C++ 里的虚表不是历史包袱,而是一个关键设计。
如果你曾深受 ABI 不兼容、多重继承导致崩溃、析构顺序错乱等问题的困扰,就会明白虚表并非一个“凑合能用”的方案。它实际上是 C++ 在零开销抽象、异常安全、跨平台 ABI 统一以及工程可维护性这四大核心约束之间,找到的唯一可行路径。
它通过引入一张共享的函数指针表(虚表),换来了以下关键收益:
- 对象内存占用最小化
- CPU 缓存命中率最大化
- 构造与析构语义精确可控
- 使得 GDB、perf、core dump 等工具能够全链路可调试
这并非一种妥协,而是一场精密的软件工程胜利。相比之下,那些试图绕过语言机制、手写函数指针以求“更灵活”的做法,看似聪明,实则可能是在亲手拆除软件系统的承重墙。
一、虚表存在的根本原因
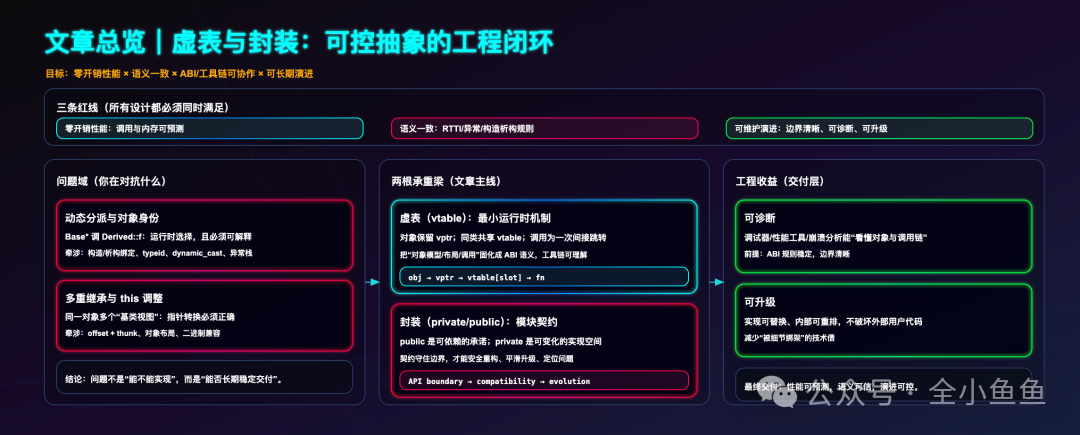
很多人可能会想,让“每个对象都携带一组函数指针”岂不是更灵活?但 C++ 多态(Polymorphism)的核心目标,从来不是允许你在运行时给一个 Dog 对象临时塞入 Cat 的叫声方法。
它的核心诉求是建立一套统一、可靠且高效的运行时机制,具体包括:
- 基类指针或引用能正确调用到派生类的实现;
- 支持
dynamic_cast、typeid 以及异常栈展开等运行时类型信息(RTTI)操作;
- 兼容单继承、多重继承乃至复杂的虚继承体系;
- 虚函数调用的运行时成本需控制在约等于一次间接跳转;
- 确保跨编译器、跨平台、跨动态链接库(DSO)的 ABI 一致性。
这些目标,依靠手写分散的函数指针方案几乎不可能统一实现。
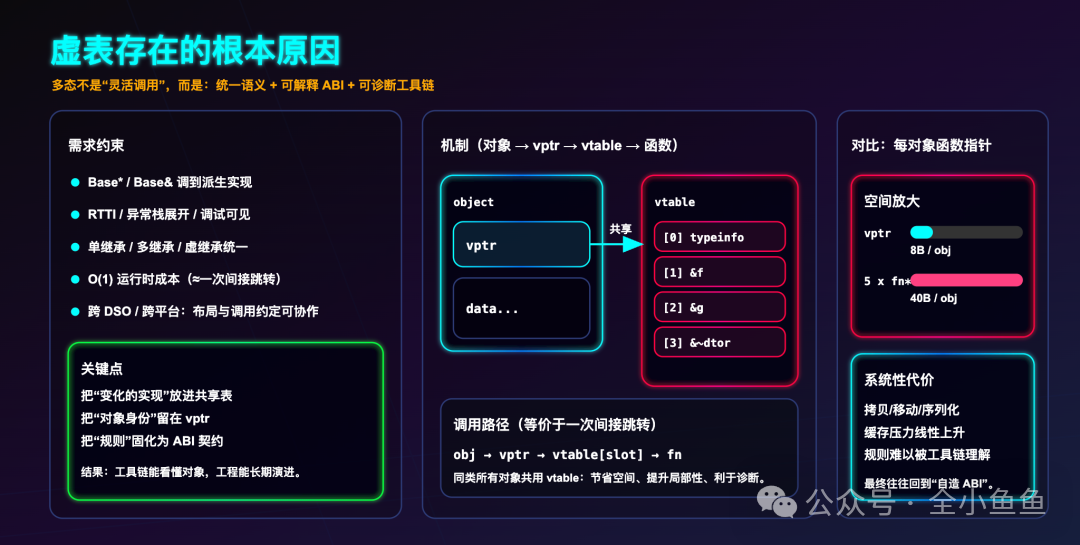
我们首先看空间效率。 假设一个类拥有 5 个虚函数:
- 虚表方案:每个对象仅存储一个指向虚表的指针(vptr,通常为 8 字节),所有同类对象共享同一张虚表。
- 函数指针方案:每个对象需要存储 5 个独立的函数指针(5 * 8 字节 = 40 字节)。
当实例化 100 万个对象时,前者仅占用约 8 MB 内存,后者则高达 40 MB。在对象拷贝、移动或序列化时,后者带来的开销会成倍增加。
更严重的是对缓存局部性的影响。虚表集中存放,更容易被 CPU 缓存命中;而分散在每个对象中的函数指针则会导致内存访问模式随机化,进一步拉低性能。
其次看构造与析构语义。 C++ 标准明确规定:在基类的构造函数中调用虚函数,应绑定到基类自身的实现;只有当对象被完全构造后,虚函数才绑定到最终派生类的版本。这一精妙语义是通过编译器在构造过程中动态切换对象的 vptr 来实现的:
struct Base {
Base() { foo(); } // 此时 vptr 指向 Base 的虚表
virtual void foo() { }
};
struct Derived : Base {
Derived() { /* 构造完成,vptr 已更新为 Derived 的虚表 */ }
void foo() override { }
};
如果使用手动的函数指针,你不得不在每个构造函数的开头小心翼翼地重置所有指针,稍有遗漏就会导致方法调用错误。而在析构时,如果没有虚表机制来保证正确的析构顺序,情况将更加危险。
二、多重继承与ABI是函数指针方案的死穴
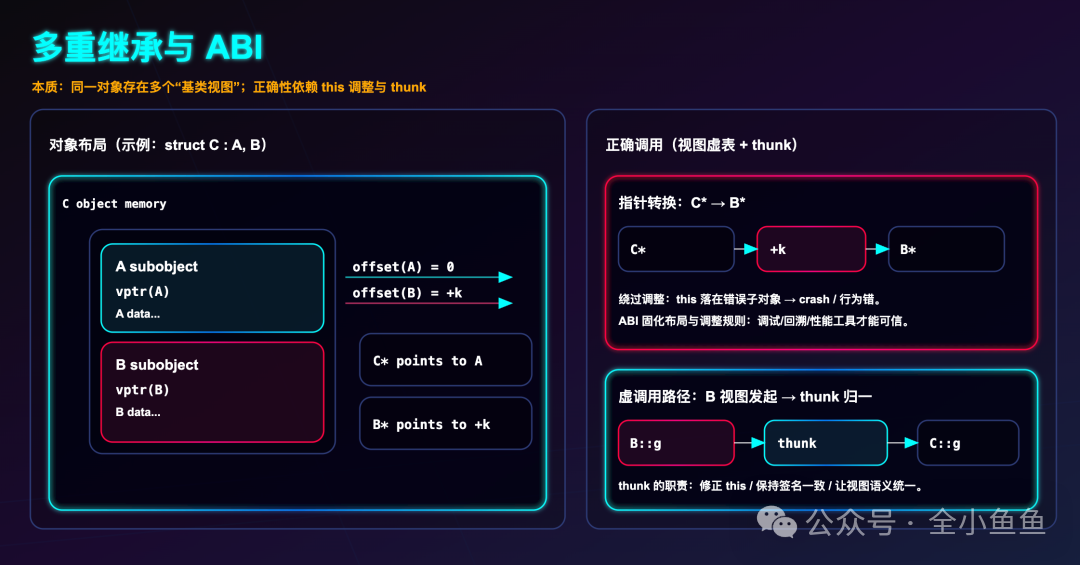
让我们审视一个经典的多重继承场景:
struct A { virtual void f(); };
struct B { virtual void g(); };
struct C : A, B { void f(); void g(); };
当你 new 一个 C 对象时,其内存布局是 A 子对象在前(包含一个 8 字节的 vptr),B 子对象紧随其后(包含另一个 8 字节的 vptr)。
当你将 C* 类型的指针转换为 B* 时,编译器会自动为其加上一个偏移量(例如 8 字节),使得指针正确指向内存中 B 子对象的起始位置。因为 B 子对象起始处的那个 vptr,指向的是为 B 视图特化的虚表。如果手动绕过这个偏移调整,在调用 g() 时,this 指针将错误地指向 A 子对象的位置,程序要么崩溃,要么调用到错误的函数。
这一切的幕后功臣是编译器依据稳定的 ABI 约定生成的布局规则和自动创建的 thunk 函数。这些复杂细节无需开发者手动编写,但却被整个工具链所理解和依赖:GDB 能据此还原对象真实类型,perf 能统计 C::g() 被调用的次数,core dump 分析工具能告诉你崩溃时对象的完整身份。
而如果试图用手写函数指针来模拟这一整套机制,这些能力将全部丧失。你需要自行计算偏移、维护多张函数表、正确处理 this 指针调整——这已经不是在编写业务逻辑,而是在重新发明 C++ 的对象模型轮子。
三、运行时替换方法指针:看似灵活,实则埋雷
表面上看,允许在运行时替换对象的函数指针似乎提供了极大的灵活性,但这种做法会引入巨大的系统性风险。
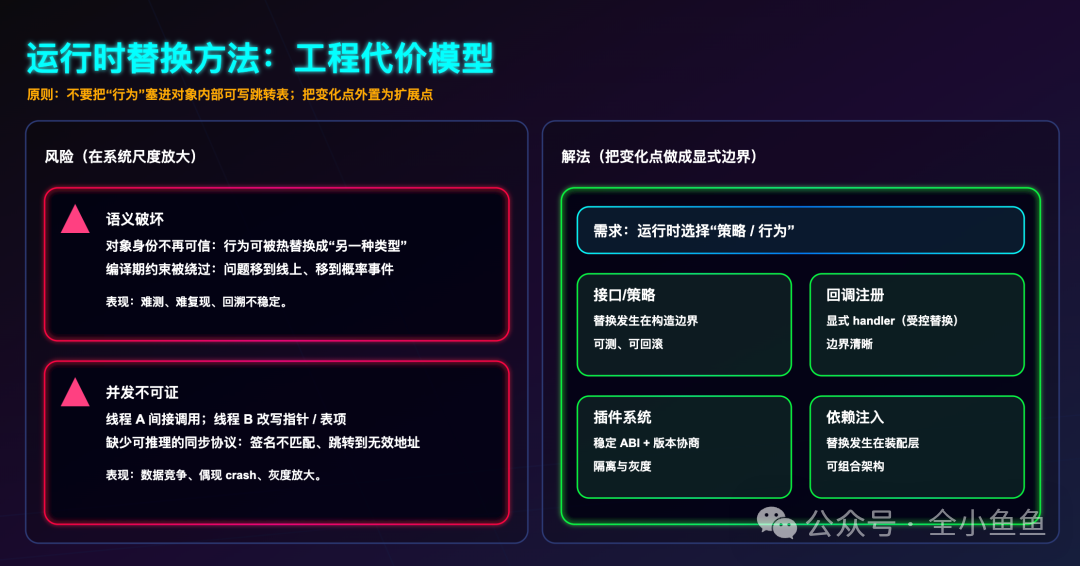
1. 破坏了面向对象的基本假设
对象在其生命周期内应保持其类所定义的不变量,并遵循里氏替换原则。如果外部代码可以随意篡改其方法指针,那么任何依赖于“Dog 对象总是会调用 bark() 方法”的代码,都可能在某次调用时突然执行了 meow() 的逻辑。这类错误不会在编译期被捕获,也难以在单元测试中稳定复现。
2. 线程安全性几乎无法保证
修改函数指针本身并非原子操作。如果一个线程正通过某个指针调用方法,而另一个线程同时修改了这个指针的值,可能导致前一线程跳转到一个无效的地址,或者以错误的参数调用函数,从而直接引发程序崩溃。
真正需要在运行时动态变更行为的场景,软件工程实践中早已有成熟且安全的设计模式应对,例如:策略模式、回调注册机制、插件系统或依赖注入。这些模式将变化点外置为明确的、受控的边界。
例如,使用标准库的 std::function 实现回调:
class HttpClient {
std::function<void(Response)> on_success_;
public:
void set_handler(std::function<void(Response)> h) {
on_success_ = std::move(h);
}
void send(Request req) {
// ... 网络请求逻辑
if (on_success_) on_success_(resp);
}
};
四、Private 是模块契约,而非安全锁
C++ 中的 private 访问修饰符并非坚不可摧的安全机制——通过指针偏移、联合体(union)、模板特化甚至宏定义,理论上都可以绕过它。
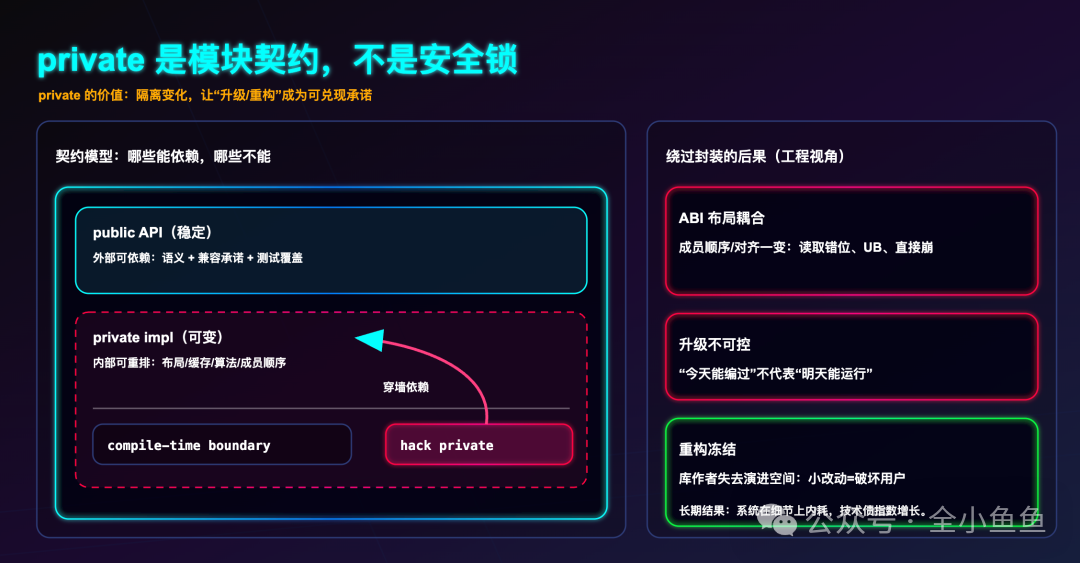
但它存在的根本目的不是为了防范恶意攻击,而是为了在模块间建立清晰的契约。
private 向使用者宣告:“这些成员是内部实现细节,未来可能会发生变化,请不要依赖它们。”public 则承诺:“这些是稳定的对外接口,我保证其向后兼容性。”
正是有了这份契约,库或模块的作者才能放心地重构内部逻辑、优化数据结构,而不必担心会破坏下游用户的代码。一旦允许外部代码通过 Hack 手段绕过 private 边界直接访问或修改内部成员,这份契约便荡然无存。今天你通过技巧访问了一个私有字段,明天库升级时内部布局发生改变,你的代码将直接崩溃,且原因难以追溯。
五、C++ 追求的是可控的抽象
有人抱怨 C++ 过于复杂,虚表、多重继承、ABI……规则繁多。但值得思考的是:这些规则并非枷锁,而是保障大型系统长期稳定演进的护栏。
虚表守护的是性能与语义的高度一致性,而 private 守护的是模块间清晰的信任契约。当你使用 #define private public 这类宏来破坏封装时,你击穿的不是一道访问控制墙,而是整个团队对接口稳定性的基本信任。
真正的灵活性,从来不是依靠 Hack 和取巧实现的,而是通过策略模式、回调、依赖注入这些显式、安全、可测试的工程机制来达成的。
C++ 的设计哲学,从来不是允许开发者“为所欲为”,而是在绝不牺牲运行时性能的前提下,为你提供一套能够构建可长期演进、可维护的大型系统的工具和规则。因此,下次当你觉得“绕过封装会更方便”时,或许应该先问问自己:我是在寻求一个健壮的解决方案,还是仅仅贪图一时编码的便利?
毕竟,所有在设计阶段省下的时间,未来都可能以十倍的调试和维护成本来偿还。对于更多关于虚表和对象模型的深入讨论,欢迎在云栈社区与大家交流。
 发表于 2026-1-15 06:11:27
|
查看: 145|
回复: 0
发表于 2026-1-15 06:11:27
|
查看: 145|
回复: 0
