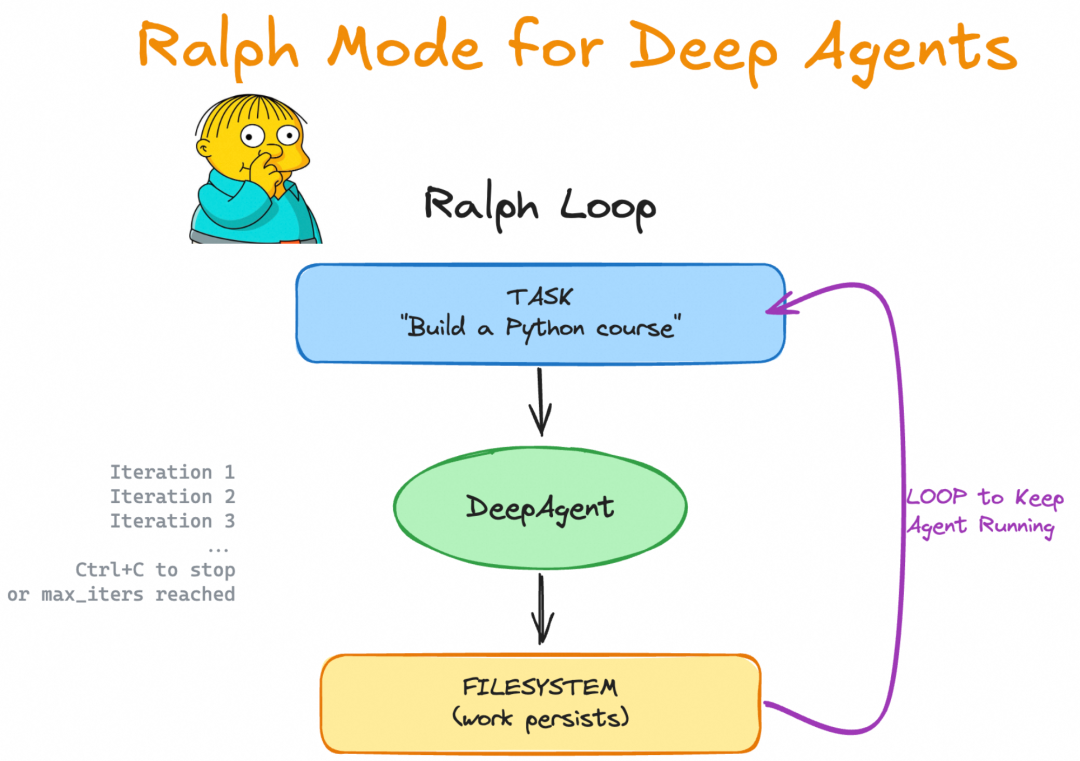
DeepAgents 提供类似模式支持,需要程序化参数传递:
uv run deepagents --ralph "Build a Python programming course" --ralph-iterations 5
这里 --ralph-iterations 指定最大循环次数(详见「实践建议 - 安全机制和资源控制」)。
Kimi-cli
https://moonshotai.github.io/kimi-cli/zh/configuration/config-files.html
loop_control 控制 Agent 执行循环的行为。

AI SDK (JavaScript)
https://github.com/vercel-labs/ralph-loop-agent
社区实现的 ralph-loop-agent 允许更精细的开发控制:
┌──────────────────────────────────────────────────────┐
│ Ralph Loop (outer) │
│ ┌────────────────────────────────────────────────┐ │
│ │ AI SDK Tool Loop (inner) │ │
│ │ LLM ↔ tools ↔ LLM ↔ tools ... until done │ │
│ └────────────────────────────────────────────────┘ │
│ ↓ │
│ verifyCompletion: "Is the TASK actually complete?" │
│ ↓ │
│ No? → Inject feedback → Run another iteration │
│ Yes? → Return final result │
└──────────────────────────────────────────────────────┘
import { RalphLoopAgent, iterationCountIs } from 'ralph-loop-agent';
const migrationAgent = new RalphLoopAgent({
model: 'anthropic/claude-opus-4.5',
instructions: `You are migrating a codebase from Jest to Vitest.
Completion criteria:
- All test files use vitest imports
- vitest.config.ts exists
- All tests pass when running 'pnpm test'`,
tools: { readFile, writeFile, execute },
stopWhen: iterationCountIs(50),
verifyCompletion: async () => {
const checks = await Promise.all([
fileExists('vitest.config.ts'),
!await fileExists('jest.config.js'),
noFilesMatch('**/*.test.ts', /from ['"]@jest/),
fileContains('package.json', '"vitest"'),
]);
return {
complete: checks.every(Boolean),
reason: checks.every(Boolean) ? 'Migration complete' : 'Structural checks failed'
};
},
onIterationStart: ({ iteration }) => console.log(`Starting iteration ${iteration}`),
onIterationEnd: ({ iteration, duration }) => console.log(`Iteration ${iteration} completed in ${duration}ms`),
});
const result = await migrationAgent.loop({
prompt: 'Migrate all Jest tests to Vitest.',
});
console.log(result.text);
console.log(result.iterations);
console.log(result.completionReason);
关键特性:
- 提供模型与任务说明(包含明确完成条件,详见「实践建议 - 明确完成标准」)
- stopWhen 和 verifyCompletion 定制循环退出逻辑
- 事件钩子用于日志和监控
Ralph Loop 最佳实践
如果你正在使用 AI 编程 CLI(如 Claude Code、Copilot CLI、OpenCode、Codex),以下实践指南将帮助你更高效地使用 Ralph Loop。
多数开发者以交互方式使用这些工具:给出任务、观察过程、偏离轨道时介入。这是“人在回路”(Human-in-the-Loop,HITL)模式。
但 Ralph 提供一种新方法:让 AI 编程 CLI 在循环中运行,自主处理任务列表。你定义需要做什么,Ralph 负责如何做——并持续工作直到完成。换句话说,它是长时间运行、自主、无人值守的 AFK(Away From Keyboard,离开键盘)编程。
提示:本节提供操作层面的具体技巧,原则层面的建议请参考「实践建议」部分。
技巧 1:理解 Ralph 是一个循环
AI 编程在过去一年左右经历了几个阶段:
- Vibe 编程:让 AI 写代码而不真正检查。速度快,但代码质量差。
- 规划模式:编码前先规划,提高质量,但仍受限于单个上下文窗口。
- 多阶段计划:将大型功能拆成多个阶段,各自使用不同提示,扩展性更好,但需要持续人工参与。
Ralph 简化了这一切:不是为每个阶段编写新提示,而是在循环中运行相同提示:
#!/bin/bash
# ralph.sh
# Usage: ./ralph.sh <iterations>
set -e
if [ -z "$1" ]; then
echo "Usage: $0 <iterations>"
exit 1
fi
# 每次迭代:运行 Claude Code,传入相同的提示
for ((i=1; i<=$1; i++)); do
result=$(docker sandbox run claude -p \
"@some-plan-file.md @progress.txt \
1. 决定接下来要处理的任务。这应该是你认为优先级最高的,\
不一定是列表中的第一个。\
2. 检查任何反馈循环,如类型检查和测试。\
3. 将你的进度追加到 progress.txt 文件。\
4. 提交该功能的 git commit。\
只处理单个功能。\
如果在实现功能时,你注意到所有工作都已完成,\
输出 <promise>COMPLETE</promise>。\
")
echo "$result"
if [[ "$result" == *"<promise>COMPLETE</promise>"* ]]; then
echo "PRD 完成,退出。"
exit 0
fi
fi
done
每次迭代:
- 查看计划文件,了解需要做什么
- 查看进度文件,了解已完成的工作
- 决定下一步做什么
- 探索代码库
- 实现功能
- 运行反馈循环(类型、Linting、测试)
- 提交代码
关键改进:代理选择任务,而不是你。你定义最终状态,Ralph 去到达它。
技巧 2:从 HITL 开始,然后转向 AFK

运行 Ralph 有两种方式:
- HITL:你观察它做的一切,需要时介入
- AFK:让它无人值守运行(务必限制迭代次数)
关于迭代次数限制,详见「实践建议 - 安全机制和资源控制」。
进展路径很清晰:
- 从 HITL 开始学习与优化提示
- 一旦你信任提示,就转向 AFK
- 返回时审查提交
技巧 3:定义范围
为什么范围很重要
你可以给 Ralph 一个模糊任务,比如“改进这个代码库”,让它跟踪进度。但任务越模糊,风险越大:可能永远循环;也可能走捷径,在你认为完成前就宣布胜利。
真实案例:某次用 Ralph 提高测试覆盖率。仓库有内部命令(标记为内部但仍面向用户),目标是覆盖所有内容。三次迭代后,Ralph 报告“所有面向用户的命令都完成了”,却跳过内部命令,因为它自行判断“它们不是面向用户”,并把它们标记为被覆盖率忽略。
修复方法:明确定义你想覆盖的内容。

推荐格式:结构化 prd.json
定义 Ralph 范围有多种方法(Markdown 列表、GitHub Issues、Linear 任务),但推荐使用结构化的 prd.json:
{
"branchName": "ralph/feature",
"userStories": [
{
"id": "US-001",
"title": "新聊天按钮创建新对话",
"acceptanceCriteria": [
"点击'新聊天'按钮",
"验证创建了新对话",
"检查聊天区域显示欢迎状态"
],
"priority": 1,
"passes": false,
"notes": ""
}
]
}
Ralph 在完成时将 passes 标记为 true。PRD 既是范围定义,也是进度跟踪器——一个活的 TODO 列表。
技巧 4:跟踪 Ralph 的进度
Ralph 通过维护 progress.txt 和 prd.json 解决上下文腐烂问题。在每次迭代中:
- 读取
progress.txt 同步已完成工作与代码库模式
- 读取
prd.json 了解待办任务与优先级
- 追加本次迭代的进度与新模式
- 更新
prd.json 中任务的 passes 状态
最佳实践:
- 在
progress.txt 顶部维护“代码库模式”,便于快速参考
- 每次迭代只处理一个任务,完成后立即更新状态
- 记录踩坑与解决方案,避免重复错误
技巧 5:使用反馈循环
反馈循环是 Ralph 的护栏。没有它们,Ralph 可能会产生“看起来正确但实际上有问题”的代码。
反馈循环类型示意:

在提示中明确要求运行反馈循环:
在每次迭代中:
1. 实现功能
2. 运行类型检查:`tsc --noEmit`
3. 运行测试:`npm test`
4. 运行 Linter:`npm run lint`
5. 只有在所有检查通过后才提交
技巧 6:小步迭代
Ralph 在小的、可验证的步骤中工作得最好。每次迭代应该:
原因:
- 更容易调试:某次迭代失败,你能快速定位问题
- 更好的 Git 历史:每个提交代表一个完整功能
- 更快的反馈:小步意味着更短迭代周期
避免让 Ralph 一次处理多个功能,否则容易:
技巧 7:优先处理高风险任务
不是所有任务都平等。Ralph 应优先处理高风险任务:
- 架构决策和核心抽象
- 模块之间的集成点
- 未知的未知与探索性工作
- 标准功能与实现
- 抛光、清理与快速胜利
将 AFK Ralph 留到基础稳固时:架构验证、高风险集成正常后,再让它在低风险任务上无人值守。
技巧 8:明确定义软件质量
并非所有仓库都是相同的:原型、演示、短期实验、生产代码库,质量标准完全不同。代理不知道它在哪种仓库里,你必须明确告诉它。
质量标准示意:

把标准放在 AGENTS.md、技能中,或直接放进提示里。
同时要记住:代码库模式比指令更有影响力。当指令与现有代码冲突时,现有代码的“证据”往往更强。
具体示例:
// 你的指令:"永远不要使用 any 类型"
// 但现有代码中:
const userData: any = fetchUser();
const config: any = loadConfig();
const response: any = apiCall();
// Ralph 会学习这种模式,继续使用 any
解决方案:
- Ralph 运行前清理代码库:移除低质量模式
- 用反馈循环强制执行标准:Linting、类型检查、测试
- 在
AGENTS.md 中明确质量标准,让期望可见
示例提示:
## 代码质量标准
这是生产代码库。请遵循:
- 使用 TypeScript 严格模式,禁止 any 类型
- 每个函数都需要单元测试
- 遵循现有的文件结构和命名约定
- 提交前必须通过所有 lint 和类型检查
优先级:可维护性 > 性能 > 快速交付
技巧 9:使用 Docker 沙箱
AFK Ralph 需要编辑文件、运行命令、提交代码的权限。你不在键盘前,如何防止它误操作(比如 rm -rf ~)?
Docker 沙箱是最简单的解决方案:
docker sandbox run claude
这会在容器内运行 Claude Code:挂载当前目录,但不会暴露主目录、SSH 密钥或系统文件。Ralph 可以编辑项目文件和提交,但触达面被显著收敛。
权衡:你的全局 AGENTS.md 和用户技能不会被加载。对多数 Ralph 循环来说这通常可接受。
技巧 10:控制成本
Ralph Loop 可能运行数小时,成本控制很重要。
成本估算(以 Claude 3.5 Sonnet 为例):
- 小任务(5-10 迭代):$5-15
- 中等任务(20-30 迭代):$15-50
- 大型任务(30-50 迭代):$50-150
影响因素:
- 代码库大小(上下文窗口)
- 任务复杂度(需要多少迭代)
- 模型选择(GPT-4 vs Claude vs 本地模型)
成本控制策略:
1) 从 HITL 开始:先用人在回路学习与优化提示,再转 AFK
2) 设置严格限制:
# 始终设置最大迭代次数
/ralph-loop "task" --max-iterations 20
3) 选择“可验证、机械化”的任务:重构、测试迁移等
4) 本地模型现实:可用于简单任务预处理或成本敏感备选,但复杂代码任务仍有差距
5) ROI 视角:若几小时完成原本几天工作,即便 $50-150 也可能划算
成本相关示意:

技巧 11:让它成为你自己的
Ralph 只是一个循环,因此可配置性非常高。
交换任务源
示例使用本地 prd.json,但任务可以来自任何地方。

关键洞察不变:代理选择任务,而不是你。你只是改变列表的“位置”。
更改输出
不是直接提交到 main,每次迭代也可以:
- 创建分支并打开 PR
- 向现有 issues 添加评论
- 更新变更日志或发布说明
替代循环类型
Ralph 不必只处理功能积压,也可以做:
- 测试覆盖率循环:指向覆盖率指标,迭代直到达到目标
- 重复代码循环:连接 jscpd 查找克隆并重构
- Linting 循环:把 lint 错误喂给 Ralph,一次修一个
- 熵循环:扫描异味(未使用导出、死代码、不一致模式)并清理
可尝试的提示模板:
# 测试覆盖率循环
@coverage-report.txt
查找覆盖率报告中的未覆盖行。
为最关键未覆盖的代码路径编写测试。
再次运行覆盖率并更新 coverage-report.txt。
目标:至少 80% 覆盖率。
# Linting 循环
运行:npm run lint
一次修复一个 Linting 错误。
再次运行 lint 以验证修复。
重复直到没有错误。
# 熵循环
扫描代码异味:未使用的导出、死代码、不一致的模式。
每次迭代修复一个问题。
在 progress.txt 中记录你更改的内容。
实践建议
提示:本节提供原则层面的指导,具体操作技巧请参考「Ralph Loop 最佳实践」。
明确完成标准
无论是在 Claude Code 还是自己实现的 agent loop 模式中,明确可机器验证的完成条件是 Ralph Loop 成功的关键。
完成条件示例:
- 所有测试通过
- 构建无错误
- Lint 结果清洁
- 明确输出标记(如
<promise>COMPLETE</promise>)
- 测试覆盖率 > 80%
- 所有类型检查通过
避免模糊标准:例如“让它好看一点”会导致循环无法正确退出或产生无意义输出。
示例:
构建一个 Todo REST API
完成标准:
- CRUD 全部可用
- 输入校验完备
- 测试覆盖率 > 80%
完成后输出:<promise>COMPLETE</promise>
安全机制和资源控制
始终设置 --max-iterations 保护你的钱包:
/ralph-loop "Task description" --max-iterations 30 --completion-promise "DONE"
建议迭代次数:
- 小任务:5-10 次
- 中等任务:20-30 次
- 大型任务:30-50 次
成本控制策略:
- 结合成本监控与 token 使用限制策略
- 优先用 HITL 模式学习与优化提示
- 仅在提示稳定后使用 AFK 模式
场景适用性
✅ 适合场景:
- TDD 开发:写测试 → 跑失败 → 改代码 → 重复直到全绿
- Greenfield 项目:定义好需求,过夜执行
- 有自动验证的任务:测试、Lint、类型检查能告诉它对不对
- 代码重构:机械化重构、大规模测试迁移
- 测试迁移:从 Jest 到 Vitest 等框架迁移
❌ 不适合场景:
- 需要主观判断或人类设计抉择
- 没有明确成功标准的任务
- 整体策略规划和长期决策(常规 Agent Loop 更适合)
- 成本敏感场景:ralph-loop 可能运行数小时甚至几十小时
结论
Ralph Loop 是一种以持续迭代修正为中心的 agent 运行范式:通过 Stop Hook 与明确完成条件,让代理不再轻易退出。它与一般意义上的 agent loop 并不冲突,而是在可验证目标条件下的一种强化迭代模式。
理解二者的适用边界,能帮助开发者在构建自动化代理流水线时更合理地选择架构与控制策略;如果你希望在更复杂的工程化落地中做知识沉淀与讨论,也可以到 云栈社区 交流实践经验。
参考资料
 发表于 2026-1-13 19:04:10
|
查看: 508|
回复: 0
发表于 2026-1-13 19:04:10
|
查看: 508|
回复: 0
