在实证资产定价领域,“哪些因子最重要?”是一个看似基础却始终未被真正解决的问题。传统线性模型习惯通过回归系数大小或 t 统计量来判断因子的经济意义,但这隐含了因子线性可加且彼此独立的强假设。
随着机器学习方法在资产定价中的广泛应用,这一前提正被系统性地打破。非线性模型允许高维交互与复杂结构,显著提升了预测能力,但也带来了新的挑战:当模型本身不再具有可解释的“系数”时,我们还能否严肃地讨论“因子重要性”?
本文的立场并非证明“机器学习比线性模型更好”,而是探讨一个更基础的问题:在非线性、高维、强交互的环境下,是否还能有意义地识别哪些因子在解释收益?这种重要性又在多大程度上依赖方法、样本与频率?
研究立场的转变:从“显著性”到“贡献度”
首先需要明确一个立场转变:在机器学习框架下,因子已不再是回归中的“解释变量”,而是模型预测机制的一部分。因此,传统“显著性检验”不再适用,取而代之的应是因子对模型预测能力的贡献度。
具体而言,可以将每个因子视为一个“信息来源”,并提出问题:如果在模型中移除这个因子,预测误差会增加多少? 这一定义天然地将问题从统计推断转向了模型层面的性能分解。这一思路通过引入博弈论中的 Shapley value 得到形式化表达。在此框架下,每个因子被视为合作博弈中的一名“玩家”,其重要性定义为:在考虑所有可能因子组合的情况下,该因子对模型预测能力的平均边际贡献。关键在于,这种贡献是条件性的,它天然地考虑了因子之间的交互关系。
数据与模型设定:在最苛刻环境下讨论重要性
为避免“因子挑选偏误”,在数据层面采取了一个极具挑战性的设定:直接使用 global-q.org 中整理的 188 个已发表异常作为特征集合。这些异常横跨动量、价值、盈利能力、投资、摩擦与无形资产等多个类别,构成一个高度冗余、强相关的因子空间。
在模型层面,采用人工神经网络(ANN)来解释这些异常构成的多空组合收益,并刻意不对输出层施加线性约束。这意味着,模型可以自由学习非线性映射与复杂交互,而不会被迫回到线性资产定价框架。如果在如此复杂的环境下,“因子重要性”仍然存在可解释结构,那么这一概念才具有真正的说服力。
SHAP与SAGE:两种“因子重要性”的定义方式
在具体实现上,研究采用了两类基于 Shapley value 的可解释机器学习工具:SHAP 与 SAGE。二者看似相近,但其解释立场存在本质差异。
SHAP 是一种典型的局部解释方法。它在每一个观测点上,分解模型预测值,计算各因子对该期预测的贡献,然后通过对这些贡献绝对值的时间平均,得到全样本层面的重要性排序。换言之,SHAP 更像是在回答:在历史上,每一次预测中,哪些因子经常被模型“用到”?
SAGE 则采取了完全不同的视角。它直接从模型损失函数出发,衡量在全样本范围内,某个因子被加入模型后,能够在多大程度上降低预测误差。因此,SAGE 更关注的是:这个因子对模型整体性能是否“不可或缺”?
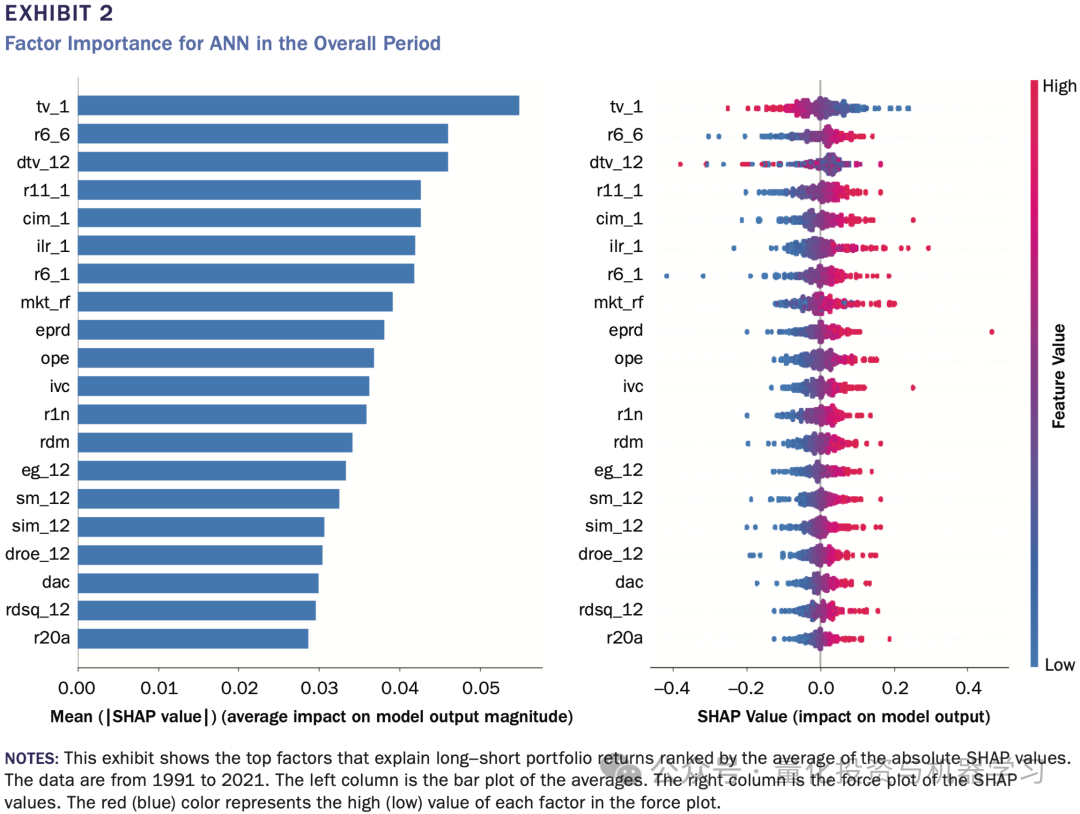
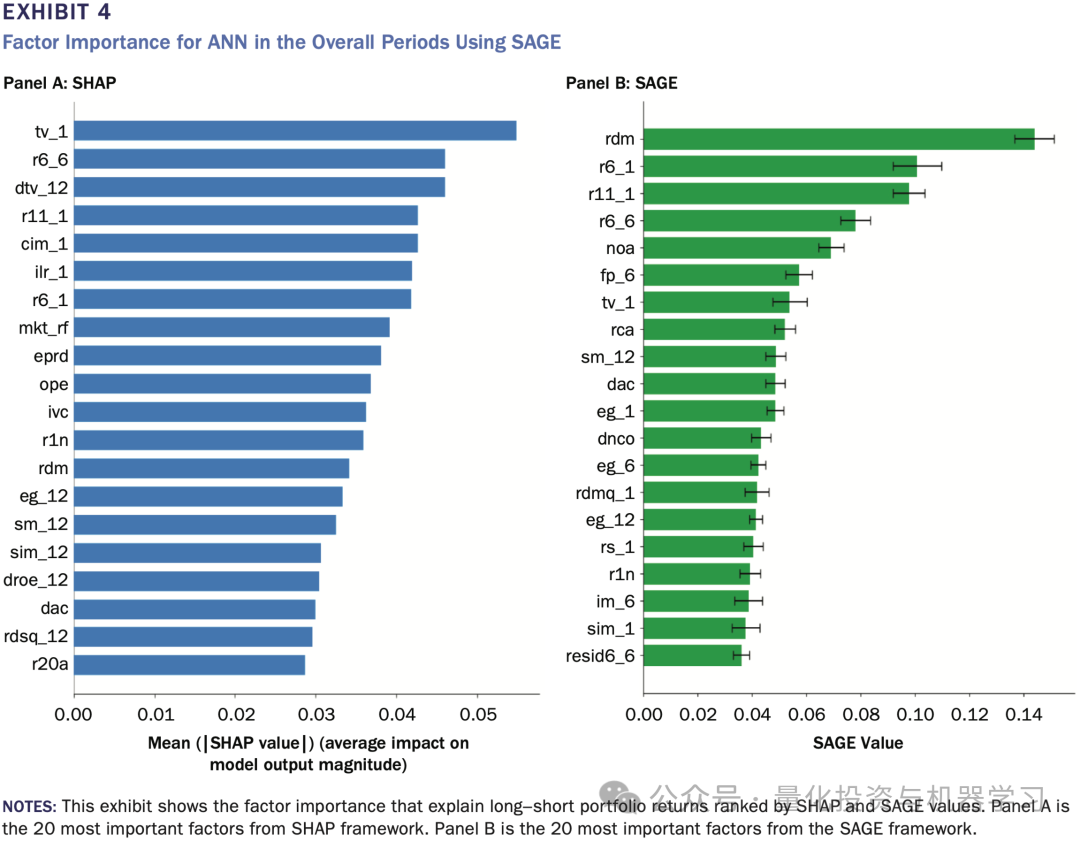
上图给出了两种方法下的因子重要性排序对比。尽管 SHAP 与 SAGE 同源于 Shapley value,但由于一个强调“频繁参与解释”,另一个强调“整体性能贡献”,其结论并不一致。这种不一致本身就是一个核心发现。
发现一:重要性高度依赖解释方法
全文最直接、也最具冲击力的发现是:SHAP 与 SAGE 给出的因子重要性排序,并不一致。
在整体样本期内,两种方法都显示动量类因子在解释收益中占据重要位置,但具体排名与入选因子却存在显著差异。某些在 SHAP 中排名靠前的因子,在 SAGE 中几乎消失;反之亦然。
这并不是数值误差,而是方法立场的必然结果。SHAP 更偏向“频繁参与解释”的因子,而 SAGE 更偏向“对整体模型性能至关重要”的因子。一个因子可以在很多时期都有小贡献,却未必是模型不可或缺的;反之亦然。这一结果直接否定了一个在实务中非常常见但危险的直觉:“既然模型告诉我这个因子最重要,那我就该重点押它。”
发现二:重要性不是常数,而是状态变量
如果方法依赖已经足够令人警惕,那么时间与频率维度的结果则进一步加深了这一结论。
将样本划分为三个子时期,发现同一个因子类别在不同阶段的重要性显著不同。例如,动量因子在 1990s 与 2000s 的解释力极强,但在 2010 年后明显减弱;与此同时,摩擦与盈利能力相关因子在后期的重要性上升。
当进一步将分析从月频扩展到日频时,因子重要性排序变得更加分散、也更加不稳定。日频数据噪声更大,不同 ANN 结构下,仅有极少数因子能够在所有模型中保持“重要”。这一结果背后的含义非常直接:“因子重要性”不是一种结构常数,而是一个强烈依赖环境的状态变量。
与经典因子模型的对照:解释 ≠ 定价
将同样的方法应用于 Fama–French 五因子模型与 Hou et al. 的 q 因子模型,试图回答一个更贴近传统资产定价的问题:在机器学习解释框架下,这些“经典因子”到底有多重要?
结果显示,在 FF 模型中,动量因子(UMD)依然是最重要的解释变量,而投资因子的重要性最低;在 q 模型中,盈利能力相关因子占据主导。但需要非常谨慎地指出,这里的“重要性”并不等同于“定价正确性”。一个因子可以在解释其他异常收益中非常重要,却未必意味着它在资产定价意义下是“必要因子”。这实际上把整篇论文的立场推向了一个非常清晰的位置:可解释机器学习告诉你的,是模型如何使用信息,而不是市场为何给出回报。 当你问“哪个因子最重要”时,你可能已经问错了问题。
实务启示
在实务中,这篇论文至少给出三条极其重要的启示:
- 第一,不要把机器学习给出的因子重要性,当成新的 alpha 排序工具。 重要性是模型内生的、方法依赖的,无法直接转化为稳定的超额收益来源。
- 第二,因子重要性更适合作为“模型诊断工具”,而非“投资信号”。 它可以帮助你理解模型在不同阶段依赖了哪些信息,从而识别潜在的过拟合、结构漂移或市场状态变化。
- 第三,在高维因子世界里,“都会重要,各有重要法”。 不同因子在不同频率、不同阶段、不同模型中扮演的角色并不相同,试图寻找一个“永久核心因子集合”,本身就是对现实市场复杂性的低估。
总结:从“找因子”到“理解模型”
这篇文章的最大价值,并不在于它给出了某个新的因子结论,而在于它完成了一次研究范式的纠偏。它提醒我们,在机器学习已经深度介入资产定价的今天,“因子重要性”不再是一个可以脱离模型、脱离方法独立存在的概念。
如果说传统因子研究关心的是“这个因子有没有用”,那么这篇论文关心的是:“模型为什么会用它,以及在什么条件下用它。”
在机器学习框架下,因子筛选不应被理解为对“最重要因子”的排序,而应被视为一个逐步排除不稳健信息的过程。具体而言,研究应首先在不做任何线性预筛的前提下,将所有候选因子全量纳入模型,并确认模型本身在样本外具有稳定的预测能力。在此基础上,因子的重要性应通过多种可解释方法(如SHAP和SAGE)加以刻画,而非依赖单一指标;只有在不同解释定义下均表现出非边缘贡献的因子,才具备进一步讨论的意义。随后,还需检验因子重要性在不同时间区间与相邻数据频率下的稳定性,以排除仅在特定样本或噪声环境中“偶然重要”的信号。最终,机器学习意义下的因子筛选,并不是为了识别一个固定的“核心因子集合”,而是为了保留那些在方法、时间与频率维度上均展现出稳定贡献的因子,从而避免将模型内生的、情境依赖的重要性误读为可持续的投资信号。
本文由云栈社区基于前沿学术论文进行深度研读与整理,旨在为量化研究与数据科学从业者提供专业洞察。
 发表于 2026-1-15 06:07:58
|
查看: 226|
回复: 0
发表于 2026-1-15 06:07:58
|
查看: 226|
回复: 0
