近日,上海交通大学人工智能学院与小红书 Hi Lab 的联合研究团队发布了一项突破性工作,为大语言模型(LLM)的扩展之路开辟了全新的“第三条路径”。这项名为 JTok / JTok-M 的技术,通过为每个 Token 引入调制向量,实现了模型容量的低成本扩展,并在实验中展现出节省高达 35% 计算资源的潜力,为当前陷入成本困境的大模型发展提供了新的解题思路。
传统 Scaling 的困境与新路径的曙光
大模型的发展长期遵循着“Scaling Law”的指引:堆砌更多参数和数据,性能就会提升。然而,这条道路正变得越来越昂贵,其根本原因在于 参数规模与计算量的深度绑定。无论是简单的加深加宽(Dense 模型),还是引入稀疏激活的专家网络(MoE 模型),都未能从根本上打破这一魔咒。Dense 模型的算力需求随参数线性飙升,而 MoE 模型则面临着样本效率低、路由负载均衡困难、推理吞吐受限等一系列挑战。
LLM 是否还存在新的扩展方向,能带我们走出这个困境?
答案是肯定的。上海交大团队提出了一种全新的 scaling 维度:Token-indexed parameters。该方法既不依赖主干参数扩展,也不稀疏计算路径,而是通过为每个 Token 引入调制向量,以“查表 + 逐元素调制”的方式提升模型容量,且几乎不增加核心算力和显存开销。
具体而言,JTok(静态版本)和 JTok-M(动态版本)可作为插件形式挂载在 Transformer 每一层,构建 Token 与主干路径的交互桥梁:
- 在从 650M 到 61B 的模型规模中,JTok-M 显著降低训练损失。
- 在下游任务中实现大幅提分:例如 MMLU 提升约 4.1 个点,ARC 提升 8.3 个点,CEval 提升 8.9 个点。
- 核心价值:达到相同性能,JTok-M 可直接节省约三分之一的算力需求,并且其扩展效果呈现出清晰可预测的幂律规律。
这项创新意味着,未来我们可能不必加算力、不依赖更多数据,仅靠结构设计与查表调制,就能持续扩大模型容量,重塑性能与计算效率的边界。
技术核心:轻量插件式改造
算法设计的核心思想是用 Token-ID 直接查表取得调制向量,再以元素级乘加方式注入主干,实现模型容量提升,而 FLOPs 几乎不变。
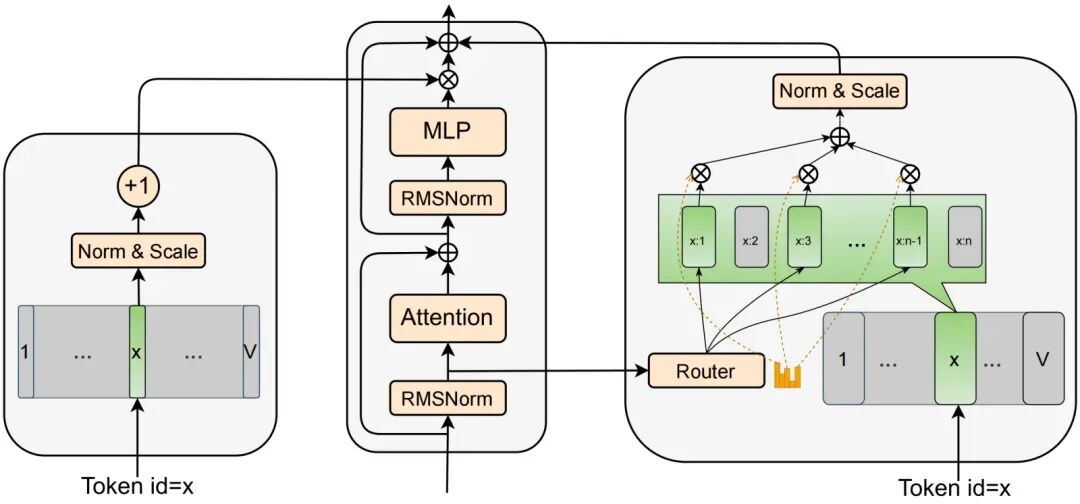
JTok:静态调制
与传统扩展方式不同,JTok 不是加深加宽网络结构,而是为每个 Token 引入一个专属调制向量,并在 Transformer 各层通过逐元素乘法对 MLP 残差进行调制,实现无侵入式容量注入。
- 存储:所有调制向量保存在一个嵌入表中。
- 查表:每个 Token 在每层通过其 ID 查表获得调制向量。
- 调制:调制向量经过归一化后,与当前层 MLP 残差进行逐元素相乘,再写入残差路径。
整个过程无需修改主干结构,仅通过轻量插件式外挂就完成了有效参数的注入,且不会显著增加 FLOPs,也不引入额外通信瓶颈。
JTok-M:动态调制
JTok 虽好,但有两个小局限:一是参数量扩展不够灵活;二是同一个 Token 在不同上下文里,语义本就千差万别,总用同一个调制向量,不够贴合实际场景。JTok-M 正是为此而生。
同一个 Token 在不同上下文下语义千差万别,调制向量也应因境而异。
JTok-M 引入了两个核心机制:
- 调制向量池:每个 Token 不再只有一个向量,而是拥有一组候选向量,构成语义子空间。
- 上下文路由器:根据 Token 当前上下文的隐状态动态选择 top-K 个向量并加权融合,形成最终调制向量。
这种机制实现了语义敏感、稀疏激活与插件扩展的三重优势。为了保证各向量充分参与训练,JTok-M 还引入了类似 MoE 的路由负载均衡损失。
工程实现:如何实现三分之一的算力节省?
JTok / JTok-M 虽引入了大量新参数,但在系统设计上采取了“查表式插件 + 旁路异步调度”的范式,使得计算与访存压力得到了有效隔离与隐藏:
- 计算重叠:查表操作可与主干计算异步重叠,访存开销被调度隐藏。
- 访问合并:利用 Token 频率的长尾分布,同一 Token 的多次查表可合并访问,大幅减少内存压力。
- 灵活部署:训练阶段支持嵌入并行,推理阶段支持 CPU offload,仅传输需要的向量片段。
在这一系列优化的加持下,即便把 JTok-M 扩展到相当可观的容量,训练吞吐损失也不到 7%;推理阶段的吞吐损失控制在 7.3% 以内,而 GPU 侧几乎不需要额外的显存占用。
理论验证:重新定义 Scaling Law
Scaling Law 是大模型发展的指南针,但它也设下了“性能提升必须同步增加计算量”的代价等式。JTok-M 的出现,打破了这一绑定。
作者从理论层面将 Token-indexed 参数融入经典的 Scaling Law 框架,提出了 有效参数(N_eff) 的关键概念:
$$ N_{\text{eff}} \equiv N_c + \gamma(\rho)N_n = N_c(1 + \eta\gamma(\rho)) $$
其中,$N_c$ 是主干激活参数,$N_n$ 是 JTok-M 新增参数,$\eta = N_n / N_c$ 是扩展比例,$\gamma$ 是考虑稀疏性的有效折扣因子。
代入 Scaling Law 公式后,规律显现:JTok-M 并未改变模型对算力、数据的依赖逻辑,只是让整个“性能-算力”帕累托前沿曲线整体向下平移。这意味着,不管模型大小,要达到同样性能,JTok-M 都能稳定地节省算力。
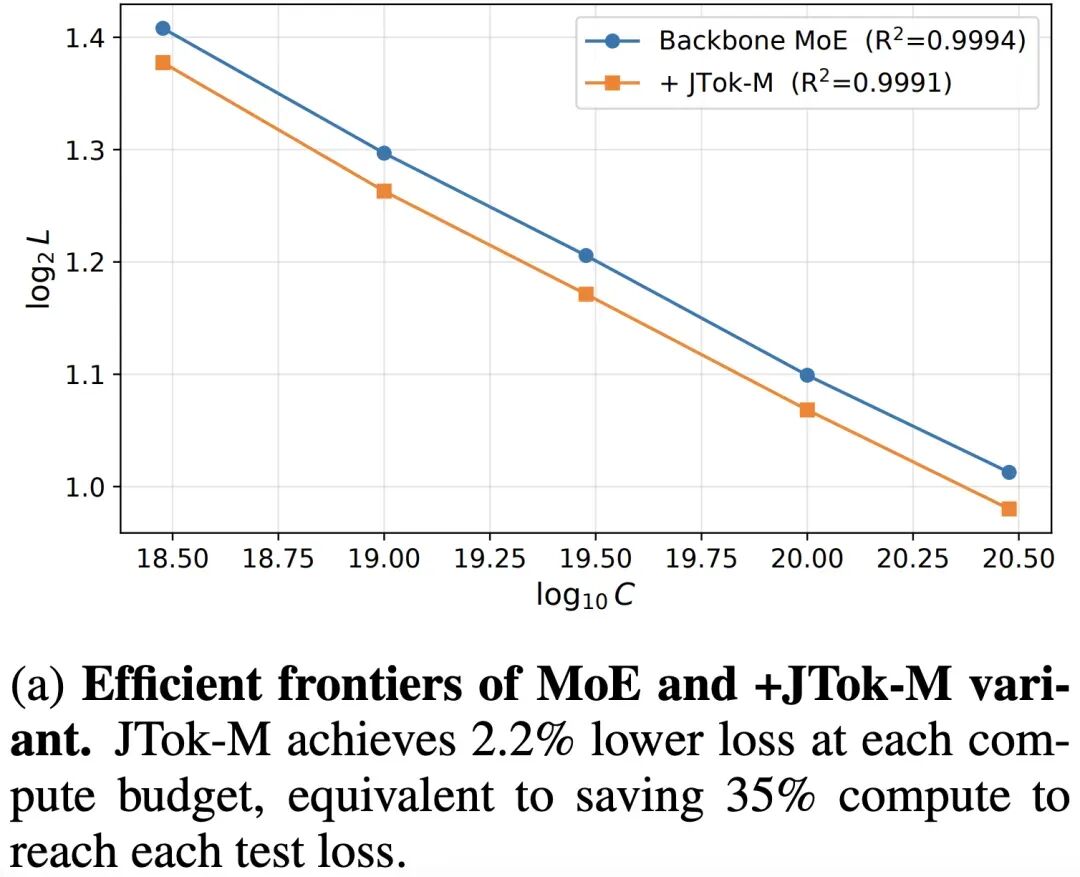
(a) MoE 与 +JTok-M 变体的效率前沿。JTok-M 在每个计算预算下实现了 2.2% 更低的损失,相当于节省 35% 的计算量以达到每个测试损失点。
严格的实验完全验证了这一猜想。计算表明:要达到和原生 MoE 同等的模型性能,JTok-M 能直接节省 35% 的训练算力,且该比例在不同规模下均成立。
另一个关键问题是:JTok-M 自身的参数扩容后,效果如何?实验显示,模型的验证损失随着 JTok-M 参数扩展比 $\eta$ 的增加,呈现出近乎完美的对数线性下降趋势。
$$ C_{\text{JTok-M}}(L^*) = \frac{1}{1 + \eta\gamma(\rho)} C^*_{\text{base}}(L^*) $$
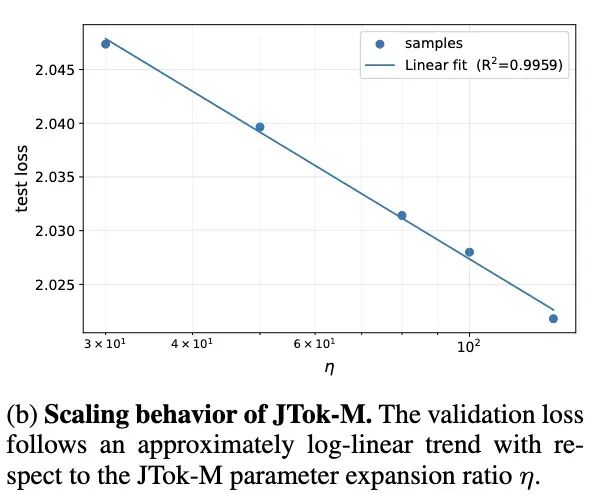
(b) JTok-M 的缩放行为。验证损失随 JTok-M 参数扩展比 η 呈近似对数线性趋势。
这表明,Token-indexed 参数本身就是一个全新的、正交的缩放维度。开发者可以像依据传统 Scaling Law 一样,精准规划 JTok-M 的参数规模以达成性能目标。
下游任务:全面能力提升
理论的优美需要落地验证。研究团队在涵盖知识、推理、代码、数学四大类共 14 个子任务上进行了全面测试。
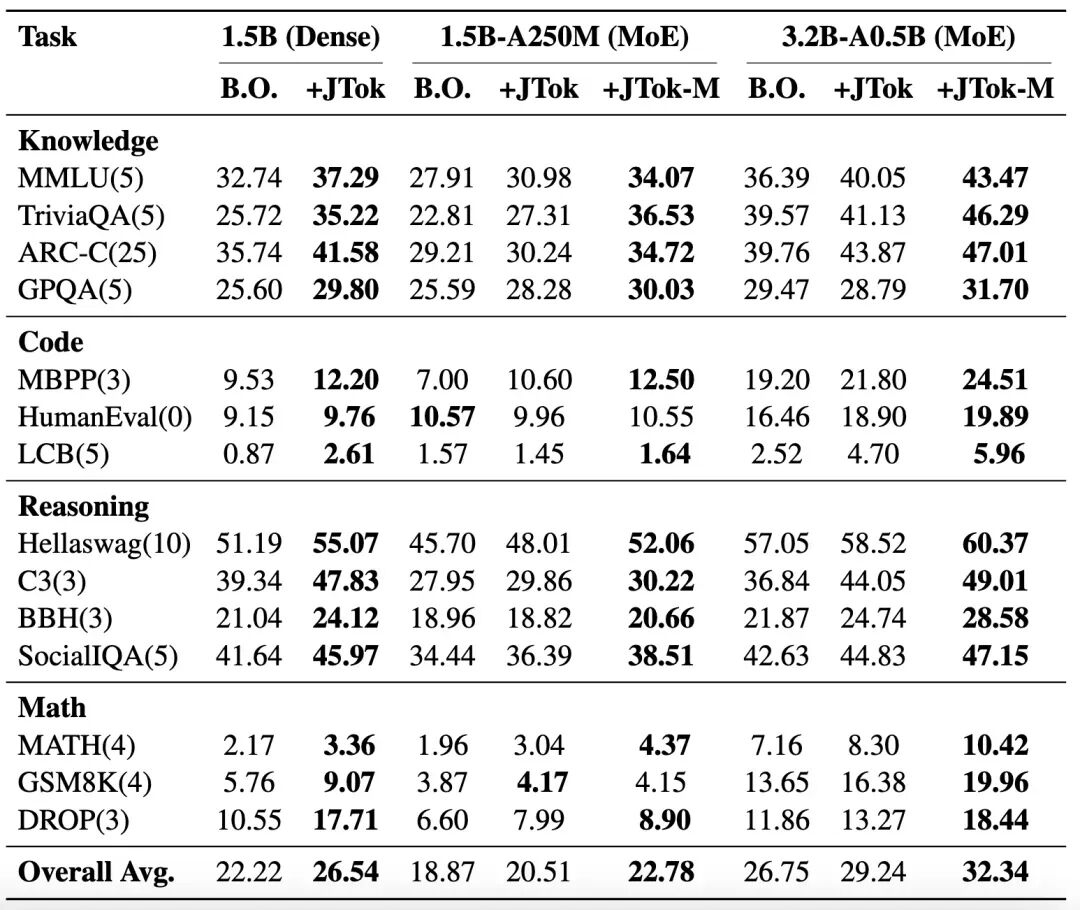
- Dense 基座:在 1.5B 参数的 dense 模型上,添加 JTok 模块后,14 项任务平均准确率提升 4.32 个百分点,其中 MMLU 提升 4.6,ARC-C 提升 5.8。
- MoE 基座:JTok-M 表现更为惊艳。在 3.2B 总参的 MoE 模型上,平均准确率提升 5.59,其中 ARC-C 提升 7.25,数学推理任务 GSM8K 提升 6.31。
- 超大模型验证:在总参 61B 的 MoE 模型上,JTok-M 在训练早期就展现出更高的样本效率,最终在 MMLU、ARC-C、CEval 等困难任务上带来 4 到 9 个点的显著提升。
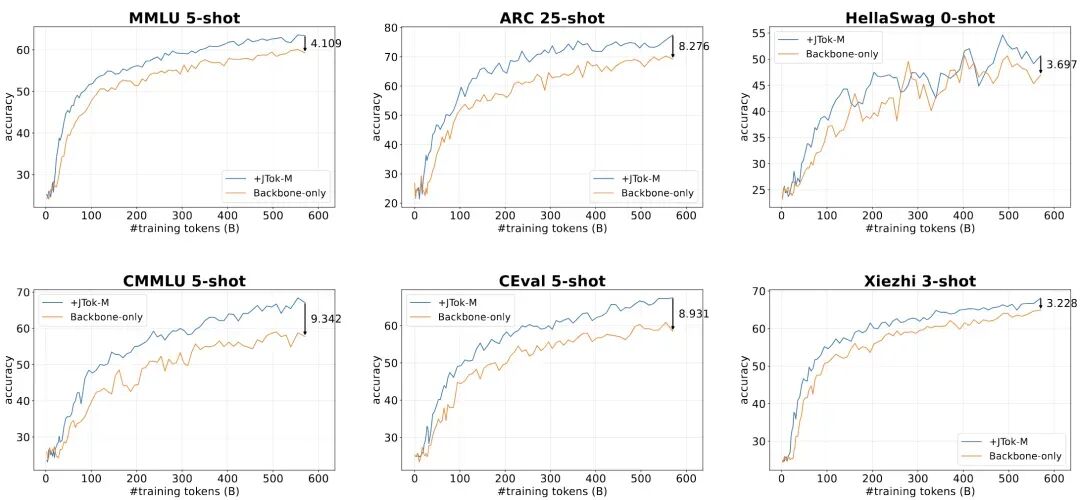
核心结论是:JTok/JTok-M 具备极强的适配性(Dense/MoE,小模型/大模型)和针对性(越是复杂推理任务,提升越显著),恰好满足了大模型工业化落地中对效能与成本的苛刻要求。
相关工作对比
近期,通过扩展 Embedding 来突破参数效率瓶颈成为一个热门方向。除了 JTok,业界还有 DeepSeek 的 Engram 和 Meta 的 STEM 等工作。虽然目标相似,但三者在设计哲学和核心洞察上各有侧重。

- Engram (DeepSeek):定位为静态知识查找机制,作为 MoE 的互补稀疏维度,核心揭示了计算与记忆间的最优分配规律。
- STEM (Meta):通过 Token 级别静态查找替换 FFN 投影,兼顾知识容量与模型可解释性。
- JTok (上海交大 & 小红书):探索嵌入参数作为正交、独立的扩展维度,旨在彻底解耦模型容量与 FLOPs,并系统验证了其优化帕累托前沿的能力。
这些工作共同描绘了通过 参数优化 和结构创新来延续大模型 Scaling Law 的广阔前景。
结语
传统 Scaling Law 主要围绕参数规模(N)与数据规模(D)两个维度。MoE 试图解耦,但仍困于计算之中。JTok-M 的意义在于,它引入了一种新的扩展形式(Token-indexed capacity),并完成了从理论推导、工程实现到实验验证的完整闭环,从而将 Scaling Law 从二维推向了三维:参数、数据、Token-indexed 结构将共同塑造未来 LLM 的成长路线。
它不仅是一个高效插件,更是对大模型如何持续、经济地扩展的一次深刻思考与重新定义。
彩蛋:JTok,技术上代表 Joint Token。其命名也蕴含着对上海交通大学(Jiao Tong University)的致意,恰逢交大130周年校庆。
 发表于 2026-3-3 04:54:43
|
查看: 162|
回复: 0
发表于 2026-3-3 04:54:43
|
查看: 162|
回复: 0
