提到系统设计面试,一道关于“亿级用户微信步数排行榜”的题目堪称经典。一位求职者就因为在字节跳动一面中对此题回答不当而遗憾止步。
面试官抛出的问题是:“请你设计一个支持上亿用户的步数排行榜系统,要求能实时查看好友间的排名,你会如何实现?”
这位朋友的初步想法很直接:用MySQL建表,查的时候用 ORDER BY steps DESC 加分页不就行了?结果可想而知,面试官对这个答案并不满意。
这道看似平易近人的题目,实则是一个融合了海量数据高并发写入、实时查询性能与存储扩展性的综合性难题。仅仅回答“用MySQL”,无疑会踏入面试官预设的考察陷阱。本文将为你拆解这道题的完整设计思路与方案细节。
为什么这道题能难住众多候选人?
要交出满意的答卷,首先需要理解系统面临的四大核心挑战:
- 写入洪峰 🤯:上亿用户在特定时段(如晚间)集中上报步数,瞬间的并发请求量极为巨大。
- 查询性能 😨:好友排行榜要求近乎秒级的刷新速度。若对亿级记录的MySQL大表直接进行
ORDER BY 排序,数据库将不堪重负。
- 存储成本 🕳️:以亿级用户、每人每天一条记录计算,仅一个月的数据量就高达数十亿条。使用传统关系型数据库,存储成本与扩展性将成为巨大瓶颈。
- 关系动态 🕸️:每个人的好友列表各不相同,无法预先计算一个通用的排行榜。查询时必须实时拉取好友关系,增加了查询链路的复杂度。

核心方案一:写入流程 — “异步解耦与流量削峰”
要应对写入洪峰,采用同步、强一致的硬扛策略绝非上策。正确的思路是引入中间层进行缓冲与异步化处理,实现“削峰填谷”。

核心策略是让消息队列(MQ)充当“蓄水池”,具体流程如下:
- 用户上报:移动端App将步数数据上报至后端业务服务。
- 快速转发:业务服务层收到请求后,不进行任何业务计算,也不直接写入数据库。其核心职责是校验基础参数后,将
{userId, steps, timestamp} 格式的消息以最快速度投递至 Kafka 或 RocketMQ 等消息中间件中,随即向客户端返回成功响应。这一步至关重要,它保证了接口的高吞吐与低延迟。
- 异步消费:独立的消费服务订阅MQ中的消息,可以按照自身处理能力,从容不迫地进行消费,避免了上游流量的直接冲击。
- 数据落地:消费服务处理消息,执行关键操作——使用Redis的Sorted Set(ZSET)数据结构来存储实时排行榜。例如,更新用户A今日的步数:
# 将用户A的步数更新到名为“leaderboard:2025-09-12”的排行榜中
ZADD leaderboard:2025-09-12 15000 user_id_A
ZADD 命令是构建排行榜的利器,它会自动更新用户分数(步数),其时间复杂度为 O(logN),在数据量极大时依然能保持高效。
方案小结:通过引入MQ,我们将瞬时的海量同步写入请求转化为异步的、平滑的数据流。业务接口响应迅捷,后端数据处理压力可控,实现了写入环节的高性能与高可用。想深入研究这类高并发架构,可以前往云栈社区的「后端 & 架构」板块查看更多讨论。
核心方案二:查询流程 — “动静分离与内存计算”
写入问题解决后,如何实现好友排行榜的毫秒级查询?关键在于动静分离。
- “静”指关系:用户的好友列表相对稳定,变化频率低。
- “动”指数据:用户的步数时刻可能变化,是高度动态的。
我们将这两类数据分开存储与查询,流程如下图所示:
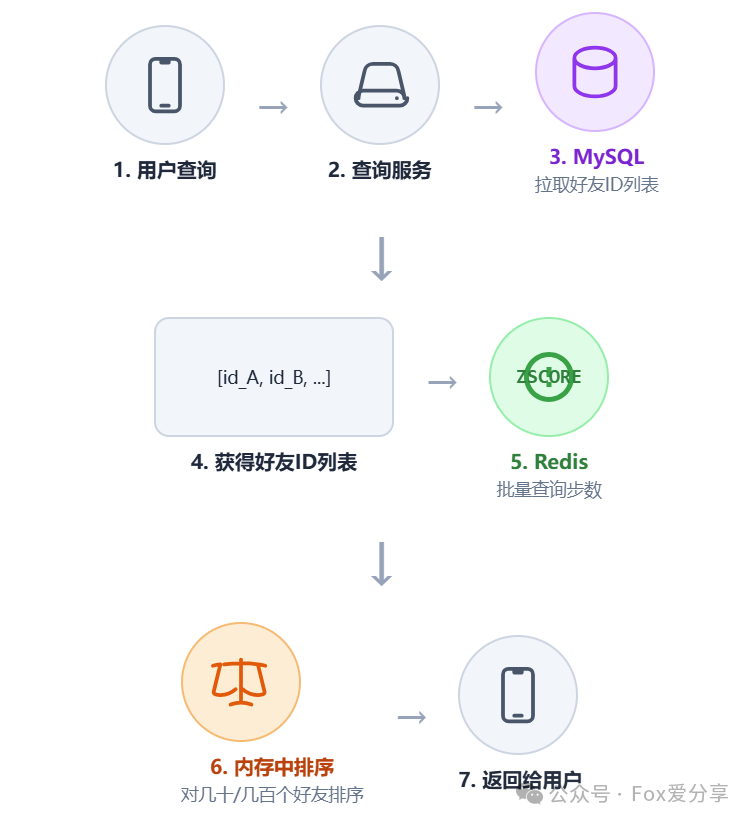
具体查询步骤如下:
- 拉取静态关系:当用户A查询排行榜时,服务首先从其持久化存储(如做了分库分表的MySQL)中获取他的好友ID列表。这部分数据对一致性要求高,适合用关系型数据库存储。
- 批量获取动态分数:获得好友ID列表(假设有200个)后,应避免使用循环多次查询Redis。最佳实践是采用Redis的
Pipeline 或通过多线程并发,一次性批量获取所有好友在对应ZSET中的分数(步数)。
- 内存快速排序:此时,服务端内存中已持有一个几百条记录的小数据集。在应用内存中对这个小集合进行排序(如快速排序),速度极快,开销极小。
- 组装返回:将排序后的列表,结合用户的昵称、头像等(这些信息可前置缓存)组装成最终结果,返回给前端。
方案小结:该方案将一次复杂的多表关联排序查询,拆解为一次关系查询、一次批量缓存查询和一次内存计算。动静分离,各司其职,最终实现了查询的极速响应。这里用到的 Redis 正是处理此类实时热数据的绝佳选择,关于它的更多高级用法,可以在数据库/中间件/技术栈板块找到丰富资料。
核心方案三:应对深入追问 — “完善架构的健壮性”
掌握上述核心设计,已能应对大部分考察。但要获得顶级评价,还需准备好回答面试官的进阶追问,展现架构的完整性。
追问一:“对于拥有数百万粉丝的‘大V’用户,实时查询其好友排行榜,步骤二中的批量查询和内存排序是否会导致服务超时或卡死?”
回答:这是一个典型的“热点用户”或“大Key”问题。对于此类特殊用户,应采用 “预计算 + 缓存” 的降级方案。
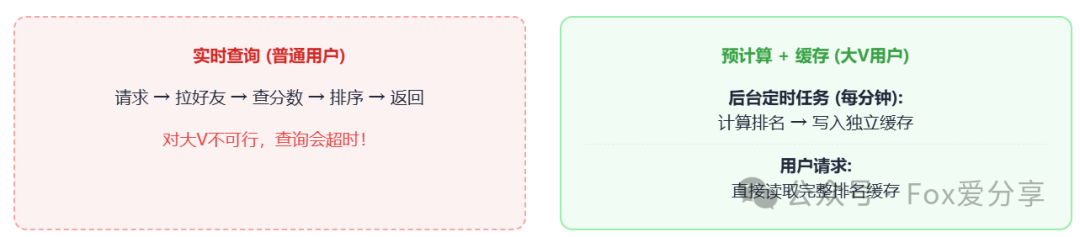
如上图右侧方案所示,系统会为这些大V用户启动一个独立的后台定时任务(例如每分钟执行一次)。该任务提前计算好该大V所有好友的完整排行榜,并将排序后的结果列表(可能只存储前N名)序列化后存入一个独立的Redis Key中。当大V用户查询时,服务直接返回这份预计算好的“成品”缓存,完全绕开实时计算流程,既能保证用户体验丝滑,又能保护系统稳定性。
追问二:“Redis是内存数据库,如果整个集群故障,当天的排行榜数据是否会全部丢失?如何保证数据可靠性?”
回答:我们通过 “高可用架构” 与 “数据可恢复性” 两层保障来应对。
- 高可用:生产环境的Redis通常部署为主从(Replication)集群,并配合哨兵(Sentinel)或Redis Cluster实现自动故障转移。主节点故障时,从节点可快速升主,服务中断时间极短。
- 数据恢复:这是回溯整体设计带来的好处。请记得,所有步数上报消息都首先持久化在 消息队列(如Kafka) 中,且通常会保留1-3天。即使Redis集群完全宕机且数据无法恢复,我们也可以启动一个数据回放任务,从MQ中重新消费当天的全量步数消息,即可快速重建出整个排行榜,保证了数据的最终一致性。

总结与回顾
面对“亿级用户排行榜”这类系统设计题,一个完整的回答应涵盖以下设计要点:
- 异步解耦:引入消息队列(MQ)缓冲海量写入请求,实现流量削峰,保障接口高性能。
- 冷热分离:使用高性能内存数据库 Redis(热)存储实时变化的核心数据(如步数);使用持久化数据库MySQL(冷)存储相对静态的关系数据。
- 动静分离与计算下推:查询时,分别获取静态关系与动态数据,在应用层内存中完成最终的轻量级排序计算,避免数据库的沉重排序负担。
- 考虑边界与兜底:针对热点用户设计预计算降级方案;通过高可用集群与上游数据源(MQ)保障系统可用性与数据可恢复性。
这套设计方案层次清晰,充分考虑了大流量场景下的性能、可用性与成本,能够充分展现候选人在系统架构方面的专业性与经验。如果你正在准备类似的面试求职挑战,透彻理解此类经典问题的设计思路至关重要。
 发表于 2026-3-3 12:04:32
|
查看: 177|
回复: 0
发表于 2026-3-3 12:04:32
|
查看: 177|
回复: 0
