
我们每天都在关注层出不穷的顶会论文和明星模型,但那些纸面上精妙的数学公式,在实际的大规模训练中,表现总是无懈可击吗?
最近几周,我在深入研究 DeepSeek mHC 的过程中,意外得出了一个有些令人啼笑皆非的结论。论文最核心的算法改进之一,是将残差连接矩阵 $H^{res}$ 施加了流形约束(manifold constraint),即使用 Sinkhorn-Knopp 算法将其投影到双随机矩阵,目的是为了保证前向与反向传播的稳定性。
这就引出了一个很自然的问题:这个“m”(流形约束)真的非用不可吗?
我们的实验发现,直接将其替换为最简单的单位矩阵(identity)效果反而更好,也就是令 $H^{res} = I$。
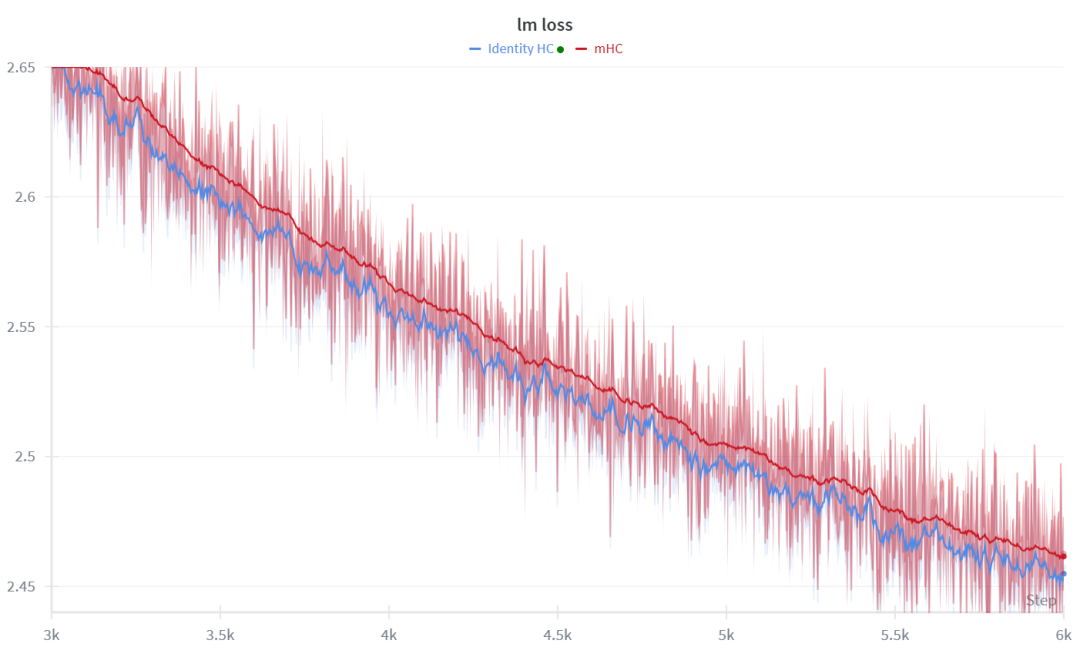
图1: 在 Qwen 1.7B 模型上进行 150B Tokens 从头预训练,局部训练曲线的对比。
目前的实验结论排序是:Identity HC > mHC > mHC lite > mHC orthogonal (例如 Cayley 正交化)。这些实验在 Qwen3 1.7B 和 8B 的 Dense 模型上完成,训练了 150B tokens,尽可能排除了框架实现 bug 的影响。
单位矩阵(对角线为1,其余为0)其实也满足行和与列和均为1,谱范数为1,是最简单的一种“流形约束”。直观上,单位矩阵 $H^{res} = I$ 意味着每条残差流都保持自己的信息,不与其他流进行交换。
而在实际的原版 mHC 训练中,我们观察到模型自己学习出的 $H^{res}$ 大致呈现以下模式:
- 单层 $H^{res}_l$ ($H_l$): 接近单位阵(对角线元素 ~0.96,非对角线 ~0.01)。
- 累积乘积 $Π H^{res}_l$: 坍缩为全 0.25 的均匀混合矩阵。

图2: mHC 模型累积 $H^{res}$ 乘积矩阵的可视化,可见其快速坍缩为均匀矩阵。
也就是说,Sinkhorn-Knopp (SK) 算法学到的单层 $H^{res}$ 可能更接近单位阵,但多层连乘后,受数学性质影响,最终会退化为一个所有元素都相等的矩阵。其背后的数学原理是:当双随机矩阵满足一致正性条件时,其 Dobrushin 遍历系数 $γ < 1$,多层连乘后所有行向量会以指数速率趋于一致,最终收敛到均匀矩阵。
我们直接将 $H^{res}$ 设为恒等矩阵 $I$,相当于把模型学到的单层行为(接近置换)固定下来,同时避免了双随机矩阵连乘必然导致的 rank-1 坍缩问题。
那么,$H^{res}$ 退化为置换矩阵(恒等矩阵是特殊的置换矩阵)究竟是利是弊?实际上,在 mHC 中,不同层学到的 $H^{res}$ 可能是不同的近似置换矩阵(例如第1层是流 [1,2,3,4] -> [2,1,4,3],第5层是另一套映射)。这些不同的置换连乘,效果等价于一个新的置换。这导致每条残差流的“身份”在深度方向上不断被重排,增加了 $H^{pre}$ 和 $H^{post}$ 需要追踪流位置的学习难度。
而 Identity 方案的优势在于,所有层使用同一个恒等置换:
- 流的语义一致性:流0永远在位置0,流1永远在位置1。
- 学习目标简化:$H^{pre}$ 和 $H^{post}$ 无需适应流的重排,只需学习“从哪条流读取信息”和“往哪条流写入信息”。
- 稳定的累积效应:累积乘积 $Π H^{res}_l = I$,既不会坍缩也不会引入混乱。
Identity 应该是最直观、最朴素的 $H^{res}$ 实现。目前尚不清楚为何原始的 HC 和 mHC 论文都没有提及这个消融实验。
背景简述:从 HC 到 mHC
标准 Transformer 的残差连接是单流的:$x_{i+1} = x_i + f(x_i, W_i)$。
Hyper-Connections (HC) 将其扩展为 $n$ 条并行的残差流(默认 $n=4$),更新公式变为:
$x_{l+1} = H_l^{res} · x_l + H_l^{post} · f(H_l^{pre} · x_l, W_l)$
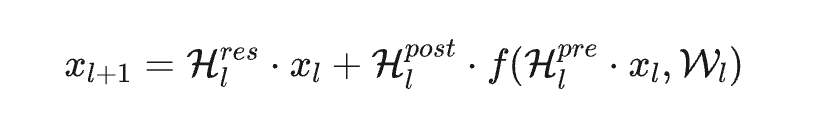
其中 $x_l$ 是 $n$ 条并行的残差流,三个可学习的映射分工如下:
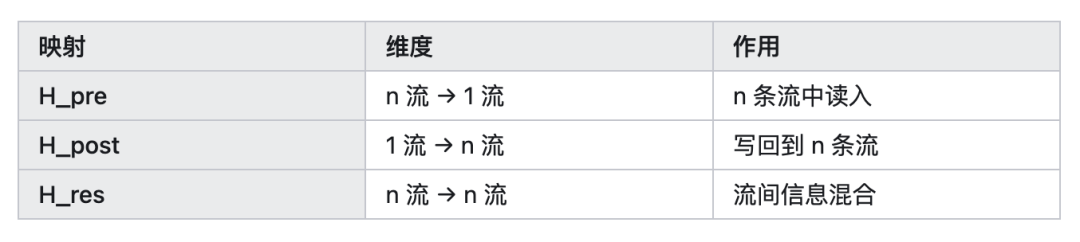
DeepSeek mHC 的核心创新是将 $H^{res}$ 约束到双随机矩阵流形(行和与列和均为1),以实现范数保持,防止多层连乘后信号爆炸(但并未保证信号不衰减)。我个人认为 mHC 论文的两大亮点是:1) 将 HC 的公式表述得非常清晰;2) 将激活函数从 tanh 换为值域非负的 sigmoid,这是一个很好的改进。

图3: mHC 核心计算过程的清晰表述。
为什么 Sinkhorn 约束可能弊大于利?
关键问题在于:$H^{res}$ 的精确双随机约束到底有多重要?实际上,跨流信息融合的关键机制在于投影 $\phi$。它将 $n$ 条流的信息先压平再动态投影,即使 $H^{res}=I$,生成的 $H^{pre}$ 和 $H^{post}$ 也是输入相关(input-dependent)的,跨流融合已然发生。
输入: x_l = [s, b, n*C] (4 条流 flatten)
Step 1: φ 投影(跨流信息融合已在此发生)
x̂’ · φ → [s, b, 2n] (identity 模式下只投影 2n=8 维)
φ 的输入包含了全部 4 条流的信息
Step 2: 激活
h_pre = sigmoid(α_pre · proj[:n] + b[:n]) ← 动态聚合权重
h_post = 2·sigmoid(α_post · proj[n:2n] + b[n:2n]) ← 动态扩展权重
Step 3: 聚合(跨流融合的显式体现)
aggregated = Σ h_pre_i · x_stream_i ← [s, b, C]
Step 4: 变换
output = f(aggregated) ← Attention 或 MLP
Step 5: 恒等残差 + 动态写回
x_{l+1} = I · x_l + diag(h_post) · f(...)
= x_l + diag(h_post) · f(...) ← 每条流独立保持残差
事实上,对 $H^{res}$ 施加双随机约束不仅可能用处有限,甚至可能有害。根据 Perron-Frobenius 定理,不可约的非置换双随机矩阵的次主导特征值 $|λ_2| < 1$。$L$ 层累积乘积的最小奇异值满足:
$σ_min(∏_{l=1}^L H_l) ≤ ∏_{l=1}^L |λ_min(H_l)|$
当 $|λ_min| < 1$ 时,该乘积会指数衰减至零。我们在 Qwen3-1.7B(28层,56个HC模块)上实测,Sinkhorn 版 $H^{res}$ 的最小特征值均值约为 0.49。粗略估计:
$σ_min ~ 0.49^{56} ≈ 10^{-17}$
实测累积乘积的最小奇异值约为 $10^{-18}$,与估计吻合。这意味着浅层信号经过数十个模块后,除主方向(均匀向量)外的信号分量几乎衰减殆尽。回顾图2也可直观看到,累积乘积在约10层后便坍缩为均匀矩阵。
此外,Sinkhorn-Knopp 采用20步迭代来近似投影,这不保证完全收敛,会引入近似误差(实测行和标准差约0.12),该误差会在多层中累积。
因此,当我们取 $H^{res} = I$ 时,与 Sinkhorn 约束的对比如下:

失败的尝试与有趣的发现
在得出 Identity 有效的结论前,我们尝试了多种变体,如 mHC-lite 的凸组合、Softmax 加权等看似合理的方法,但效果均不及原版 mHC。正交化(Cayley变换、Givens旋转)方案则导致梯度几乎不动,且允许负值引入的符号问题可能引发模型容量坍缩。
最后,分享一些通过内部工具绘制的分析图,揭示了 mHC 内部有趣的信道特性。例如,任意两层 $i$ 和 $j$ 之间的有效信道强度 $c_{ij}$,衡量了第 $i$ 层变换的输出有多少信号能传递到第 $j$ 层变换的输入:
$c_{ij} = h_j^{pre} · (Π_{k=i+1}^{j-1} H_k^{res}) · {h_i^{post}}^T$
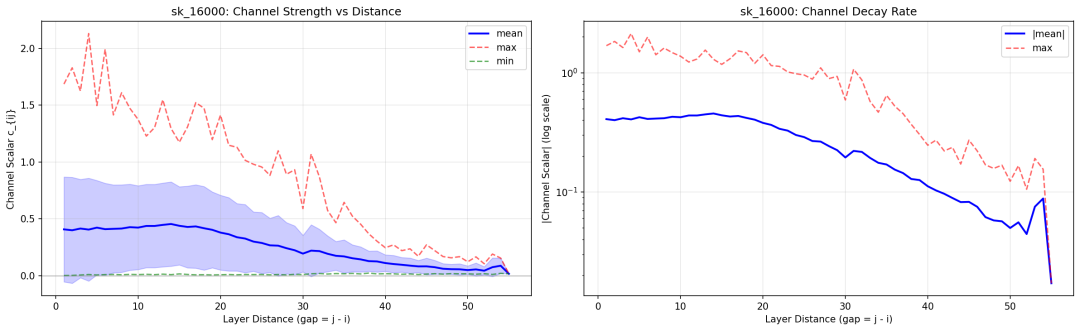
图4: 左图显示 layer gap 在 1-15 时,信道强度维持在 0.3~0.5;gap > 20 后明显衰减。右图在对数尺度下呈近似线性衰减。
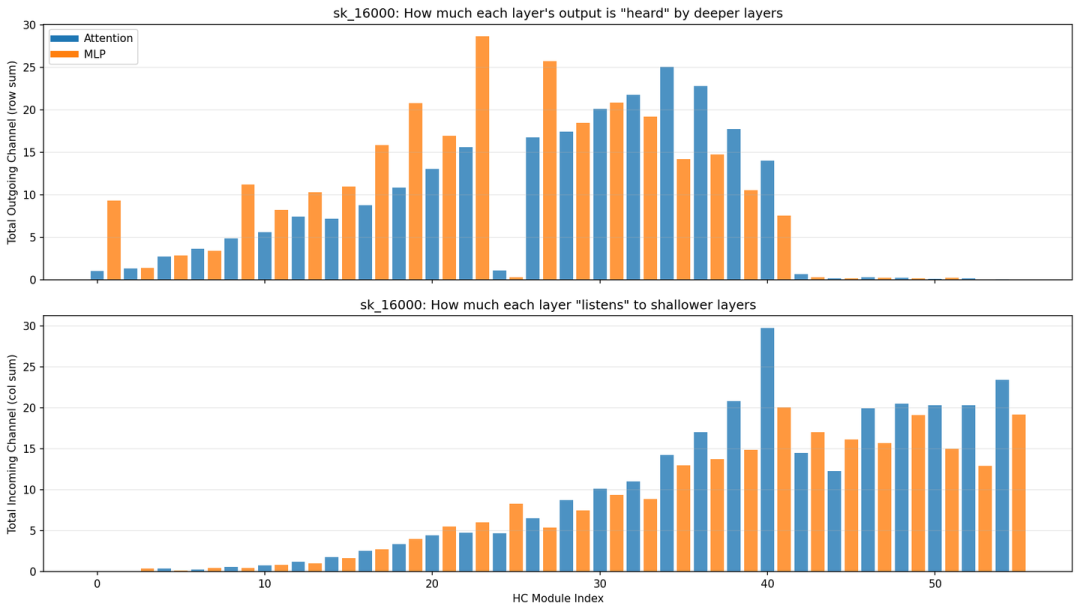
图5: 呈现“中间层辐射、深层汇聚”模式。模块 20-40 是核心信息枢纽,最后几层大量接收信号但几乎不发射,浅层信号则较弱。
而当 $H^{res} = I$ 时,信道公式简化为:
$c_{ij} = h_j^{pre} · I · {h_i^{post}}^T = h_j^{pre} · {h_i^{post}}^T$
此时,任意两层间的直达通信强度仅取决于它们各自的 $h^{pre}$ 和 $h^{post}$,完全不受中间层 $H^{res}$ 累积衰减的影响。
总结
总而言之,根据我们目前的实验,一个简单直接的改进是:将 DeepSeek mHC 中的 “m” (manifold constraint) 扔掉,换回最古朴的恒等矩阵 $I$ 即可。 这不仅在150B tokens的实测中表现更优,而且从原理上避免了双随机矩阵连乘的固有缺陷,简化了学习目标。
换一个角度看,这或许也免去了为 Sinkhorn-Knopp 算法开发专用高性能内核的工程之苦,对于 大模型预训练 的实践而言,算是一个皆大欢喜的发现。本文行文匆匆,难免有疏漏之处,但所述实验现象、结论与核心思路均经过实际验证。希望这些发现能为社区后续的模型架构探索提供一些不同的视角和参考。
 发表于 2026-3-3 03:58:22
|
查看: 153|
回复: 0
发表于 2026-3-3 03:58:22
|
查看: 153|
回复: 0
