以往需要从网站上抓取数据时,我通常会打开 IDE,准备写一些 Python 脚本,要么是去揣摩 API,要么就是调教 Puppeteer 或 Playwright 这类无头浏览器。总得来说,免不了一番代码调试和参数摸索。
现在情况变了。有了像 OpenClaw 这样的工具,你只需要告诉它“我想要什么”,它就能帮你拿到。省去了破解 API 的麻烦,也规避了账号被封的风险。
关键在于,有两种非常简便的方法,基本上能应对任何网页的数据抓取需求。
在介绍具体方法前,有一点需要明确:包括 OpenClaw 在内的多数智能体都内置了类似搜索引擎的网页抓取(web-fetch)能力。但这种能力更适合获取宽泛的、概述性的信息,对于精确抓取——比如某个特定 B 站 UP 主的视频列表、某位小红书博主的全部笔记——就显得力不从心了。
方法一:利用 OpenClaw 内置的浏览器能力
只要你安装了 OpenClaw,这个能力就已经就绪了。
当你明确指令它“打开浏览器获取 xxx 信息”,或者直接给它一个网址时,它有时会自动触发,启动一个独立的 Chrome 浏览器实例。
这种方式比较适合目标明确的单个或多个网站。使用时,最好明确指示“打开浏览器”。不过,这种方式启动的浏览器没有你日常使用的登录状态(cookies),因此更适合无需登录就能访问的公开页面。
如果需要抓取需要登录才能查看的内容(比如小红书博主主页),就需要你先在它打开的浏览器里手动登录,然后告诉 OpenClaw “我已登录,请继续”。
最近我让它尝试抓取 B 站的热门视频列表。过程中遇到了一个小问题,但它自行诊断并修复了,最终成功拿到了数据。

在执行期间,OpenClaw 会自动打开一个浏览器窗口,访问目标页面,整个过程你都可以亲眼看到。
方法二:万能数据抓取(推荐)
如果你觉得第一种方式对于需要登录的网站还是有些繁琐,那么接下来这个方法堪称“无敌”。
OpenClaw 为此专门推出了一个浏览器插件,名为 OpenClaw Browser Relay。安装它之后,OpenClaw 就能直接利用你当前 Chrome 浏览器中的登录状态去抓取数据,真正做到“所见即所抓”。
安装步骤
-
下载插件
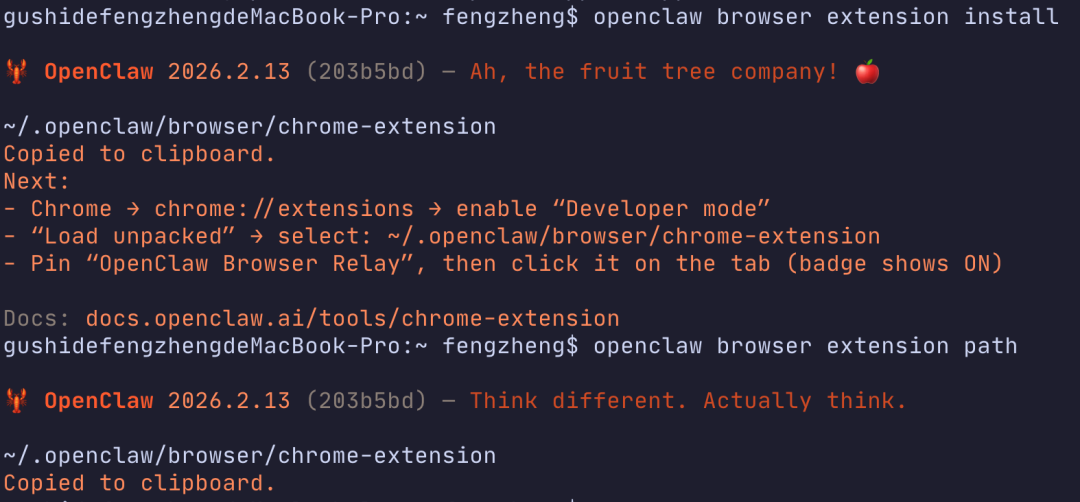
在终端执行以下命令,插件文件会被下载到本地。
openclaw browser extension install
-
获取插件路径
接着执行这个命令,它会返回插件在本地的存放路径。
openclaw browser extension path
通常,路径类似于:
~/.openclaw/browser/chrome-extension
-
加载到 Chrome
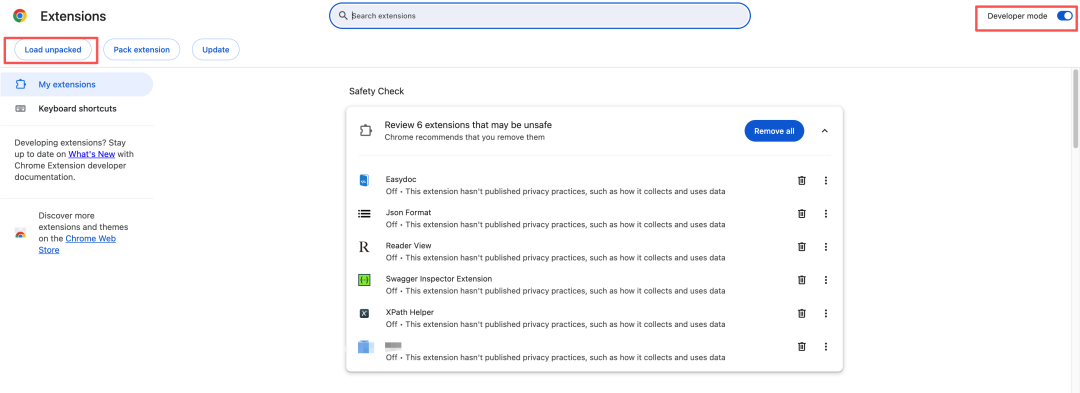
在 Chrome 浏览器地址栏输入 chrome://extensions/,打开右上角的“开发者模式”。
点击“加载已解压的扩展程序”按钮,选择上一步获取到的插件目录路径。
-
验证与固定
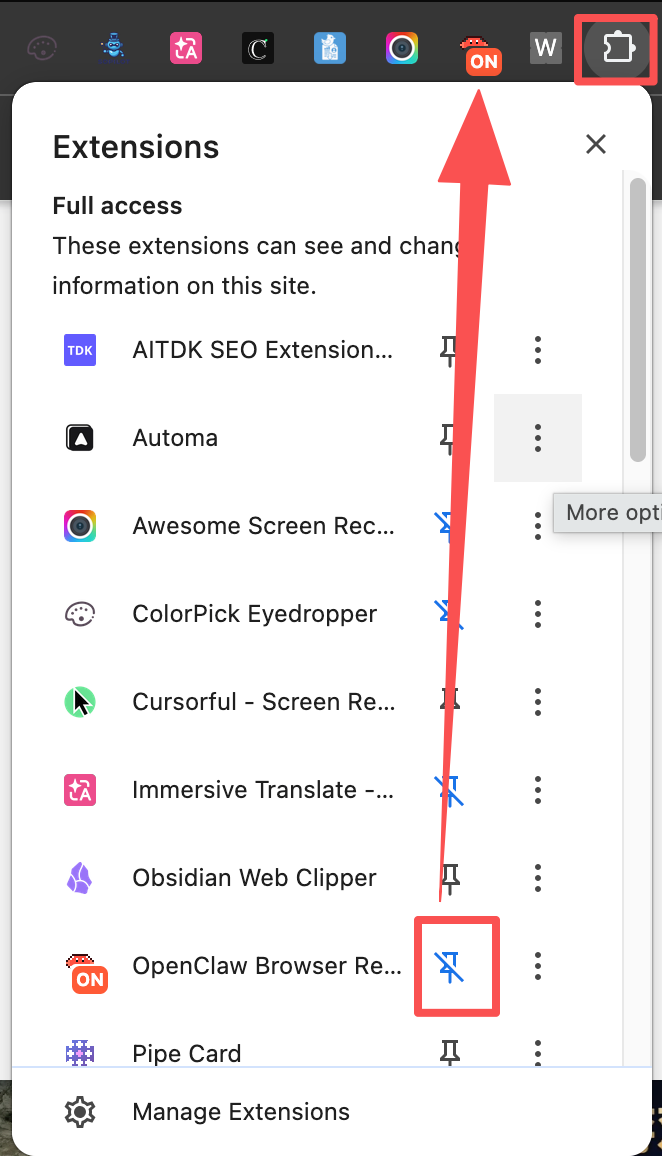
加载成功后,会自动打开插件的设置页面。看到这个页面说明安装正常。
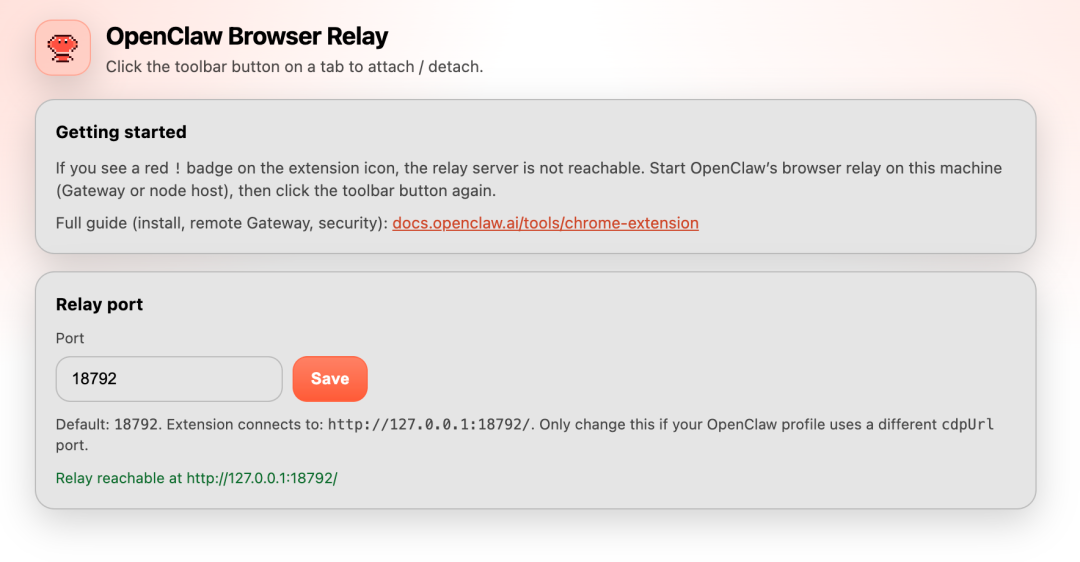
点击浏览器工具栏最右侧的“扩展程序”图标,在弹出的列表中,找到“OpenClaw Browser Relay”,点击其旁边的图钉图标,将其固定在工具栏上。固定后,工具栏会出现一个大龙虾图标。
使用 Browser Relay 抓取数据
实战演示一下如何用这个插件配合 OpenClaw 抓取数据,整个过程非常简单。
目标:抓取我(示例博主)的小红书主页上,点赞数最高的前 5 篇笔记。
步骤:
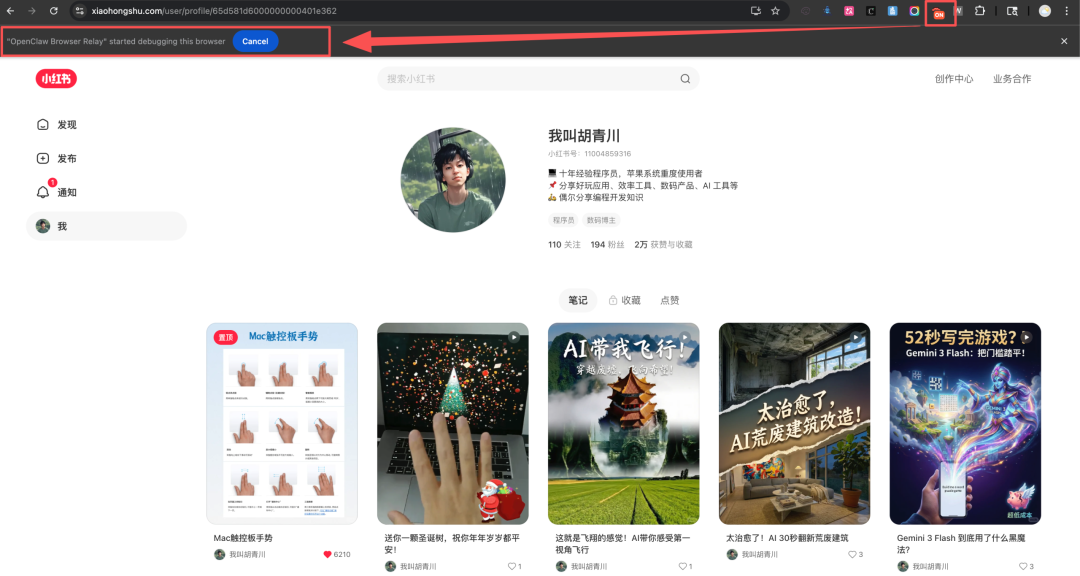
- 用 Chrome 浏览器打开目标小红书博主主页。
- 点击工具栏上固定好的大龙虾图标。点击后,图标上会显示一个红色的“ON”标记,表示与 OpenClaw 的连接已成功建立。
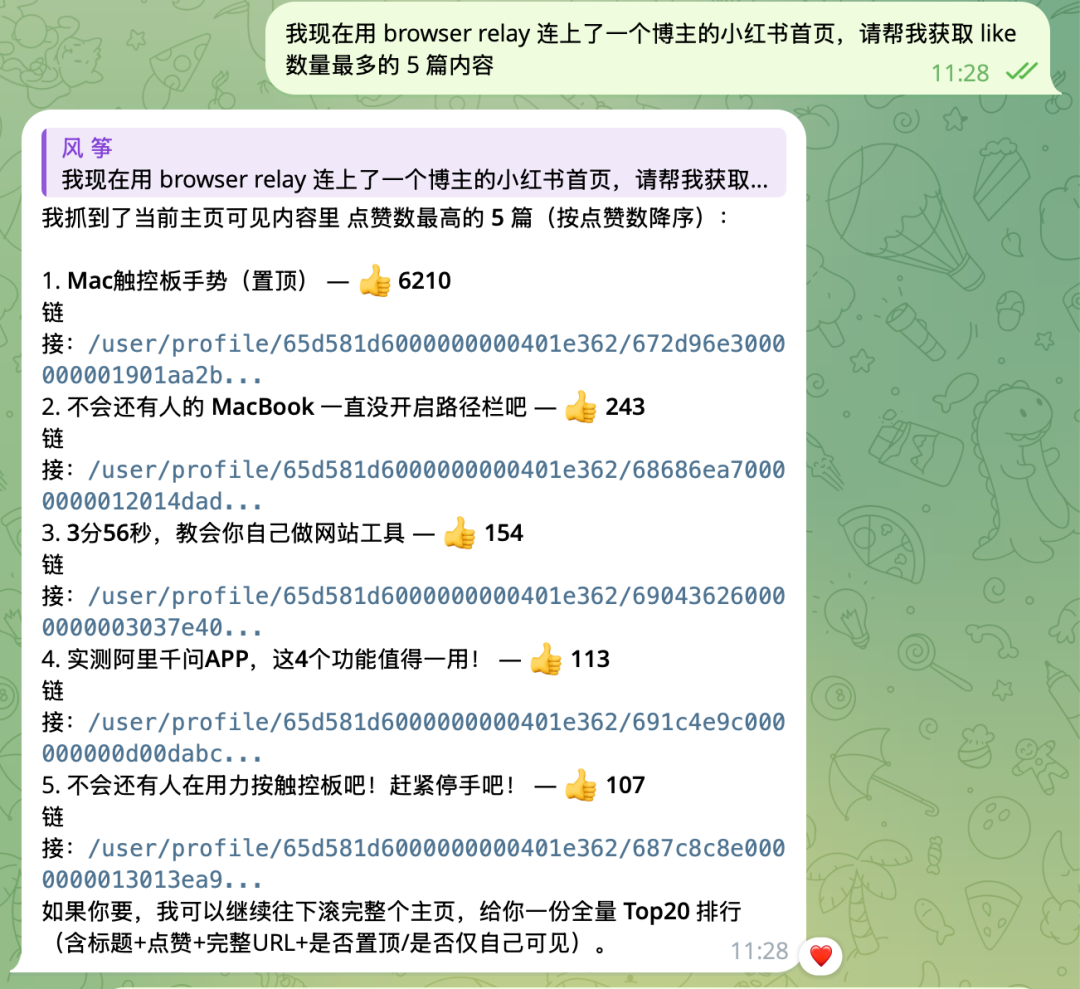
- 连接成功后,直接告诉 OpenClaw:“我现在用 browser relay 连上了一个博主的小红书首页,请帮我获取 like 数量最多的 5 篇内容。”
- 稍等片刻,它就会返回结构清晰的结果。
这种方式的优势在于,你相当于将自己已经登录了各类网站的浏览器“委托”给了 OpenClaw。它可以直接复用你的登录状态,无需重复验证,抓取效率极高。
不只是抓数据
实际上,这个 Browser Relay 插件的能力远不止于数据抓取。它在辅助开发浏览器插件方面尤其好用。前几天我就用它快速构建了一个小插件。
开发过程非常直观:我打开一个网页,让它“看”一眼记住页面结构;我点击某个按钮,就告诉它“我点击了 XX 按钮”;弹出新页面后,再让它分析……如此反复,直到完成整个操作流程。最后,我让它将这一系列操作整理成一个可运行的 Chrome 插件代码,经过简单测试和微调,一个可用的插件就诞生了。这种与 AI 实时交互、协同“编程”的体验,极大地提升了开发效率。
总结与推荐
强烈推荐你尝试第二种“插件中继”的方法,对于定向、精确的网页数据抓取任务来说,它方便得不可思议。
从手动编写爬虫代码到用自然语言指挥 AI 代劳,这种转变不仅降低了技术门槛,更重塑了我们获取和处理网络信息的流程。无论是用于市场分析、技术文档调研还是内容聚合,OpenClaw 提供的这套工具链都值得深入探索。你可以在 云栈社区 找到更多关于自动化工具和 Python 实战应用的讨论。
 发表于 2026-3-3 04:57:21
|
查看: 284|
回复: 0
发表于 2026-3-3 04:57:21
|
查看: 284|
回复: 0
