昨天晚上,我照例打开 Claude Code 准备写代码。随便聊了几句项目架构,Claude 突然冒出一句:
“Based on our previous discussions, this project uses pnpm and TypeScript strict mode.”
我愣了一下。上次提到 pnpm 是三天前的事了,这中间重启了好几次会话。打开 ~/.claude/projects/ 一看,果然多了个 memory/MEMORY.md 文件。里面记着我之前跟它讨论过的项目配置和编码习惯。
点开更新日志一看,v2.1.59 昨天刚上线了自动记忆功能。我第一时间试了,发现官方方案跟我自己折腾了 3 个月的 DIY 方案,在“提取→存储→加载”的核心流程上几乎一模一样。但仔细分析,两套系统各有各的不可替代性。
今天这篇文章,就为你深入实测官方方案,剖析 DIY 方案的原理与实现,并教你如何将它们结合使用,达到最佳效果。
以前为什么这么痛苦
用过 Claude Code 的开发者都知道,跨会话记忆一直是老大难问题。关掉终端再打开,对 Claude 来说就是一张白纸。
Anthropic 之前给的解决方案是 CLAUDE.md——在项目根目录放一个 Markdown 文件,启动时自动读取。这相当于给 Claude Code 写了一张“说明书”。但问题在于,这玩意儿得你自己手动维护。每次发现 Claude Code 又忘了什么,你就得手动去加一行。用上两周你会发现,CLAUDE.md 越写越长,过时的规则也懒得清理。
我的 CLAUDE.md 一度写到 200 多行,维护成本比写代码还高,这就很离谱了。
v2.1.59 更新了什么
2 月 26 号,Claude Code 发布了 v2.1.59 版本。更新日志里最重要的一条:
“Claude automatically saves useful context to auto-memory. Manage with /memory”
翻译一下:Claude 现在会自动把有用的上下文保存到记忆系统里,用 /memory 命令管理。
核心变化就一句话:以前是“你写 CLAUDE.md,Claude 读”。现在是“Claude 自己写 MEMORY.md,自己读”。
CLAUDE.md 是你给 Claude 的指令,权威性最高。MEMORY.md 是 Claude 自己的笔记本,它觉得什么重要就记什么。两者可以并存,互不冲突。
官方自动记忆怎么工作
记忆存在哪里?
文件存在你的用户目录下,不在项目目录里:
~/.claude/projects/<项目名>/memory/
├── MEMORY.md # 主记忆文件(自动加载前200行)
├── debugging.md # 调试相关的记忆
├── api-conventions.md # API约定
└── ... # 其他主题文件
<项目名> 是从 git 仓库根目录推算的。同一个仓库下的所有子目录,共享同一份记忆。
什么时候触发记录?
不需要你做任何事情,完全自动。Claude 自己判断什么时候该记——具体的触发机制是黑盒,官方没有公开阈值。
但从实际使用来看,Claude 记忆非常保守。有用户反馈用了几周,MEMORY.md 也才 12 行。短对话(比如“帮我改个拼写错误”)几乎不产生记忆。深度对话(比如讨论架构设计、反复纠正同一个习惯)才会触发记录。
怎么加载记忆?
下次开新会话时,Claude Code 自动读取 MEMORY.md 的前 200 行。超过 200 行的内容不会自动加载,Claude 会收到一个警告。主题文件(比如 debugging.md)不会在启动时加载,Claude 觉得需要的时候,会自己去读取对应的文件。
怎么管理?
输入 /memory,可以查看和编辑 MEMORY.md,也能开关自动记忆功能。在输入框里输入 # 加一条指令(比如 # 永远用TypeScript严格模式),能快速保存到 CLAUDE.md 里。
注意:# 快捷键写入的是 CLAUDE.md(你的指令文件),不是 MEMORY.md(Claude 的笔记)。一个是“你说的”,一个是“它记的”,别搞混。
如果不想用自动记忆,在 .claude/settings.json 里加 "autoMemoryEnabled": false 就行。
官方功能虽好,但根据我的测试,直接对 Claude 说“帮我记录到说明文件”可能比等待自动触发更直接有效。
社区反应:有惊喜也有坑
这个功能上线不到 24 小时,GitHub 上已经有不少讨论了。
惊喜的部分:确实解决了跨会话记忆的痛点。不用再手动维护 CLAUDE.md 了,Claude 自己学、自己记。对于长期在固定项目上开发的用户,体验提升很明显。
翻车的部分:
- Token 消耗增加:GitHub Issue #29178 报告了这个问题。有用户在 Max x5 套餐下,18 分钟的轻度对话就消耗了 8% 的配额。原因是自动记忆会把内容注入到每条消息的系统提示词里,叠加 Skill 元数据,Token 开销不小。
- 记忆是“影子状态”:Issue #23544 指出了另一个问题。记忆文件存在
~/.claude/projects/ 下,不在你的项目目录里。不能被 git 追踪,不能在 PR 里 review,不能跨设备同步。
- 重复加载 Bug:Issue #24044 发现
MEMORY.md 被加载了两次。自动记忆加载器和 CLAUDE.md 加载器各加载了一遍,Token 消耗直接翻倍。
官方只解决了一半问题
说到这里,得说句实话。官方自动记忆在知识发现上是碾压级别的——Claude 用 AI 语义理解来判断什么值得记,这个能力任何规则匹配都拍马赶不上。
但知识管理呢?记下来之后怎么办?过时了怎么清理?Token 怎么精确控制?怎么跨设备同步?怎么团队共享?这些问题,官方一个都没解决。
这就是我 3 个月前开始搭建三层记忆系统的初衷——不是为了替代官方方案,而是补上“管理”这半截。
老金的方案:三层自动记忆架构
折腾了 3 个月,我设计出一套三层记忆系统。每一层解决不同的问题,组合起来就能让 Claude Code 真正“懂你”。
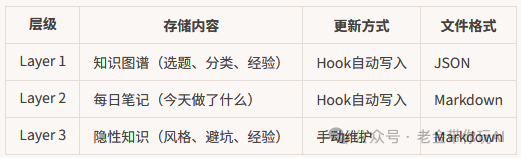
核心思路:Layer 1 和 Layer 2 是自动的——通过 Hooks(钩子脚本)在你工作时自动提取和保存知识。Layer 3 是手动的——存放那些 AI 提取不了的隐性经验。三层加起来每个主题大概占 1500 token,对 200K 的上下文窗口来说不到 1%,几乎可以忽略。
Layer 1:用 Hook 自动积累知识图谱
这是整套系统最核心的部分。
Hooks 是什么? Hooks 是 Claude Code 2.1 引入的功能——在特定时机自动执行脚本。比如会话开始时、工具调用后、上下文压缩前,都可以挂一段代码自动运行。不需要你手动触发,完全在后台静默执行。
我用了三个关键 Hook 来实现自动记忆:
第一个:SessionStart Hook
每次打开 Claude Code,这个 Hook 自动运行,把之前积累的知识注入到当前会话。核心逻辑很简单:
def load_layer1_knowledge_graph():
topics_dir = MEMORY_DIR / "areas" / "topics"
for topic_folder in topics_dir.iterdir():
items_file = topic_folder / "items.json"
items = json.load(open(items_file))
# 只加载每个主题最近10条active记录,按时间排序
active_items = [i for i in items
if i.get("status") == "active"]
active_items.sort(key=lambda x: x.get("timestamp", ""))
recent = active_items[-10:]
它干的事就一件:读取 items.json 里的知识条目,按时间排序后取每个主题最近 10 条状态为 active 的记录,注入到会话上下文。多了浪费 token,少了不够用,10 条是我试出来的平衡点。
第二个:PostToolUse Hook
这个 Hook 在 Claude Code 每次使用工具后自动触发,分析对话内容,提取有价值的信息保存下来。比如写完一篇公众号文章后,它会自动提取一条记录:
{
"id": "fact-20260227150448",
"fact": "Claude Code文章,使用利益前置型公式",
"category": "核心",
"timing": "常青",
"formula": "利益前置型",
"timestamp": "2026-02-27",
"status": "active"
}
这条记录自动保存到 items.json。下次开新会话时,SessionStart Hook 自动加载它。整个过程完全自动,你不需要做任何事情。
第三个:PreCompact Hook
这个 Hook 在 Claude Code 压缩上下文窗口之前自动触发。为什么需要它?Claude Code 的上下文窗口大概 200K token,用着用着就快满了,系统会自动压缩——也就是丢掉一部分对话内容。如果不做任何处理,压缩时可能把你当前正在做的事情、修改的文件列表这些关键信息给压没了。
PreCompact Hook 干的就是:在压缩发生之前,把当前会话状态(正在做什么任务、改了哪些文件、临时笔记)保存到磁盘。这样即使上下文被压缩了,下次 SessionStart Hook 还是能把这些状态找回来。
知识图谱的目录结构
.claude/memory/areas/topics/
├── ai-tools/
│ └── items.json # 35条记录
├── writing/
│ └── items.json # 12条记录
└── debugging/
└── items.json # 8条记录
我用了 3 个月,自动积累了 55 条知识记录。每条记录都有 status 字段,active 表示还有用,superseded 表示已被新知识替代。这样知识库会自动迭代,不会越积越臃肿。
Layer 2:每日笔记自动记录
Layer 2 比 Layer 1 更简单。每天自动生成一个 Markdown 笔记文件,记录今天做了什么。
每次写完文章或完成一个任务,Hook 会自动追加一条记录:
# 2026-02-27
## 15:04 - 写作
主题:Claude Code
公式:利益前置型
分类:核心
时效:常青
SessionStart Hook 会自动加载最近 3 天的笔记。这样 Claude Code 下次启动时就知道:昨天你写了一篇关于 DeepSeek 的文章,用的是利益前置型公式。对于连续工作特别有用。比如上午写了一半的文章,下午接着写,Claude Code 知道上午的进度,不用从头解释。
Layer 3:手动维护隐性知识
这一层最简单,就是一个 MEMORY.md 文件。里面放那些 AI 自动提取不了的东西。
- 风格偏好:“标题最优 22-28 字”、“禁止用 FOMO 词”、“品牌词首次出现要加粗”。
- 避坑经验:“Windows 路径分隔符要用正斜杠”、“代码块前后必须有空行”。
- 对标参考:“技术深度好的号可以借鉴架构,但保持差异化”。
这些东西没法自动生成,需要你根据经验手动写进去。但一旦写好,每次会话启动都会自动加载。我的 MEMORY.md 只有 20 多行,大概 200 token。精炼但管用。
官方+DIY:7维度对比
现在你对两套方案都有了解了,我们做个全面对比。
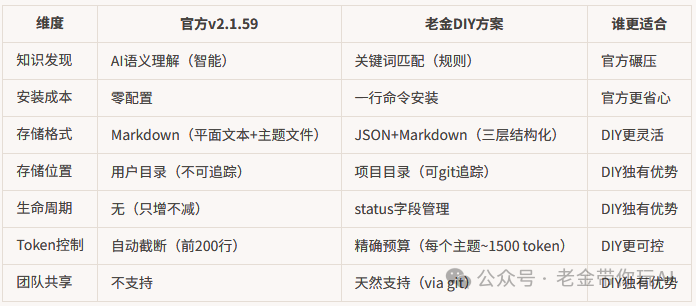
核心架构一模一样——都是“提取→存储→加载”。但实现路径完全不同,各有各的不可替代性。我挑几个关键差异展开说。
知识发现:官方碾压,没悬念
官方的提取能力是 AI 语义理解——Claude 自己读对话、自己判断什么值得记、自己归纳总结。DIY 方案的提取则是关键词匹配,比如 if "claude" in text.lower() 这种级别。这个差距不是一个量级的。
但“发现知识”只是记忆系统的前半段。后半段——“管理知识”,才是 DIY 方案的主场。
知识生命周期:有管理 vs 只进不出
DIY 方案的 items.json 每条记录都有一个 status 字段。当一条知识过时了,把 status 改成 superseded,SessionStart Hook 就不再加载它。知识库会自动新陈代谢,永远保持精简。
官方的 MEMORY.md 没有这个机制。Claude 往里写,越写越长,超过 200 行就自动截断不加载。等于说你最早存的记忆可能是最重要的,但 200 行以后的新记忆反而被忽略了。
Git 追踪:能 vs 不能
DIY 方案的记忆文件全部存在项目目录 .claude/memory/ 下。可以 git 追踪,可以在 PR 里 review,可以跨设备同步。团队协作的时候,知识库是共享的。
官方的 MEMORY.md 存在 ~/.claude/projects/ 下,属于用户个人目录。不能 git 追踪,不能跨设备同步。换台电脑开发,记忆就没了。
Token 精确控制:1500 vs 不可控
DIY 方案每个主题加载最近 10 条 active 记录。单主题场景下大概 1500 token,占 200K 上下文窗口不到 1%。多主题会按比例增加,但通过环境变量 MEMORY_MAX_ITEMS 可以精确控制。
官方的方案加载 MEMORY.md 前 200 行,具体多少 token 完全取决于你的 MEMORY.md 写了什么。再加上 Skill 元数据注入,前文提到的 Issue #29178 反馈的 Token 消耗暴增就是这个原因。
一行命令装好
我已经把这套三层记忆系统做成了开源工具,一行命令就能装好。
GitHub 地址:https://github.com/KimYx0207/claude-memory-3layer
# macOS / Linux
curl -fsSL https://raw.githubusercontent.com/KimYx0207/claude-memory-3layer/main/install.sh | bash
# Windows PowerShell
irm https://raw.githubusercontent.com/KimYx0207/claude-memory-3layer/main/install.ps1 | iex
一行命令搞定:自动创建目录结构、复制 Hook 脚本、注册 settings.json、生成 MEMORY.md 模板。零依赖,纯 Python 标准库,装完就能用。装好后还附送两个命令:/memory-review(定期回顾记忆,提炼规则)和 /memory-status(查看记忆系统状态)。
安装后的目录结构
你的项目/
└── .claude/
├── hooks/
│ ├── memory_loader.py # SessionStart:加载三层记忆
│ ├── memory_extractor.py # PostToolUse:提取知识
│ ├── session_state.py # 会话状态管理
│ └── pre_compact.py # PreCompact:压缩前保存
├── memory/
│ ├── MEMORY.md # Layer 3:隐性知识
│ ├── memory/ # Layer 2:每日笔记
│ └── areas/topics/ # Layer 1:知识图谱
└── settings.json # Hook注册配置
两套系统怎么一起用
前面说了“两套结合才是最优解”,但具体怎么结合?
核心原理:它们住在不同的地方,互不干扰
官方的 MEMORY.md 存在你的用户目录 ~/.claude/projects/ 下,由 Claude Code 内置加载器自动读取。DIY 方案的 items.json 存在项目目录 .claude/memory/ 下,由 SessionStart Hook 自动读取。两套系统各走各的路,完全不冲突。
你可以把它想象成一个人有两本笔记本。官方那本是“随手记”——Claude 觉得什么重要就往里写,你不用管。DIY 这本是“整理簿”——结构化存储,能过期、能追踪、能团队共享。
实际运行流程
你打开Claude Code
↓
① 内置加载器自动读取 MEMORY.md(官方记忆)
② SessionStart Hook自动读取 items.json(DIY记忆)
↓
两份记忆同时注入上下文,Claude都能看到
↓
你开始干活
↓
③ Claude自动往 MEMORY.md 写新发现(官方机制)
④ PostToolUse Hook自动往 items.json 写结构化记录(DIY机制)
↓
下次开新会话,①②再来一遍
整个过程零配置,装好就自动运行。你不需要做任何“联合”的操作——它们天然就是联合的。
各管各的,谁也替不了谁
举个例子。我跟 Claude 讨论了半天架构设计,Claude 可能会在 MEMORY.md 里记一条:“这个项目偏好函数式编程风格”。这种语义级别的洞察,DIY 方案的关键词匹配提取不了。
但当我写完一篇公众号文章后,PostToolUse Hook 会自动提取一条结构化记录:标题、分类、公式、时效性,存到 items.json 里。这种结构化的知识管理,官方的 MEMORY.md 做不到。
所以不是“选哪个”的问题。官方负责发现你自己都没意识到的偏好,DIY 负责把工作成果结构化存档。一个管“悟”,一个管“记”,缺一不可。
真实效果:3个月数据
装上这套系统之前,我每次开新会话至少要花 5 分钟重新介绍项目。“我的项目是公众号写作助手”、“文章保存在 articles/drafts 目录”、“用老金风格写”。每次都是这一套,烦得很。
- 第一周:没什么感觉。知识图谱还没积累起来,
items.json 里只有几条记录。体验跟以前差不多。
- 第二周:开始有变化了。知识条目超过 20 条后,Claude Code 开始“懂”一些东西了。比如我说“写公众号”,它已经知道要用什么风格、文章保存在哪里。
- 第三周之后:真的回不去了。现在我开新会话,直接说“帮我分析最近的标题数据”。Claude Code 知道数据在哪、用什么格式、输出到哪个目录。完全不需要解释。
具体数据
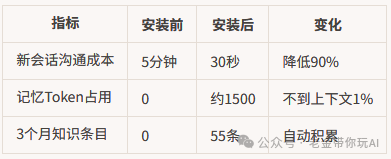
/memory-status(查看记忆系统状态)执行效果参考:

/memory-review(定期回顾记忆,提炼规则)效果参考:
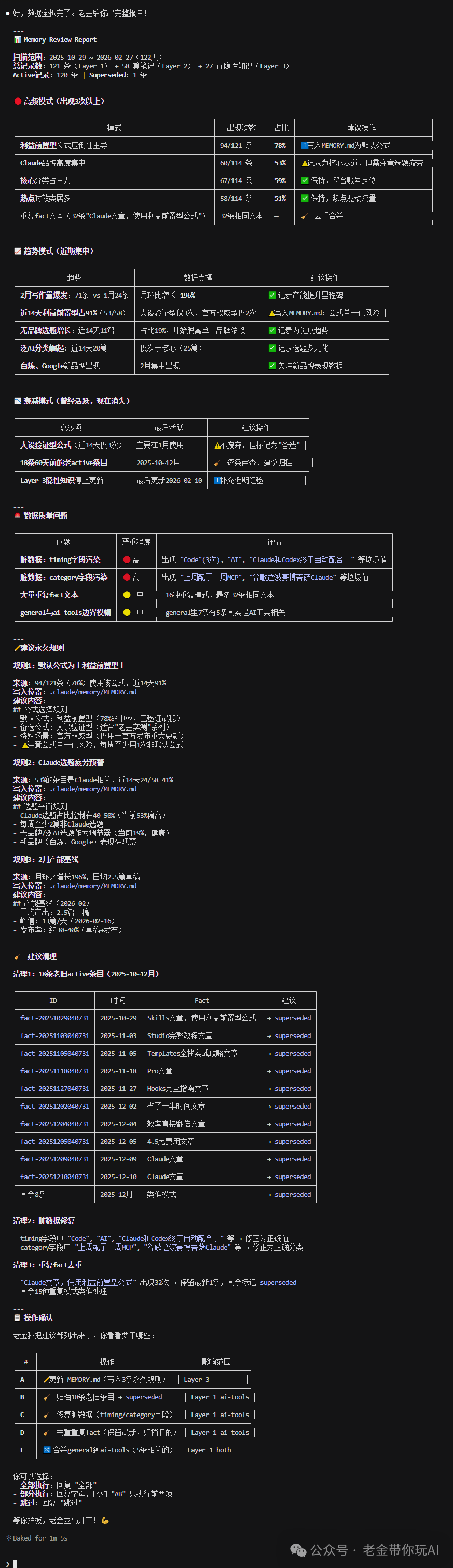
避坑指南
- 先小范围试用官方自动记忆:这个功能刚上线,还不够稳定。建议先在一两个项目上开启,观察几天的 Token 消耗变化。如果发现消耗异常增加,先关掉等后续版本修复。
- 定期审核记忆内容:不管是官方的
MEMORY.md 还是 DIY 方案的 items.json,都需要定期扫一遍。Claude 记的不一定全对,也不一定都是你需要的。建议每周花 5 分钟看一遍,删掉过时的或不准确的记录。
- 不要放弃 CLAUDE.md:别因为有了自动记忆就不维护
CLAUDE.md 了。CLAUDE.md 是你的“规矩”,权威性最高。MEMORY.md 只是 Claude 的“参考笔记”。核心规则一定要写在 CLAUDE.md 里,这是底线。
- 给 DIY 系统足够的学习时间:不要装上就期待立马有效果。至少用 2-3 周,让知识图谱积累到 20 条以上,效果才明显。
- 保持工作流程的一致性:如果你的项目结构和工作习惯经常变,记忆系统会比较混乱。尽量保持固定的目录结构和命名规范。
总结
Claude Code v2.1.59 的自动记忆,本质上就是让 Claude 自己维护一份跨会话的“学习笔记”。方向是对的,跨会话记忆确实是 Claude Code 最大的痛点,官方终于动手解决了。
但“发现知识”只是记忆系统的一半。另一半——知识过期管理、Git 追踪、团队共享、Token 精确控制——官方还没覆盖到。我 3 个月前搭的三层记忆系统,刚好补上了这些缺口。
最终答案不是二选一,而是两套结合。
官方Auto Memory(AI智能发现知识)
↓ 自动记录到 MEMORY.md
你的日常使用(零配置,不用管)
↓
三层记忆系统(结构化管理知识)
↓ 一行命令安装
items.json(可过期、可追踪、可共享)
官方负责“发现”,DIY 负责“管理”。一个都不能少。对于想要深入探索AI应用与开发技巧的开发者,不妨多逛逛像云栈社区这样的技术论坛,那里常有前沿的实战分享和开源项目讨论。
开源地址:https://github.com/KimYx0207/claude-memory-3layer
参考资料
 发表于 2026-3-1 10:00:21
|
查看: 218|
回复: 0
发表于 2026-3-1 10:00:21
|
查看: 218|
回复: 0
